


The Llama 4 API is a powerful interface that allows developers to integrate Meta‘s latest multimodal large language models, enabling advanced text, image, and video processing capabilities across various applications.

Overview of the Llama 4 Series
Meta’s Llama 4 series introduces cutting-edge AI models designed to process and translate various data formats, including text, video, images, and audio, thereby enhancing versatility across applications. The series includes:
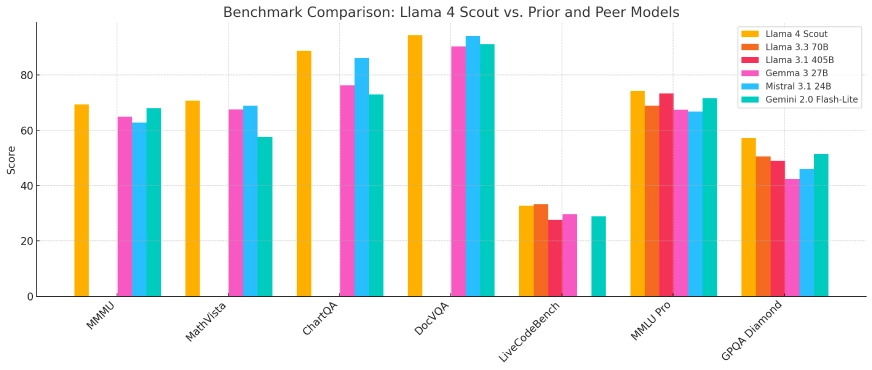
- Llama 4 Scout: A compact model optimized for deployment on a single Nvidia H100 GPU, featuring a 10-million-token context window. It outperforms competitors such as Google’s Gemma 3 and Mistral 3.1 across various benchmarks.
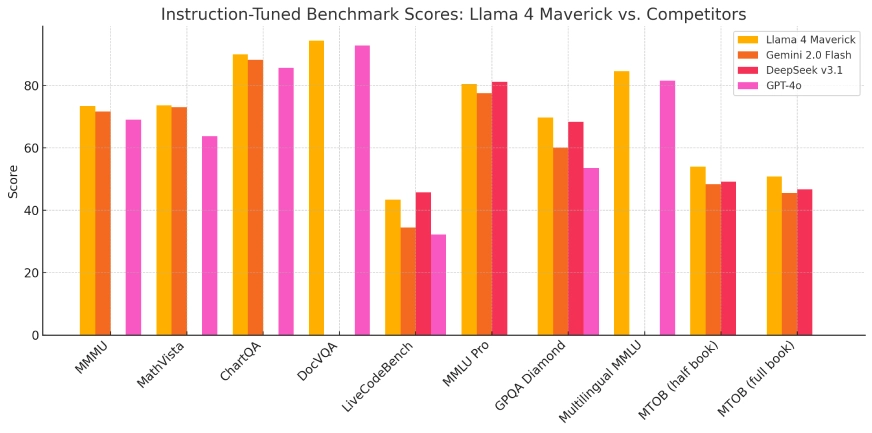
- Llama 4 Maverick: A larger model comparable in performance to OpenAI’s GPT-4o and DeepSeek-V3 in coding and reasoning tasks, while utilizing fewer active parameters.
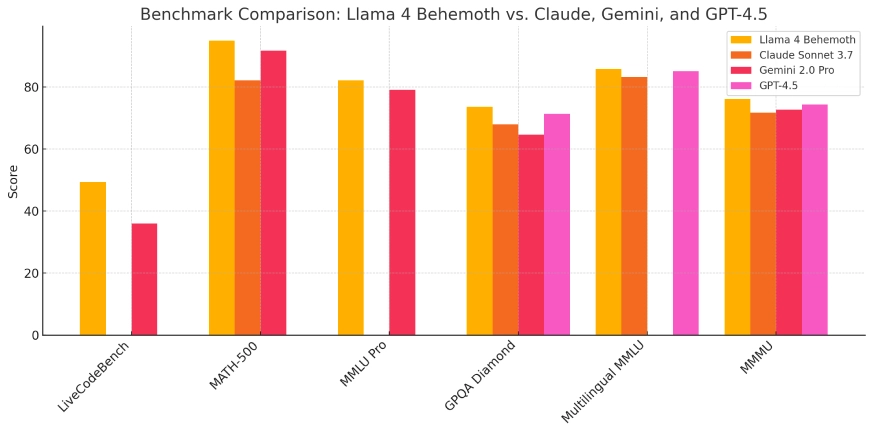
- Llama 4 Behemoth: Currently in development, this model boasts 288 billion active parameters and a total of 2 trillion, aiming to surpass models like GPT-4.5 and Claude Sonnet 3.7 on STEM benchmarks.
These models are integrated into Meta’s AI assistant across platforms such as WhatsApp, Messenger, Instagram, and the web, enhancing user interactions with advanced AI capabilities.
| Model | Total Parameters | Active Parameters | Experts | Context Length | Runs On | Public Access | Ideal For |
|---|---|---|---|---|---|---|---|
| Scout | 109B | 17B | 16 | 10M tokens | Single Nvidia H100 | ✅ Yes | Lightweight AI tasks, long-context apps |
| Maverick | 400B | 17B | 128 | Not specified | Single or Multi-GPU | ✅ Yes | Research, enterprise applications, coding |
| Behemoth | ~2T | 288B | 16 | Not specified | Meta internal infra | ❌ No | Internal model training and benchmarking |
Technical Architecture and Innovations
The Llama 4 series employs a “mixture of experts” (MoE) architecture, an innovative approach that optimizes resource utilization by activating only relevant subsets of the model’s parameters during specific tasks. This design enhances computational efficiency and performance, allowing the models to handle complex tasks more effectively.
Training these models required substantial computational resources. Meta utilized a GPU cluster comprising over 100,000 Nvidia H100 chips, representing one of the largest AI training infrastructures to date. This extensive computational power facilitated the development of models with enhanced capabilities and performance metrics.
Evolution from Previous Models
Building upon the foundation laid by earlier iterations, the Llama 4 series represents a significant evolution in Meta’s AI model development. The integration of multimodal processing capabilities and the adoption of the MoE architecture address limitations observed in previous models, such as challenges in reasoning and mathematical tasks. These advancements position Llama 4 as a formidable competitor in the AI landscape.
Benchmark Performance and Technical Indicators
In benchmark evaluations, Llama 4 Scout demonstrated superior performance over models like Google’s Gemma 3 and Mistral 3.1, particularly in tasks requiring extensive context processing. Llama 4 Maverick exhibited capabilities on par with leading models such as OpenAI’s GPT-4o, especially in coding and reasoning tasks, while maintaining a more efficient parameter utilization. These results underscore the effectiveness of the MoE architecture and the extensive training regimen employed.
Llama 4 Scout
Llama 4 Maverick
Llama 4 Behemoth:
Application Scenarios
The versatility of the Llama 4 series enables its application across various domains:
- Social Media Integration: Enhancing user interactions on platforms like WhatsApp, Messenger, and Instagram through advanced AI-driven features, including improved content recommendations and conversational agents.
- Content Creation: Assisting creators in generating high-quality, multimodal content by processing and synthesizing text, images, and videos, thereby streamlining the creative process.
- Educational Tools: Facilitating the development of intelligent tutoring systems that can interpret and respond to various data formats, providing a more immersive learning experience.
- Business Analytics: Enabling enterprises to analyze and interpret complex datasets, including textual and visual information, to derive actionable insights and inform decision-making processes.
The integration of the Llama 4 models into Meta’s platforms exemplifies their practical utility and potential to enhance user experiences across diverse applications.
Ethical Considerations and Open-Source Strategy
While Meta promotes the Llama 4 series as open-source, the licensing terms include restrictions for commercial entities with over 700 million users. This approach has elicited criticism from the Open Source Initiative, highlighting the ongoing debate regarding the balance between open access and commercial interests in AI development.
Meta’s substantial investment, reportedly up to $65 billion in AI infrastructure, underscores the company’s commitment to advancing AI capabilities and maintaining a competitive edge in the rapidly evolving AI landscape.
Conclusion
The introduction of Meta’s Llama 4 series marks a pivotal advancement in artificial intelligence, showcasing significant improvements in multimodal processing, efficiency, and performance. Through innovative architectural designs and substantial computational investments, these models set new benchmarks in AI capabilities. As Meta continues to integrate these models across its platforms and explore further developments, the Llama 4 series is poised to play a crucial role in shaping the future trajectory of AI applications and services.
How to call Llama 4 API from CometAPI
1.Log in to cometapi.com. If you are not our user yet, please register first
2.Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
3. Get the url of this site: https://api.cometapi.com/
4. Select the Llama 4 (Model name: llama-4-maverick; llama-4-scout) endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
- For Model lunched information in Comet API please see https://api.cometapi.com/new-model.
- For Model Price information in Comet API please see https://api.cometapi.com/pricing
| Category | llama-4-maverick | llama-4-scout |
| API Pricing | Input Tokens: $0.48 / M tokens | Input Tokens: $0.216 / M tokens |
| Output Tokens: $1.44/ M tokens | Output Tokens: $1.152/ M tokens |
5. Process the API response to get the generated answer. After sending the API request, you will receive a JSON object containing the generated completion.
