

دفعت Google وذراعها البحثي DeepMind بهدوء (ثم بوضوح أكبر) خطوة كبرى أخرى على خارطة طريق Gemini: Gemini 3.1 Pro. الإصدار، الذي طُرح عبر الواجهات الموجهة للمستهلكين وCometAPI، يتموضع كترقية في الأداء والاستدلال لعائلة Gemini 3 — واعدًا بتحسين ملحوظ في الاستدلال طويل المدى، وفهمٍ أفضل متعدد الوسائط، وقابلية توسّع أعلى للتطبيقات الواقعية.
أحدث نموذج من Google — ما هو Gemini 3.1 Pro؟
Gemini 3.1 Pro هو أول تحديث تدريجي ضمن عائلة Gemini 3 يتموضع كأكثر نماذج الاستدلال "قدرةً"، ومُحسّن للمهام متعددة الخطوات، ومتعددة الوسائط، والمهام العاملية (agentic). طُرح للمعاينة العامة في منتصف فبراير 2026 (أُعلنت المعاينة في 19–20 فبراير 2026)، ويستهدف صراحةً السيناريوهات التي تتطلب سلاسل تفكير مستدامة، واستخدام الأدوات، وفهم السياق الطويل — على سبيل المثال: توليف أبحاث واسعة النطاق، ووكلاء هندسيون ينسّقون الأدوات والأنظمة، وتحليل متعدد الوسائط لمستندات تمزج النصوص والصور والصوت والفيديو.
على مستوى عالٍ، يصف المطوّرون Gemini 3.1 Pro بأنه:
- متعدد الوسائط أصالةً — قادر على استقبال النصوص والصور والصوت والفيديو والاستدلال عليها.
- مُصمَّم للسياق الطويل — يدعم نوافذ سياق ضخمة مناسبة لقواعد شفرات كاملة، أو ملفات متعددة، أو محاضر طويلة.
- مُحسَّن لـالاستدلال الموثوق وتدفقات العمل العاملية، أي مُعدّ للتخطيط، واستدعاء الأدوات، والتحقق من المخرجات عبر مهام متعددة الخطوات.
لماذا هذا مهم الآن: تنتقل المنظمات والمطوّرون من "مساعدين حواريين جيدين" إلى "وكلاء دعم قرار وبحث عالية المخاطر" (صياغة قانونية، توليف R&D، فهم مستندات متعددة الوسائط). صُمّم Gemini 3.1 Pro صراحةً لهذا المسار — لتقليل الهلوسات، وإنتاج استدلال يمكن تتبعه، والاندماج مع CometAPI لأغراض النمذجة الأولية والإنتاج.
ما أبرز الجوانب التقنية وميزات Gemini 3.1 Pro؟
التعددية الأصيلة للوسائط ونوافذ سياق فائقة الاتساع
يواصل Gemini 3.1 Pro تركيز سلالة Gemini على التعددية الوسائط. وفقًا لبطاقة النموذج وملاحظات المنتج، يستقبل النموذج ويستدل على النصوص والصور والصوت والفيديو في خط أنابيب واحد — وهي قدرة تُبسّط سير العمل حين تختلط أنواع البيانات (مثلًا: إفادات قانونية تحتوي على صوت + نسخة نصية + مسوحات ضوئية). ومن اللافت أن النموذج يدعم نافذة سياق بحجم 1,000,000 رمز ويستطيع إنتاج مخرجات طويلة (تشير الملاحظات المنشورة إلى حدود مخرجات كبيرة جدًا مناسبة للمهام الطويلة). يتيح هذا الحجم حالات استخدام مثل تحليل مستودعات شيفرة كاملة، ومستندات متعددة الفصول، أو محاضر طويلة دون تجزئة.
"التفكير الديناميكي": استدلال مُحسّن وتخطيط خطوي
تصف Google الإصدار 3.1 Pro بأنه يمتلك "تفكيرًا" محسّنًا — أي معالجة أفضل لسلاسل التفكير الداخلية واختيارًا ديناميكيًا لاستراتيجيات الاستدلال بحسب تعقيد المهمة. جرى ضبط النموذج للانخراط في تخطيط صريح متعدد الخطوات عند الحاجة، وأن يكون كفؤًا من حيث الرموز أثناء ذلك. عمليًا، يترجم هذا إلى هلاوس أقل في المسائل المعقدة المتسلسلة، واتساق واقعي محسّن على مقاييس الاستدلال متعددة الخطوات.
تدفقات العمل العاملية واستخدام الأدوات
ركز التصميم في 3.1 Pro بشكل كبير على الأداء العاملـي: تنسيق الأدوات، واستدعاء الإسناد إلى الويب أو البحث، وكتابة وتنفيذ مقتطفات الشيفرة، والتحقق من المخرجات عبر تمريرات ثانوية. دمجت Google 3.1 Pro في منتجات تُعطي الأولوية للوكلاء (مثل بيئة التطوير Antigravity) لتمكين النماذج من تنفيذ مهام تشمل محررًا وطرفية ومتصفحًا — وتسجيل أصول مثل لقطات الشاشة وتسجيلات المتصفح للتحقق من التقدّم. تهدف هذه الميزات إلى تضييق الفجوة بين النماذج "التي تُقدّم النصائح" وتلك التي تُنفّذ تدفقات عمل متعددة الأدوات بشكل موثوق.
الأنماط الفرعية المتخصصة (Deep Research, Deep Think)
تقترن Google بالإصدار 3.1 Pro مع "Deep Research" وتشير إلى متغير قادم "Deep Think". تستهدف هذه الأنماط الفرعية — على التوالي — مهام البحث عالية الاسترجاع وأقصى عمق استدلال (بكلفة وكمون أعلى). صُممت لخدمة المحللين والباحثين والمطورين الذين يحتاجون إلى مخرجات أكثر تروّيًا وجودة بدلًا من أسرع الاستجابات وأرخصها.
كيف يؤدّي Gemini 3.1 Pro على المقاييس القياسية؟
يحقق Gemini 3.1 Pro مكاسب قوية على نتائج Gemini 3 Pro السابقة، وغالبًا ما يتقدم على مجموعة واسعة من مقاييس الاستدلال متعدد الخطوات ومتعدد الوسائط — لكنه يتأخر عن بعض المنافسين في مهام متخصصة محددة (لا سيما ترميزات متقدمة معينة أو مجموعات أسئلة على مستوى الخبراء). باختصار: تحسينات واسعة مع تفوق منافسين بشكل ضيق في معايير تخصصية.
أبرز الادعاءات والنتائج الرقمية
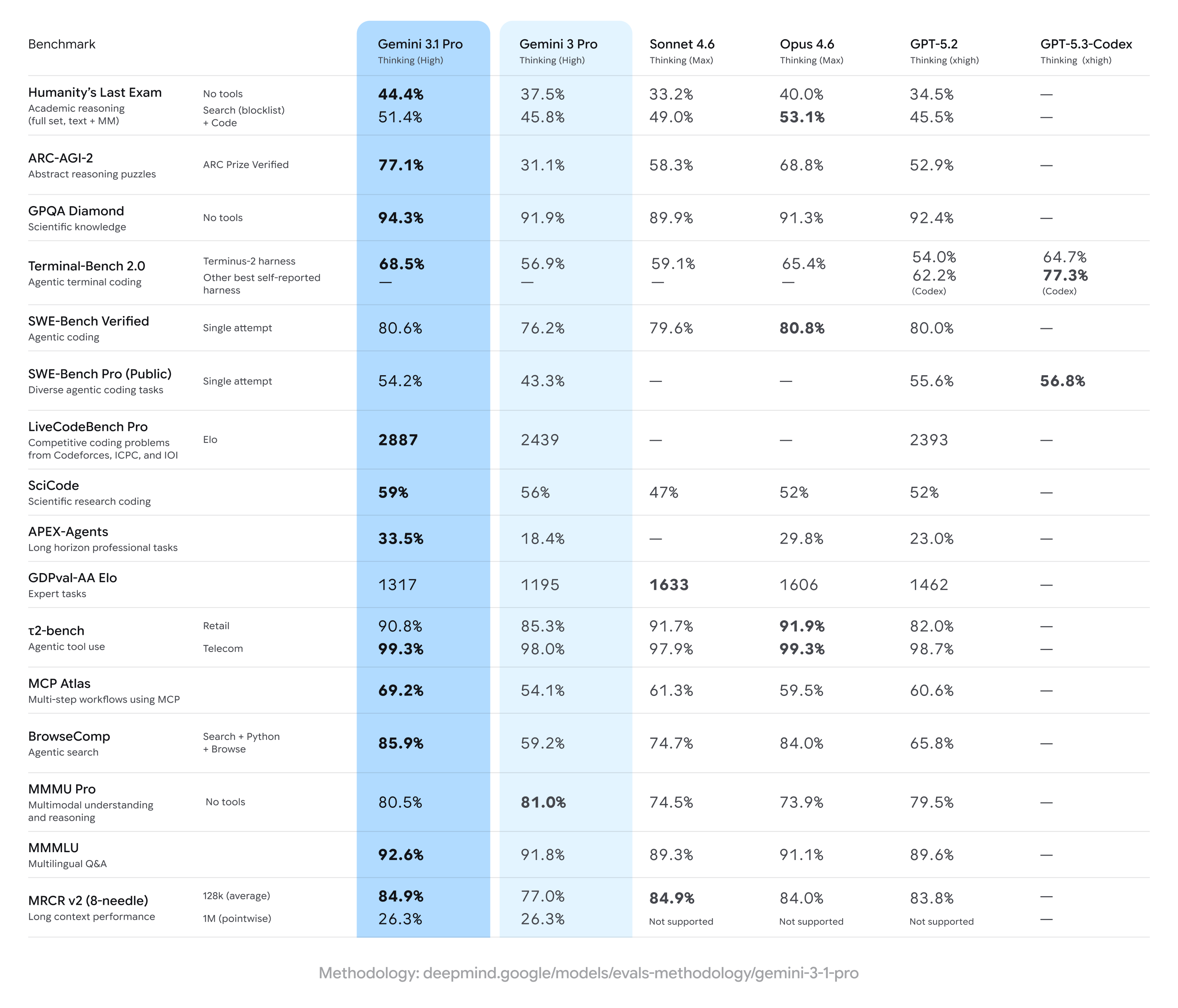
- ARC-AGI-2 (استدلال مجرد/ألغاز علوم متعددة الخطوات): تظهر الزيادات المبلغ عنها لـGemini 3.1 Pro تحسنًا كبيرًا عن إصدارات Gemini 3 Pro السابقة؛ أشارت إحدى حزم الاختبارات المجتمعية إلى تحسّن يفوق الضعف على ARC-AGI-2 مقارنة بخط الأساس السابق لـGemini 3 Pro في اختبارات قصيرة ومركزة. تضع الدرجات المحددة المعلنة (اختبارات مجتمعية) Gemini 3.1 Pro عند نحو ~77.1% على بعض تجميعات أسلوب ARC (تقرير علني).
- GPQA Diamond ومعايير علوم على مستوى الدراسات العليا: تشير البيانات إلى أن Gemini 3.1 Pro حقق أرقامًا قياسية على GPQA Diamond (مرجع أسئلة علوم على مستوى الدراسات العليا)، متجاوزًا النماذج السابقة من Gemini ومحددًا مستوى مرتفعًا جديدًا للعائلة في تشغيلات مستقلة. تعكس هذه المكاسب تحسين ضبط سلسلة التفكير والاستدلال الخطي خطوة بخطوة.
- "Humanity’s Last Exam" مع تمكين الأدوات (استدلال متعدد الأدوات مع إسناد): في مقارنات مباشرة مع Claude Opus 4.6 من Anthropic، حقق Claude 53.1% على هذا المرجع المعقد متعدد الأدوات بينما وصل Gemini 3.1 Pro إلى 51.4% في نفس جولة الاختبار — ما يُظهر تقارب Gemini مع القمة لكنه ليس الأول في ذلك الامتحان متعدد الأدوات تحديدًا.
- اختبارات البرمجة والطرفية (Terminal-Bench 2.0, SWE-Bench Pro): أظهرت معايير الترميز المتخصص تباينًا أكبر. على Terminal-Bench 2.0 مع تجهيزات محددة، سجّلت متغيرات GPT-5.3-Codex حوالي 77.3% مقابل قرابة ~68.5% لـGemini 3.1 Pro في نفس المقارنات. على نتائج SWE-Bench Pro المعلنة علنًا، سجّل Gemini 3.1 Pro نحو ~54.2% مقابل 56.8% لـGPT-5.3-Codex — أقرب، لكن عائلة Codex من OpenAI احتفظت بأفضلية في المهام البرمجية المتخصصة في تلك التشغيلات.
- GDPval-AA Elo (تقييم مهام الخبراء): في ترتيب تراكمي بأسلوب Elo لمهام الخبراء، سجّلت متغيرات Claude Sonnet/Opus درجات أعلى (مثلًا ~1606–1633 نقطة) فيما وضع تقرير علني واحد Gemini 3.1 Pro عند ~1317 نقطة على نفس مجموعة البيانات — ما يشير إلى مجال للتحسن في بعض المجالات الضيقة الخاصة بالخبراء.
نتائج التجارب الواقعية والاختبارات العملية
تُظهر كتابات المحللين العمليين أن Gemini 3.1 Pro يتفوّق خصوصًا في:
- التلخيص في سياق طويل وتوليف مستندات متعددة، حيث تتجنب نافذة 1M رمز العيوب الناجمة عن التجزئة.
- مهام الفهم متعدد الوسائط التي يحسّن فيها الإسناد بين الصورة والنص من الاستخراج الواقعي للحقائق.
- الأتمتة العاملية (مثل تنسيق سلاسل أدوات بسيطة) — مع تجارب Antigravity التي تُظهر إمكانية تنسيق مهام متعددة الوكلاء مع أصول تسجل كل خطوة.
أين لا يزال Gemini 3.1 Pro متأخرًا (ما تقوله الأرقام)
لا يوجد نموذج هو الأفضل على الدوام. تسلط التعليقات المستقلة واختبارات المجتمع الضوء على فجوات محددة:
- معايير هندسة البرمجيات وصيانة الشيفرة (SWE-Bench Pro وما شابه) — يتأخر Gemini 3.1 Pro عن منافس (Claude Opus 4.6 من Anthropic) في مهام تختبر قدرات هندسة البرمجيات العملية: إعادة هيكلة واسعة النطاق، فرز العيوب في قواعد شيفرة معقدة وأنواع معينة من إصلاح البرامج الآلي. بعبارة أخرى، بالنسبة لصيانة الهندسة اليومية، لا تزال النماذج المتخصصة تحتفظ بأفضلية في بعض بيئات الاختبار.
- مهام دقيقة الحساسية للكمون — لأن Gemini 3.1 Pro مضبوط للعمق، فقد تكون المهام التي تتطلب كمونًا منخفضًا للغاية ومعدل إنتاجية مرتفعًا (مثل الاستدلالات المصغرة لواجهات محادثة خفيفة) أفضل باستخدام "Flash" أو متغيرات أخرى مُحسّنة ضمن عائلة Gemini.
ما هي أسعار Gemini 3.1 Pro؟
يمكنك الوصول إلى Gemini 3.1 Pro بطريقتين — اشتراك للمستهلكين أو واجهة برمجة التطبيقات للمطورين — والأسعار تختلف لكل منهما.
- المستهلك (تطبيق Gemini / Google AI Pro): الوصول إلى Gemini 3.1 Pro مُدرج ضمن اشتراك Google AI Pro، والذي يبلغ في الولايات المتحدة $19.99 / الشهر (كما تقدم Google فئة أدنى "AI Plus" وفئة أعلى "AI Ultra"). Google.
- المطور / API (حسب الرموز): إذا استدعيت نماذج Gemini عبر واجهة مطوري Gemini/AI، تُقاس الأسعار بعدد الرموز. بالنسبة لمعاينة Gemini 3.x Pro، الأسعار المنشورة للمطورين تقريبًا: $2.00 لكل 1M من رموز الإدخال و**$12.00 لكل 1M من رموز الإخراج** للشريحة القياسية (≤200k مطالبات) — مع شرائح أعلى (مثل $4/$18 لكل 1M) للسياقات الكبيرة جدًا. (راجع جدول تسعير Gemini API للتفاصيل الكاملة وتسعير الدُفعات).
- إذا استخدمت Gemini 3.1 Pro عبر CometAPI:
| سعر Comet (USD / M Tokens) | السعر الرسمي (USD / M Tokens) |
|---|---|
| Input:$1.6/M; Output:$9.6/M | Input:$2/M; Output:$12/M |
تسعير اشتراك المستهلك (تطبيق Gemini)
بالنسبة لخطط المستخدم النهائي داخل تطبيق Gemini، تنظّم Google مستويات تتيح الوصول إلى متغيرات النماذج وميزات إضافية: Google AI Pro وGoogle AI Ultra. تختلف الأسعار حسب السوق والعملة؛ تُظهر الأمثلة المنشورة Google AI Pro بسعر $19.99/الشهر (مع تجارب ترويجية متاحة) ويتم عرض تسعير بالعملات حسب المستوى في صفحة المنتج (بما في ذلك عروض تجريبية وأسعار مخفضة قصيرة الأجل). تتضمن AI Ultra وصولًا أعلى (مثل الوصول الأولوي للابتكارات الجديدة، واعتمادات أعلى لتوليد الفيديو) بسعر شهري أعلى. تُعد أسعار هذه الخطط منافسة لاشتراكات الذكاء الاصطناعي الاستهلاكية الراقية الأخرى، ومُصممة لمنح المستخدمين المتقدمين الأفراد أو الفرق الصغيرة إمكانية الوصول إلى ميزات 3.1 Pro دون تكامل API.
نصائح عملية للمحفزات والاستخدام (ما سأفعله)
استخدم ما يلي للحصول على نتائج موثوقة وقابلة للتكرار:
- مُخطِّط خطوات صريح
نمط المحفز:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.هذا يستفيد من قدرة 3.1 Pro الأقوى على التنفيذ المتتابع ويمنحك نقاط تحقق. - مخرجات مُهيكلة وفق مخططات
اطلب JSON مع مخطط وstrict: true. لأن 3.1 Pro ينتج مخرجات طويلة ومتوافقة مع المخطط بشكل أكثر موثوقية، ستحصل على استجابات كبيرة مفردة يمكنك تحليلها لاحقًا. - "شطيرة" التحقق من الأداة
عند استدعاء أدوات خارجية (واجهات APIs، مشغلات شيفرة)، اطلب من النموذج إنتاج: خطة → نداء الأداة بالضبط (سهل النسخ/اللصق) → خطوات التحقق. ثم تحقّق من خطوات التحقق خارج النموذج قبل المتابعة. - احذر الثقة بخطوة واحدة
حتى لو كتب النموذج شيفرة أو أوامر تبدو مثالية، شغّل تحققًا مستقلًا (اختبارات، محللات، تنفيذ مُعزل) — خصوصًا للمهام العاملية/الذاتية.
تجربة عملية مع Gemini 3.1 Pro
الحالة التجريبية 1: مساعد بحث بسياق طويل (NotebookLM / Deep Research)
الهدف: تقييم قدرة النموذج على توليف 10–50 مستندًا طويلًا (مثل تقارير وأوراق بيضاء) في ملخص تنفيذي من عدة صفحات مع اقتباسات وعناصر عمل.
الإعداد: زوّد مجموعة نصية إجماليها 200k–800k رمز؛ كلف النموذج بإنتاج ملخص من 2–4 صفحات مع اقتباسات صريحة وتوصيات "الخطوة التالية". استخدم قالب محفز قابلًا للتكرار وقِس الوقت، واستخدام الرموز (الكلفة)، والدقة الواقعية.
النتائج: تلخيص أسرع طرفًا-لطرف مع عيوب تجزئة أقل مقارنة بالنماذج الأقدم، وموثوقية اقتباسات أعلى في الملخص، وتماسك أفضل على النطاق — مقابل استخدام كبير للرموز (لذا خطّط للميزانية). تُظهر المعايير والاختبارات العملية أن Gemini 3.1 Pro يتفوّق في توليف مستندات متعددة بفضل نافذة 1M رمز.
الحالة التجريبية 2: مساعد ترميز عاملي (Antigravity + GitHub Copilot)
الهدف: قياس تقليل زمن الإكمال لمهام المطوّرين متعددة الخطوات (مثل تنفيذ ميزة عبر عدة ملفات، تشغيل الاختبارات، وإصلاح الاختبارات الفاشلة).
الإعداد: استخدم Antigravity أو GitHub Copilot في المعاينة مع اختيار Gemini 3.1 Pro. حدّد مهام قابلة لإعادة الإنتاج (إنشاء قضية → تنفيذ → تشغيل الاختبارات)، سجّل الخطوات وأصول الوكيل، وقارن بخط أساس بشري فقط.
النتائج: تحسين تنسيق المهام متعددة الخطوات (تسجيل الأصول، الاقتراح التلقائي لمرشحي التصحيحات)، واستدلال أفضل عبر ملفات متعددة مقارنة بـGemini 3 Pro السابق، وتوفير زمني ملموس في أعمال الميزات الروتينية. قد تظل مهام تصحيح الأنظمة منخفضة المستوى المتخصصة مُفضّلة للنماذج المُركّزة على الشيفرة (تُظهر نتائج المجتمع فجوة مقابل بعض متغيرات GPT-Codex على معايير طرفية معينة).
الحالة التجريبية 3: مراجعة قانونية/طبية متعددة الوسائط
الهدف: استخدام النموذج لابتلاع مجموعة مختلطة (ملفات PDF ممسوحة ضوئيًا، صور، نسخ صوتية)، واستخراج الحقائق الرئيسية، وإنتاج مصفوفة مخاطر وإجراءات مُرتّبة حسب الأولوية.
الإعداد: زوّد مجموعة بيانات مع صور ممسوحة ونصوص OCR، إضافةً إلى صوت داعم. قِس الدقة في استخراج الكيانات المُسمّاة، ومعدل الإيجابيات الكاذبة، وقدرة النموذج على الإشارة إلى مصادر الأصل.
النتائج: استدلال مُتكامل أقوى عبر الوسائط ومخرجات أكثر قابلية للتتبع (القدرة على الإشارة إلى الصورة/الصفحة/الطابع الزمني للصوت الذي يدعم الادعاء). تقلّل نافذة السياق الطويل الحاجة إلى التجزئة والمراجعة اليدوية. ومع ذلك، في المجالات المنظمة، يجب التحقق من المخرجات بواسطة خبراء المجال واستخدام خط إسناد/تحقق.
الانطباعات الأولى (ما الذي يبدو مختلفًا)
- استدلال خطوي أعمق. المهام التي كانت تتطلب تفاعلات متعددة — مثل توليف مستندات، ورياضيات/منطق متعدد الخطوات — تميل إلى الاكتمال في تمريرات أقل وبمخرجات ذات أسلوب سلسلة تفكير أوضح (من دون كشف نص التعليمات الداخلي). هذا هو العنوان الذي شددت عليه Google.
- مخرجات مُهيكلة أطول وأكثر جودة. تكون JSON والأتمتة طويلة الشكل أكثر اتساقًا وغالبًا أطول بكثير (ذكر بعض المستخدمين أحجام مخرجات أكبر بكثير من 3.0). يجعل ذلك النموذج ممتازًا لمهام التوليد حيث ترغب في حمولة كبيرة واحدة. توقّع التعامل مع مخرجات أكبر وبشكل متدفق.
- كفاءة أعلى في الرموز/التعامل مع السياق. كفاءة محسّنة في الرموز، وسلوك أكثر "إسنادًا واتساقًا واقعيًا" في سيناريوهات استخدام الأدوات. يظهر ذلك في هلاوس أقل في استعلامات الحقائق القصيرة.
التحليل النهائي: هل يستحق Gemini 3.1 Pro الاعتماد الآن؟
يمثل Gemini 3.1 Pro خطوةً ذات مغزى في عائلة Gemini مع تحسينات ملموسة في الاستدلال والبرمجة والمعايير العاملية — مدعومة ببطاقة نموذج منشورة من Google ومتتبعات مستقلة تشير إلى قفزات كبيرة على لوائح محددة. بالنسبة للفرق التي تحتاج إلى استدلال متقدم، وتنسيق أدوات عاملي، أو قدرات متعددة الوسائط بسياق طويل، فإن 3.1 Pro مرشح جذاب.
يمكن للمطورين الوصول إلى Gemini 3.1 Pro عبر CometAPI الآن. للبدء، استكشف قدرات النموذج في Playground واطّلع على API guide للحصول على تعليمات مفصلة. قبل الوصول، يرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. توفّر CometAPI سعرًا أقل بكثير من السعر الرسمي لمساعدتك على الاندماج.
هل أنت مستعد؟→ سجّل للحصول على Gemini 3.1 Pro اليوم!
إذا كنت ترغب في معرفة المزيد من النصائح والإرشادات والأخبار حول الذكاء الاصطناعي، تابعنا على VK، وX، وDiscord!