

نشرت OpenAI معاينة بحثية لـ gpt-oss-safeguard، وهي عائلة من نماذج الاستدلال ذات الوزن المفتوح تم تصميمها للسماح للمطورين بفرض الخاصة بها سياسات السلامة في وقت الاستدلال. بدلًا من استخدام مُصنِّف ثابت أو مُحرِّك تعديل مُغلق، تُصمَّم النماذج الجديدة بدقة سبب من سياسة يوفرها المطوريُصدرون سلسلة أفكار (CoT) تشرح منطقهم، ويُنتجون مخرجات تصنيف مُهيكلة. أُعلن عن gpt-oss-safeguard كمعاينة بحثية، ويُقدم كزوج من نماذج التفكير المنطقي.gpt-oss-safeguard-120b و gpt-oss-safeguard-20b—تم ضبطها بدقة من عائلة gpt-oss وتم تصميمها صراحةً لأداء مهام تصنيف السلامة وإنفاذ السياسة أثناء الاستدلال.
ما هو gpt-oss-safeguard؟
gpt-oss-safeguard هو زوج من نماذج الاستدلال النصي فقط ذات الوزن المفتوح والتي تم تدريبها لاحقًا من عائلة gpt-oss إلى تفسير سياسة مكتوبة باللغة الطبيعية ووضع علامة على النص وفقًا لتلك السياسة. الميزة المميزة هي أن السياسة هي تم توفيرها في وقت الاستدلال (السياسة كمدخلات)، غير مُدمجة في أوزان التصنيف الثابتة. صُممت النماذج أساسًا لمهام تصنيف السلامة، مثل: تعديل السياسات المتعددة، وتصنيف المحتوى عبر أنظمة تنظيمية متعددة، أو التحقق من امتثال السياسات.
لماذا هذه المسائل
تعتمد أنظمة الإشراف التقليدية عادةً على (أ) مجموعات قواعد ثابتة مرتبطة بمصنفات مُدرَّبة على أمثلة مُعَلَّمة، أو (ب) أساليب استدلالية/تعبيرات نمطية لاكتشاف الكلمات المفتاحية. يحاول gpt-oss-safeguard تغيير النموذج: فبدلاً من إعادة تدريب المصنفات كلما تغيرت السياسة، تُقدِّم نص سياسة (على سبيل المثال، سياسة الاستخدام المقبول لشركتك، أو شروط خدمة المنصة، أو إرشادات الجهة التنظيمية)، ويفكِّر النموذج فيما إذا كان محتوى مُعيَّن يُخالف تلك السياسة. هذا يضمن مرونةً (تغييرات في السياسة دون إعادة تدريب) وسهولةً في التفسير (يُخرِج النموذج سلسلة استنتاجاته).
هذه هي فلسفتها الأساسية: "استبدال الحفظ بالمنطق، والتخمين بالتفسير".
يمثل هذا مرحلة جديدة في أمن المحتوى، حيث ننتقل من "تعلم القواعد بشكل سلبي" إلى "فهم القواعد بشكل نشط".
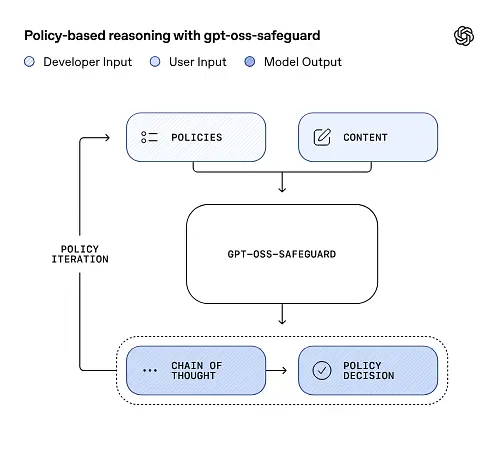
يمكن لـ gpt-oss-safeguard قراءة سياسات الأمان التي يحددها المطورون بشكل مباشر واتباع تلك السياسات لإصدار الأحكام أثناء الاستدلال.
كيف يعمل gpt-oss-safeguard؟
استدلال السياسة كمدخلات
في وقت الاستدلال، يمكنك توفير شيئين: نص السياسة و مبادئ السلوك محتوى المرشح يُعامل النموذج السياسة كتعليمات أساسية، ثم يُجري تحليلًا منطقيًا خطوة بخطوة لتحديد ما إذا كان المحتوى مسموحًا به، أو غير مسموح به، أو يتطلب خطوات تعديل إضافية. بناءً على ذلك، يقوم النموذج بما يلي:
- يُنتج مخرجات منظمة تتضمن استنتاجًا (تسمية، فئة، ثقة) وتتبعًا منطقيًا قابلًا للقراءة من قبل الإنسان يشرح سبب التوصل إلى هذا الاستنتاج.
- يستوعب السياسة والمحتوى الذي سيتم تصنيفه،
- الأسباب الداخلية من خلال بنود السياسة باستخدام خطوات تشبه سلسلة الأفكار، و
فمثلا:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
وسوف يستجيب:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
سلسلة الأفكار والمخرجات المنظمة
يمكن لـ gpt-oss-safeguard إصدار تتبع كامل لـ CoT كجزء من كل استنتاج. صُمم CoT ليكون قابلاً للفحص - حيث يمكن لفرق الامتثال معرفة سبب توصل النموذج إلى نتيجة، ويمكن للمهندسين استخدام التتبع لتشخيص غموض السياسة أو أنماط فشل النموذج. يدعم النموذج أيضًا المخرجات المنظمة—على سبيل المثال، ملف JSON يحتوي على حكم، وأقسام سياسة منتهكة، ودرجة خطورة، وإجراءات علاج مقترحة— مما يجعل من السهل دمجه في خطوط أنابيب التعديل.
مستويات "جهد التفكير" القابلة للضبط
لتحقيق التوازن بين زمن الوصول والتكلفة والشمولية، تدعم النماذج جهود التفكير القابلة للتكوين: منخفض / متوسط / مرتفعيزيد الجهد المبذول من عمق سلسلة الأفكار، وينتج عنه عمومًا استنتاجات أكثر دقة، وإن كانت أبطأ وأكثر تكلفة. يتيح هذا للمطورين فرز أعباء العمل - باستخدام جهد أقل للمحتوى الروتيني وجهد أكبر للحالات الهامشية أو المحتوى عالي المخاطر.
ما هو هيكل النموذج وما هي الإصدارات الموجودة؟
العائلة النموذجية والنسب
gpt-oss-safeguard هي بعد التدريب متغيرات من OpenAI السابقة gpt-oss نماذج مفتوحة. تتضمن مجموعة الحماية حاليًا حجمين متاحين:
- gpt-oss-safeguard-120b - نموذج يحتوي على 120 مليار معلمة مخصص لمهام التفكير عالية الدقة التي لا تزال تعمل على وحدة معالجة رسومية واحدة بسعة 80 جيجابايت في أوقات التشغيل المحسنة.
- gpt-oss-safeguard-20b - نموذج مكون من 20 مليار معلمة تم تحسينه للاستدلال الأقل تكلفة والبيئات المحلية أو الطرفية (يمكن تشغيله على أجهزة VRAM بسعة 16 جيجابايت في بعض التكوينات).
ملاحظات حول الهندسة المعمارية وخصائص وقت التشغيل (ما يمكن توقعه)
- المعلمات النشطة لكل رمز: تستخدم بنية gpt-oss الأساسية تقنيات تقلل من عدد المعلمات التي يتم تنشيطها لكل رمز (مزيج من نمط الاهتمام الكثيف والمتفرق / تصميم مزيج الخبراء في gpt-oss الرئيسي).
- عمليًا، تناسب فئة 120B مسرعات كبيرة فردية، بينما صُممت فئة 20B للعمل على إعدادات VRAM بسعة 16 جيجابايت في أوقات تشغيل مُحسّنة.
تم وضع نماذج الحماية غير مدرب على البيانات البيولوجية أو بيانات الأمن السيبراني الإضافيةوأن تحليلات أسوأ سيناريوهات سوء الاستخدام التي أُجريت لإصدار gpt-oss تنطبق تقريبًا على متغيرات الحماية. تهدف هذه النماذج إلى التصنيف وليس إلى إنشاء محتوى للمستخدمين النهائيين.
ما هي أهداف gpt-oss-safeguard؟
الأهداف
- مرونة السياسة: السماح للمطورين بتحديد أي سياسة باللغة الطبيعية وجعل النموذج يطبقها دون جمع علامات مخصصة.
- الشرح: كشف المنطق حتى يمكن تدقيق القرارات وتكرار السياسات.
- إمكانية الوصول: توفير بديل مفتوح الوزن حتى تتمكن المؤسسات من تشغيل التفكير الأمني محليًا وفحص الأجزاء الداخلية للنموذج.
مقارنة مع المصنفات الكلاسيكية
الإيجابيات مقابل التصنيفات التقليدية
- لا إعادة تدريب لتغييرات السياسة: إذا تغيرت سياسة التعديل الخاصة بك، فقم بتحديث مستند السياسة بدلاً من جمع العلامات وإعادة تدريب المصنف.
- تفكير أكثر ثراءً: يمكن لمخرجات CoT أن تكشف عن التفاعلات السياسية الدقيقة وتوفر مبررًا سرديًا مفيدًا للمراجعين البشريين.
- التخصيص: يمكن لنموذج واحد تطبيق العديد من السياسات المختلفة في وقت واحد أثناء الاستدلال.
السلبيات مقابل التصنيفات التقليدية
- سقوف الأداء لبعض المهام: تشير ملاحظات تقييم OpenAI إلى أن يمكن للمصنفات عالية الجودة المدربة على عشرات الآلاف من الأمثلة المصنفة أن تتفوق على gpt-oss-safeguard في مهام التصنيف المتخصصة. عندما يكون الهدف هو دقة التصنيف الخام ولديك بيانات مُصنّفة، يكون استخدام مُصنّف مُخصّص مُدرّب على هذا التوزيع أفضل.
- الكمون والتكلفة: إن الاستدلال باستخدام CoT يتطلب قدرًا كبيرًا من الحوسبة ويكون أبطأ من المصنف الخفيف الوزن؛ وهذا من شأنه أن يجعل خطوط الأنابيب القائمة على الضمانات فقط باهظة الثمن على نطاق واسع.
باختصار: من الأفضل استخدام gpt-oss-safeguard حيث مرونة السياسات وقابلية التدقيق تعتبر هذه الأولويات أو عندما تكون البيانات المصنفة نادرة - وباعتبارها مكونًا تكميليًا في خطوط الأنابيب الهجينة، وليس بالضرورة كبديل مباشر لمصنف مُحسَّن للحجم.
كيف كان أداء gpt-oss-safeguard في تقييمات OpenAI؟
نشرت OpenAI نتائج خط الأساس في تقرير فني من عشر صفحات يلخص التقييمات الداخلية والخارجية. النقاط الرئيسية (مقاييس مختارة وواضحة):
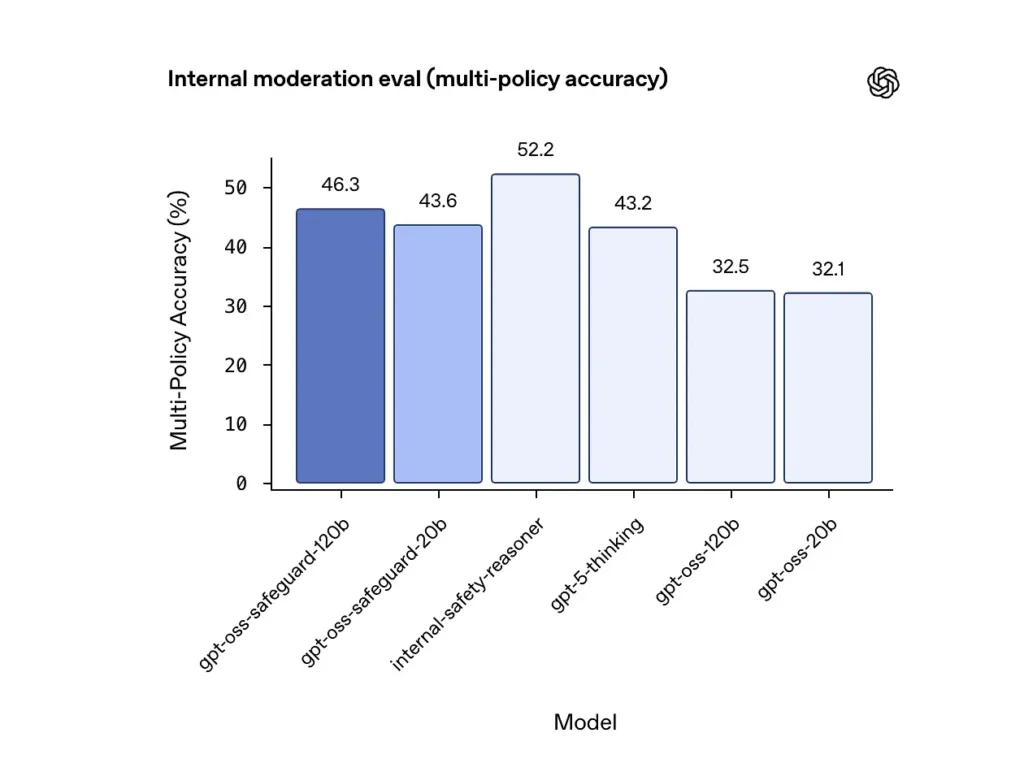
دقة السياسات المتعددة (التقييم الداخلي)
قامت OpenAI بتقييم دقة السياسات المتعددة من خلال إعطاء النموذج متعدد السياسات في وقت واحد واعتبار التنبؤ صحيحًا فقط إذا كان يتطابق مع العلامات الذهبية عبر الكل السياسات. النتائج:
- gpt-oss-safeguard-120b: 46.3% دقة السياسات المتعددة
- gpt-oss-safeguard-20b: 43.6%
- للمقارنة: gpt-5-التفكير: 43.2٪. gpt-oss-120b: 32.5٪. gpt-oss-20b: 32.1٪.
حصلت مجموعة "مُبرِّرات السلامة" الداخلية لشركة OpenAI على 52.2% في الاختبار نفسه. تُظهر هذه الأرقام تفوق نماذج الحماية على نماذج gpt-oss الأساسية بشكل ملحوظ في مهمة تعدد السياسات، بل وتجاوزت خط الأساس الأكبر للتفكير في gpt-5 في مقياس تعدد السياسات الداخلي.
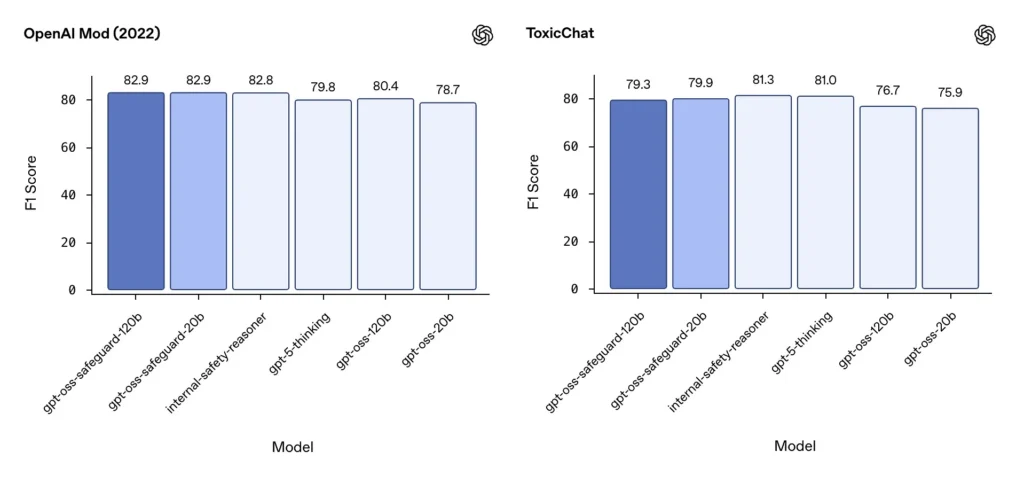
الاعتدال F1 (المعايير الخارجية)
في مجموعة بيانات تعديل OpenAI لعام 2022 ومعيار ToxicChat العام، حققت نماذج gpt-oss-safeguard درجات F1 قوية:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9%، gpt-oss-safeguard-20b = 82.9%
- الدردشة السامة F1: gpt-oss-safeguard-120b = 79.3%، gpt-oss-safeguard-20b = 79.9%
تضع هذه النتائج gpt-oss-safeguard بالقرب من أو خلف أنظمة OpenAI الداخلية المتخصصة قليلاً في بعض المعايير، وبشكل عام قبل نظيراتها gpt-oss غير المضبوطة.
القيود الملحوظة
تشير OpenAI إلى قيدين عمليين:
- لا يزال بإمكان المصنفين المدربين على مجموعات بيانات كبيرة ومحددة المهام أن يتفوقوا على نماذج الحماية عندما تكون دقة التصنيف هي الهدف الوحيد.
- تكاليف الحوسبة والزمن الكامن: يؤدي تفكير CoT إلى زيادة وقت الاستدلال واستهلاك الحوسبة، مما يؤدي إلى تعقيد عملية التوسع إلى حركة المرور على مستوى النظام الأساسي ما لم يقترن بمصنفات الفرز وأنابيب غير متزامنة.
التكافؤ متعدد اللغات
يؤدي gpt-oss-safeguard أداءً متساويًا مع نماذج gpt-oss الأساسية عبر العديد من اللغات في اختبارات نمط MMMLU، مما يشير إلى أن متغيرات الحماية المضبوطة بدقة تحتفظ بقدرة تفكير واسعة.
كيف يمكن للفرق الوصول إلى gpt-oss-safeguard ونشره؟
يوفر OpenAI الأوزان ضمن Apache 2.0 ويربط النماذج للتنزيل (Hugging Face). لأن gpt-oss-safeguard نموذج ذو أوزان مفتوحة، يُمكن النشر محليًا وإدارته ذاتيًا (موصى به للخصوصية والتخصيص).
- تنزيل أوزان النموذج (من OpenAI / Hugging Face) واستضفها على خوادمك الخاصة أو على أجهزة افتراضية سحابية. يسمح Apache 2.0 بالتعديل والاستخدام التجاري.
- وقت التشغيلاستخدم بيئات تشغيل الاستدلال القياسية التي تدعم نماذج المحولات الكبيرة (ONNX Runtime، أو Triton، أو بيئات تشغيل مُحسّنة من البائعين). تُضيف بيئات التشغيل المجتمعية، مثل Ollama وLM Studio، دعمًا لعائلات gpt-oss.
- أجهزة التبخيريتطلب 120B عادةً وحدات معالجة رسومية (GPU) ذات ذاكرة عالية (مثل 80 جيجابايت A100 / H100 أو تجزئة وحدات معالجة رسومية متعددة)، بينما يمكن تشغيل 20B بتكلفة أقل، مع خيارات مُحسّنة لإعدادات ذاكرة الوصول العشوائي للفيديو (VRAM) بسعة 16 جيجابايت. خصص سعة للمعالجة القصوى وتكاليف تقييم السياسات المتعددة.
أوقات التشغيل المُدارة وأوقات التشغيل التابعة لجهات خارجية
إذا كان تشغيل الأجهزة الخاصة بك غير عملي، كوميت ايه بي اي يُضيف دعمًا سريعًا لنماذج gpt-oss. قد تُسهّل هذه المنصات التوسع، لكنها تُعيد فرض قيود على عرض بيانات الجهات الخارجية. قيّم الخصوصية، واتفاقيات مستوى الخدمة، وضوابط الوصول قبل اختيار بيئات التشغيل المُدارة.
استراتيجيات الاعتدال الفعالة مع gpt-oss-safeguard
1) استخدام خط أنابيب هجين (الفرز → السبب → الحكم)
- طبقة الفرز: تُصفّي مُصنِّفات (أو قواعد) صغيرة وسريعة الحالات البسيطة. هذا يُخفِّف العبء على نموذج الحماية المُكلِّف.
- طبقة الحماية: قم بتشغيل gpt-oss-safeguard للتحقق من السياسات الغامضة أو عالية المخاطر أو المتعددة حيث تكون الفروق الدقيقة في السياسة مهمة.
- التحكيم البشري: تصعيد القضايا الهامشية والاستئنافات، مع حفظ CoT كدليل على الشفافية. يوازن هذا التصميم الهجين بين الإنتاجية والدقة.
2) هندسة السياسات (وليس الهندسة الفورية)
- تعامل مع السياسات باعتبارها من صنع البرمجيات: قم بإصدارها واختبارها مقابل مجموعات البيانات، واحتفظ بها واضحة وتسلسلية.
- اكتب سياسات مع أمثلة وأمثلة مضادة. إن أمكن، أضف تعليمات لتوضيح الغموض (مثل: "إذا كانت نية المستخدم استكشافية وتاريخية بوضوح، فسمّها X؛ وإذا كانت عملية وفورية، فسمّها Y").
3) تكوين جهد التفكير بشكل ديناميكي
- استعمل جهد منخفض للمعالجة بالجملة و جهد عالي للمحتوى المميز أو الاستئنافات أو القطاعات ذات التأثير العالي (القانونية أو الطبية أو المالية).
- قم بضبط الحدود باستخدام تعليقات المراجعة البشرية للعثور على النقطة المثالية للتكلفة/الجودة.
4) التحقق من صحة نظرية CoT ومراقبة التفكير المهووس
إن سجلّ التكرار قيّم، ولكنه قد يُوهم: فالأثر هو أساس منطقي مُولّد من نموذج، وليس حقيقةً ثابتة. تُدقّق مخرجات سجلّ التكرار بشكل روتيني؛ حيث تكشف الأجهزة عن الاستشهادات المُهووسة أو الاستدلالات غير المتطابقة. تُوثّق OpenAI سلاسل الأفكار المُهووسة كتحدٍّ مُلاحظ، وتقترح استراتيجياتٍ للتخفيف من حدّتها.
5) بناء مجموعات البيانات من تشغيل النظام
سجّل قرارات النماذج والتصحيحات البشرية لإنشاء مجموعات بيانات مُصنّفة تُحسّن مُصنّفات الفرز أو تُفيد في إعادة صياغة السياسات. مع مرور الوقت، غالبًا ما يُقلّل وجود مجموعة بيانات مُصنّفة صغيرة وعالية الجودة، بالإضافة إلى مُصنّف فعّال، من الاعتماد على استدلال CoT الكامل للمحتوى الروتيني.
6) مراقبة الحوسبة والتكاليف؛ استخدام التدفقات غير المتزامنة
بالنسبة للتطبيقات الموجهة للمستهلكين ذات زمن الوصول المنخفض، يُنصح بإجراء فحوصات أمان غير متزامنة مع تجربة مستخدم متحفظة قصيرة المدى (مثل إخفاء المحتوى مؤقتًا أثناء المراجعة) بدلًا من إجراء اختبارات CoT التي تتطلب جهدًا كبيرًا بشكل متزامن. تشير OpenAI إلى أن Safety Reasoner يستخدم تدفقات غير متزامنة داخليًا لإدارة زمن الوصول لخدمات الإنتاج.
7) مراعاة الخصوصية وموقع النشر
نظرًا لأن الأوزان مفتوحة، يمكنك تشغيل الاستدلال بالكامل محليًا للامتثال لحوكمة البيانات الصارمة أو تقليل التعرض لواجهات برمجة التطبيقات التابعة لجهات خارجية - وهو أمر ذو قيمة للصناعات الخاضعة للتنظيم.
الخلاصة:
gpt-oss-safeguard هي أداة عملية وشفافة ومرنة لـ المنطق الأمني القائم على السياسة.إنه يلمع عندما تحتاج إليه القرارات القابلة للتدقيق والمرتبطة بسياسات صريحةعندما تتغير سياساتك بشكل متكرر، أو عندما ترغب في إجراء فحوصات السلامة في الموقع. لست حلٌّ سحريٌّ سيحلُّ محلَّ المُصنِّفات المتخصصة عالية الحجم تلقائيًا - تُظهر تقييمات OpenAI أن المُصنِّفات المُخصَّصة المُدرَّبة على مجموعات بيانات كبيرة مُصنَّفة يمكنها التفوُّق على هذه النماذج من حيث الدقة الخام للمهام المحدودة. بدلًا من ذلك، يُمكِن اعتبار gpt-oss-safeguard مُكوِّنًا استراتيجيًا: مُحرِّك الاستدلال القابل للتفسير في صميم بنية أمان متعددة الطبقات (الفرز السريع ← الاستدلال القابل للتفسير ← الإشراف البشري).
كيف تبدأ
CometAPI هي منصة واجهات برمجة تطبيقات موحدة تجمع أكثر من 500 نموذج ذكاء اصطناعي من أبرز المزودين، مثل سلسلة GPT من OpenAI، وGemini من Google، وClaude من Anthropic، وMidjourney، وSuno، وغيرهم، في واجهة واحدة سهلة الاستخدام للمطورين. من خلال توفير مصادقة متسقة، وتنسيق الطلبات، ومعالجة الردود، تُبسط CometAPI بشكل كبير دمج قدرات الذكاء الاصطناعي في تطبيقاتك. سواء كنت تُنشئ روبوتات دردشة، أو مُولّدات صور، أو مُلحّنين موسيقيين، أو خطوط أنابيب تحليلات قائمة على البيانات، تُمكّنك CometAPI من التكرار بشكل أسرع، والتحكم في التكاليف، والاعتماد على مورد واحد فقط، كل ذلك مع الاستفادة من أحدث التطورات في منظومة الذكاء الاصطناعي.
سيظهر أحدث تكامل gpt-oss-safeguard قريبًا على CometAPI، لذا ترقبوا ذلك! بينما ننتهي من تحميل نموذج gpt-oss-safeguard، يمكن للمطورين الوصول إليه واجهة برمجة التطبيقات GPT-OSS-20B و واجهة برمجة التطبيقات GPT-OSS-120B من خلال CometAPI، أحدث إصدار للنموذج يتم تحديثه دائمًا بالموقع الرسمي. للبدء، استكشف إمكانيات النموذج في ملعب واستشر دليل واجهة برمجة التطبيقات للحصول على تعليمات مفصلة. قبل الدخول، يُرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. كوميت ايه بي اي عرض سعر أقل بكثير من السعر الرسمي لمساعدتك على التكامل.
هل أنت مستعد للذهاب؟→ سجل في CometAPI اليوم !
إذا كنت تريد معرفة المزيد من النصائح والإرشادات والأخبار حول الذكاء الاصطناعي، فتابعنا على VK, X و ديسكورد!