
Kling O1: the new “unified” multimodal video model — what it is and how to work

Kling O1 — released as part of Kling AI’s “Omni” launch week — positions itself as a single, unified multimodal video foundation model that accepts text, images and videos in the same request and can both generate and edit video in director-level, iterative workflows. Kling’s team bills O1 as the “world’s first unified multimodal video large-scale model.” Kling’s internal tests claim sizable wins versus Google’s Veo 3.1 and Runway Aleph.
What is Kling O1?
Kling O1 (often marketed as Video O1 or Omni One) is a newly released video foundation model from Kling AI that unifies generation and editing across text, images, and video inside a single, prompt-driven framework. Rather than treating text-to-video, image-to-video, and video-editing as separate pipelines, Kling O1 accepts mixed inputs (text + multiple images + optional reference video) in a single prompt, reasons over them, and produces coherent short-clips or edits existing footage with fine-grained control. The company positioned the rollout as part of an “Omni Launch” and describes O1 as a “multimodal video engine” built around a Multimodal Visual Language (MVL) paradigm and a Chain-of-Thought (CoT) reasoning pathway to interpret complex, multi-part creative instructions.
Kling’s messaging emphasizes three practical workflows: (1) text → video generation, (2) image/element → video (compositing and subject/prop swaps using explicit references), and (3) video editing/shot continuation (restyling, object add/remove, start-frame/end-frame control). The model supports multi-element prompts (including an “@” syntax for targeting particular reference images) and features director-style controls such as start/end frame anchoring and video continuation to build multi-shot sequences.
5 core highlights of Kling O1
1) True unified multimodal input (MVL)
Kling O1’s flagship capability is treating text, still images (multiple references), and video as first-class, simultaneous inputs. Users can supply several reference images (or a short reference clip) and a natural-language instruction; the model will parse all inputs together to produce or edit a coherent output. This reduces tool-chain friction and enables workflows like “use subject from @image1, place them in the environment from @image2, match motion to ref_video.mp4, and apply cinematic color grade X.” This “Multimodal Visual Language” (MVL) framing is core to Kling’s pitch.
Why it matters: real creative workflows often require combining references: a character from one asset, a camera move from another, and a narrative instruction in text. Unifying these inputs enables one-pass generation and fewer manual comp steps.
2) Editing + generation in one model (multi-elements mode)
Most prior systems separated generation (text→video) from frame-accurate editing. O1 intentionally combines them: the same model that creates a clip from scratch can also edit existing footage — swapping objects, restyling clothing, removing props, or extending a shot — all via natural-language instructions. That convergence is a major workflow simplifier for production teams.
The O1 model achieves deep integration of multiple video tasks at its core:
- Text-to-Video generation
- Image/Subject reference generation
- Video editing & inpainting
- Video restyle
- Next/Previous Shot Generation
- Keyframe-Constrained Video Generation
The greatest significance of this design lies in: Complex processes that previously required multiple models or independent tools can now be completed within a single engine. This not only significantly reduces creation and computational costs but also lays the foundation for the development of a “unified video understanding and generation model.”
3) The coherence of video generation
Identity consistency: The O1 model enhances cross-modal consistency modeling capabilities, maintaining the stability of the reference subject’s structure, material, lighting, and style during the generation process:
- It supports multi-view reference images for subject modeling;
- it supports cross-shot subject consistency (character, object, and scene features remain continuous across different shots);
- it supports multi-subject hybrid references, enabling group portrait generation and interactive scene construction.
This mechanism significantly improves the coherence and “identity consistency” of video generation, making it suitable for scenarios with extremely high consistency requirements, such as advertising and film-level shot generation.
Improved memory: The O1 model also possesses “memory,” preventing its output style from becoming unstable due to lengthy contexts or changing instructions. It can even:
- remember multiple characters simultaneously;
- allow different characters to interact in the video;
- maintain consistency in style, clothing, and posture.
4) Precise compositing with “@” syntax and start/end frame control
Kling introduced a compositing shorthand (reported as an “@” mention system) so you can reference specific images in the prompt (e.g., @image1, @image2) to assign roles to assets reliably. Combined with explicit Start + End frame specification, this enables director-level control over how elements transition, move, or morph across the generated clip — a production-focused feature set that differentiates O1 from many consumer-oriented generators.
5) High-fidelity, long-ish outputs and multi-task stacking
Kling O1 is reported to produce cinematic 1080p outputs (30fps) and — with prior Kling versions setting the stage — the company touts generation of longer clips (reporting up to 2 minutes in recent product writeups). It also supports stacking multiple creative tasks in a single request (generate, add a subject, change lighting, and edit composition). Those properties make it competitive with the higher-tier text→video engines.
Why it matters: longer, high-fidelity clips and the ability to combine edits reduce the need for stitching many short clips together and simplify end-to-end production.
How is Kling O1 architected and what are the underlying mechanisms?
O1 around a Multimodal Visual Language (MVL) core: a model that learns joint embeddings for language + images + motion signals (video frames and optical-flow-style features), and then applies diffusion or transformer-based decoders to synthesize temporally coherent frames. The model is described as performing conditioning on multiple references (text; one-to-many images; short video clips) to produce a latent video representation which is then decoded into per-frame images while preserving temporal consistency via cross-frame attention or specialized temporal modules.
1. Multimodal Transformer + Long Context Architecture
The O1 model employs Keling’s self-developed multimodal Transformer architecture, integrating text, image, and video signals, and supporting long temporal context memory (Multimodal Long Context).
This enables the model to understand temporal continuity and spatial consistency during video generation.
2. MVL: Multimodal Visual Language
MVL is the core innovation of this architecture.
It deeply aligns language and visual signals within the Transformer through a unified semantic intermediate layer, thereby:
- Allowing a single input box to mix multimodal instructions;
- Improving the model’s accurate understanding of natural language descriptions;
- Supporting highly flexible interactive video generation.
The introduction of MVL marks a shift in video generation from “text-driven” to “semantic-visual co-driven.”
3. Chain-of-Thought Inference Mechanism
The O1 model introduces a “Chain-of-Thought” inference path during the video generation stage.
This mechanism allows the model to perform event logic and timing deduction before generation, thus maintaining a natural connection between actions and events within the video.
Inference and edit pipelines
- Generation: feed: (text + optional image refs + optional video refs + generation settings) → model produces latent video frames → decode to frames → optional color/temporal post-processing.
- Instruction-based editing: feed: (original video + text instruction + optional image refs) → model internally maps the requested edit to a set of pixel-space transformations and then synthesizes edited frames while preserving unchanged content. Because everything is in one model, the same conditioning and temporal modules are used for both creation and edit.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
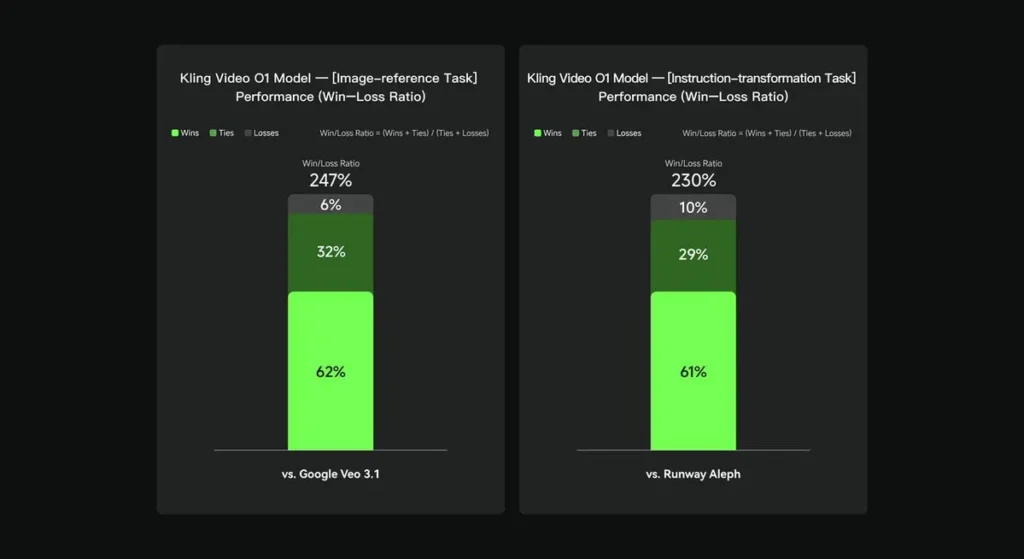
In internal evaluations, Keling Video O1 significantly outperformed existing international counterparts across several key dimensions. Performance Results (based on Keling AI’s self-built evaluation set):
- “Image Reference” Task: O1 outperforms Google Veo 3.1 overall, with a win rate of 247%;
- “Instruction Transformation” Task: O1 outperforms Runway Aleph, with a win rate of 230%.
Competitor snapshot (feature-level comparison)
| Capability / Model | Kling O1 | Google Veo 3.1 | Runway (Aleph / Gen-4.5) |
|---|---|---|---|
| Unified multimodal prompt (text+images+video) | Yes (core selling point). single-request multimodal flows. | Partial — text→video + references exist; less emphasis on single unified MVL. | Runway focuses on generation + editing but often as separate modes; latest Gen-4.5 narrows the gap. |
| Conversational / text-based pixel edits | Yes — “edit like a conversation” (no masks). | Partial — editing exists but mask/keyframe workflows still common. | Runway has strong edit tooling; Runway claims strong instruction transforms (varies by release). |
| Start / end frame control & camera reference | Yes — explicit start/end frame and reference camera moves described. | Limited / evolving | Runway: improving controls; not exactly same UX. |
| Long clip generation (high fidelity) | up to ~2 minutes (1080p, 30fps) in product materials and community posts; | Veo 3.1: strong coherence but earlier versions had shorter defaults; varies with model/setting. | Runway Gen-4.5: aims high on quality; length/fidelity varies. |
Conclusion:
Kling O1’s public claim to fame is workflow unification: giving a single model the mandate to understand text, images and video and to perform both generation and rich instruction-based editing inside the same semantic system. For creators and teams who frequently move between “create”, “edit” and “extend” steps, that consolidation can dramatically simplify iteration speed and tooling complexity. Improved temporal consistency, start/end frame control, and pragmatic platform integrations that make it accessible to creators.
The Kling Video o1 API will soon be available on CometAPI.
Developers can access Kling 2.5 Turb and Veo 3.1 API through CometAPI, the latest models listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!