


The model “Kimi K2 Thinking” is a new reasoning-agent variant developed by Moonshot AI (Beijing). It belongs to the broader “Kimi K2” family of large-language models but is specifically tuned for thinking—i.e., long-horizon reasoning, tool usage, planning and multi-step inference. Version are kimi-k2-thinking-turbo,kimi-k2-thinking.
Basic Features
- Large-scale parameterisation: Kimi K2 Thinking is built atop the K2 series, which uses a mixture-of-experts (MoE) architecture with around 1 trillion (1 T) total parameters and about 32 billion (32 B) activated parameters at inference time.
- Context length & tool-use: The model supports very long context windows (reports indicate up to 256K tokens) and is designed to perform sequential tool calls (up to 200-300) without human intervention.
- Agentic behaviour: It is tailored for being an “agent” rather than simply a conversational LLM — meaning it can plan, call external tools (search, code execution, web retrieval), maintain reasoning traces, and orchestrate complex workflows.
- Open weight & licence: The model is released under a modified MIT licence, which permits commercial/derivative use but includes an attribution clause for large-scale deployments.
Technical Details
Architecture:
- MoE (Mixture-of-Experts) backbone.
- Total parameters: ≈ 1 trillion. Active parameters per inference: ≈ 32 billion.
- Number of experts: ~384, selected per token: ~8.
- Vocabulary & context: Vocabulary size about 160K, context windows up to latest 256K tokens.
Training / optimisation:
- Pre-trained on ~15.5 trillion tokens.
- Optimiser used: “Muon” or variant (MuonClip) to address training instability at scale.
- Post-training / fine-tuning: Multi-stage, including agentic data synthesis, reinforcement learning, tool-call training.
Inference & tool-use:
- Supports hundreds of sequential tool calls, enabling chained reasoning workflows.
- Claims of native INT4 quantised inference to reduce memory usage and latency without large accuracy drops, test-time scaling, extended context windows.
Benchmark performance
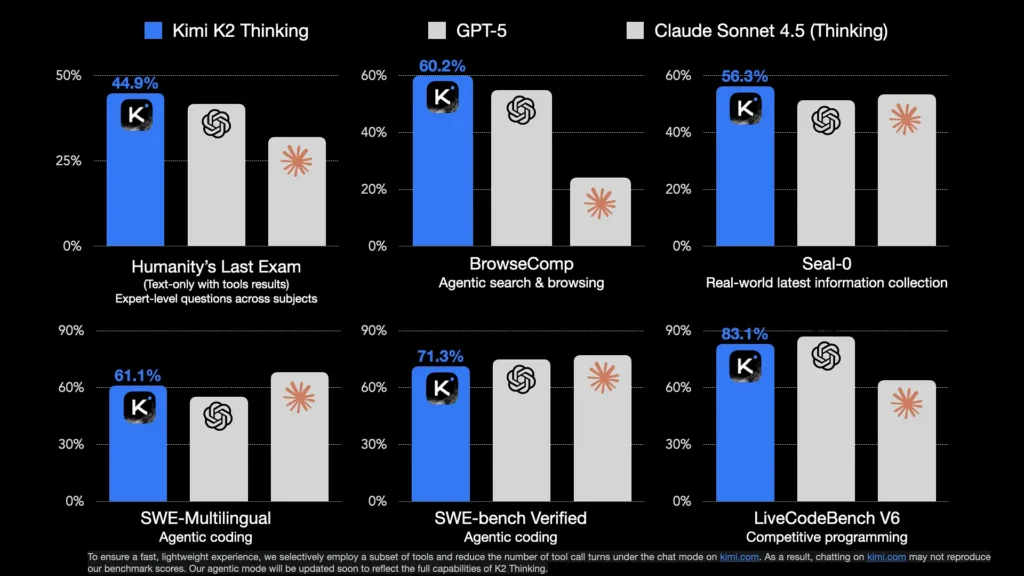
Benchmarks: Moonshot’s published numbers show strong results on agentic and reasoning suites: for example 44.9% on Humanity’s Last Exam (HLE) with tools, 60.2% on BrowseComp, and high marks on domain suites such as SWE-Bench / SWE-Bench Verified and AIME25 (math).
Limitations & risks
- Compute & deployment: despite 32B activation equivalence, operational costs and engineering to host Thinking reliably (long contexts, tool orchestration, quantization pipelines) remain nontrivial. Hardware requirements (GPU memory, optimized runtimes) and inference engineering are real constraints.
- Behavioral risks: like other LLMs, Kimi K2 Thinking can hallucinate facts, reflect dataset biases, or produce unsafe content without appropriate guardrails. Its agentic autonomy (automated multi-step tool calls) increases the importance of safety-by-design: strict tool permissioning, runtime checks, and human-in-the-loop policies are recommended.
- Comparative edge vs closed models: While the model matches or surpasses many benchmarks, in some domains or “heavy mode” configurations closed models may still retain advantages.
Comparison with Other Models
- Compared to GPT-5 and Claude Sonnet 4.5: Kimi K2 Thinking claims superior scores on some major benchmarks (e.g., agentic search, reasoning) despite being open-weight.
- Compared to prior open-source models: It exceeds earlier open-models such as MiniMax‑M2 and others in agentic reasoning metrics and tool-call capability.
- Architectural distinction: Sparse MoE with high active parameter count vs many dense models or smaller-scale systems; focus on long-horizon reasoning, chain-of-thought and multi-tool orchestration rather than pure text generation.
- Cost & licence advantage: Open-weight, more permissive licence (with attribution clause) offers potential cost savings vs closed APIs, though infrastructure cost remains.
Use Cases
Kimi K2 Thinking is particularly suited for scenarios requiring:
- Long-horizon reasoning workflows: e.g., planning, multi-step problem solving, project breakdowns.
- Agentic tool orchestration: web search + code execution + data retrieval + writing summarisation in one workflow.
- Coding, mathematics and technical tasks: Given its benchmark strength in LiveCodeBench, SWE-Bench, etc., good candidate for developer assistant, code generation, automated data analysis.
- Enterprise automation workflows: Where multiple tools need to be chained (e.g., fetch data → analyse → write report → alert) with minimal human mediation.
- Research and open-source projects: Given the open weight, academic or research deployment is viable for experimentation and fine-tuning.
How to call Kimi K2 Thinking API from CometAPI
Kimi K2 Thinking API Pricing in CometAPI,20% off the official price:
| Model | Input Tokens | Output Tokens |
|---|---|---|
| kimi-k2-thinking-turbo | $2.20 | $15.95 |
| kimi-k2-thinking | $1.10 | $4.40 |
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first.
- Sign into your CometAPI console.
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.

Use Method
- Select the “kimi-k2-thinking-turbo,kimi-k2-thinking” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
- Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
CometAPI provides a fully compatible REST API—for seamless migration. Key details to API doc:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: kimi-k2-thinking-turbo,kimi-k2-thinking
- Authentication:
Bearer YOUR_CometAPI_API_KEYheader - Content-Type:
application/json.


