

تم إطلاق xAI بهدوء جروك 4.1 (17-18 نوفمبر 2025) - ترقية مُركزة لـ Grok 4 تعطي الأولوية الذكاء العاطفي والتعبير الإبداعي وتقليل الهلوسة مع الحفاظ على المنطق الحادّ لإصدارات Grok السابقة. يتوفر في وضعين (التفكير/عدم التفكير)، وتم إطلاقه بصمت في أوائل نوفمبر، ويُظهر نتائج أفضل المتصدرين على LMArena، وهو متاح عبر grok.com وتطبيقات Grok وواجهة برمجة التطبيقات.
ما هو جروك 4.1؟
Grok 4.1 هو خليفة Grok 4 التدريجي المُركّز على الإنتاج: وهو عضوٌ من عائلة مبني على نفس أساس التعلّم التعزيزي واسع النطاق، ولكن مع صقله وإعادة تدريبه مع تحسيناتٍ مكثفة بعد التدريب تهدف إلى تحسين الأسلوب والشخصية والتوافق والموثوقية في العالم الواقعي. يُقدّم كخطوةٍ عمليةٍ و"قابلةٍ للاستخدام" إلى الأمام: أذكى في اختبارات التفضيل البشري العمياء، وأكثر ذكاءً عاطفيًا، وأفضل في الكتابة الإبداعية، وأقل عرضة بشكلٍ ملحوظٍ لـ"الهلوسة" الواثقة ولكن الخاطئة التي أزعجت طلاب ماجستير القانون ذوي الأداء العالي السابقين.
يحقق Grok 4.1 تغييرات نوعية في الأبعاد الأربعة التالية:
- الإبداع: إظهار أسلوب لغوي أقوى وخيال في الكتابة ورواية القصص والسياقات الاجتماعية؛
- الذكاء العاطفي: التعرف على نبرة الصوت والتغيرات العاطفية، والاستجابة بمنطق عاطفي أكثر إنسانية وتوليد استجابات مريحة ومتفهمة؛
- تماسك الشخصية: يحافظ على نبرة وشخصية متسقة في المحادثات الطويلة، ولا يظهر بعد الآن السلوك غير المتسق للنماذج السابقة؛
- تعاوني: يحافظ على التماسك والوعي بالهدف في الحوارات متعددة الأدوار أو التعاون في المهام.
يلخص xAI خصائصه في جملة واحدة: "إنه أكثر إدراكًا، وأكثر تعاطفًا، وأكثر تماسكًا".
كيف يعمل Grok 4.1 تحت الغطاء؟
يمكن فهم Grok 4.1 على أفضل وجه باعتباره نفس العمود الفقري المدرب مسبقًا المستخدم في عائلة Grok 4 بالإضافة إلى خط أنابيب ما بعد التدريب متعدد الطبقات والذي يركز على نمذجة المكافآت، ومواءمة الأسلوب، والمقيّمون الوكلاء.
ما هي مراحل التدريب والتنسيق؟
يعمل Grok 4.1 على خط أنابيب متعدد المراحل نموذجي لبرامج ماجستير القانون الرائدة الحديثة، مع تعديله مع فترتين مهمتين لـ 4.1:
- ما قبل التدريب + منتصف التدريب: تدريب مسبق لمجموعة كبيرة من البيانات على الويب + تدريب متوسط مستهدف لتعزيز معرفة المجال والقدرات المتعددة الوسائط.
- الضبط الدقيق الخاضع للإشراف (SFT): المظاهرات البشرية للسلوكيات المرغوبة (الردود، واستراتيجيات الرفض).
- نمذجة المكافأة (تطبيق جديد): تم تدريب نماذج المكافآت بواسطة الذكاء الاصطناعي ليس فقط على تسميات التفضيلات البشرية ولكن أيضًا على نماذج الاستدلال الوكيلي الحدودي كمقيّمين للمكافآت، مما يتيح للمقيّمين ذوي الكفاءة العالية، القائمين على النماذج، تقييم مخرجات المرشحين على نطاق واسع. وقد مكّن هذا من تحسين السمات غير القابلة للتحقق مثل الأسلوب، وتماسك الشخصية، والتعاطف، والمساعدة دون الحاجة إلى ميزانية ضخمة لوضع العلامات البشرية.
- تحسين السياسة (RLHF / RL من مكافآت النموذج): تحسين السياسة القياسية باستخدام إشارات المكافأة المكتسبة لإنتاج السياسة المنشورة (النموذج الذي يتفاعل معه المستهلكون).
ما الجديد في نهج نمذجة المكافأة؟
في RLHF التقليدي، تجمع تصنيفات التفضيلات البشرية (A/B)، وتُدرّب نموذج مكافآت للتنبؤ بتلك التصنيفات، ثم تُحسّن النموذج الأساسي باستخدام RL (أو أخذ العينات المرفوضة) بناءً على تلك المكافأة المُكتسبة. لكن يُبرز الذكاء الاصطناعي xAI ابتكارين عمليين:
- نماذج المكافأة الوكيلية: بدلاً من المُحكمين البشريين البحتين، استخدم الذكاء الاصطناعي نماذج استدلال "فاعلة" كفؤة لتقييم الخصائص الأكثر دقة (مثل النبرة، والدلالات العاطفية، والإبداع). يستطيع المُقيّمون إجراء آلاف المقارنات الثنائية بسرعة، مما يُتيح للمهندسين التكرار بشكل أسرع. هذه هي آلية التحسينات الكبيرة في الأسلوب والذكاء العاطفي.
- محاذاة ما بعد التدريب للإشارات غير القابلة للتحقق: بالنسبة للسمات التي لا يمكنك قياسها بمقياس محدد (على سبيل المثال، "الدفء" أو "الشخصية المتماسكة")، فقد قدموا أهداف مكافأة متخصصة ومناهج دراسية متدرجة حتى يتعلم النموذج نمط من المخرجات دون التضحية بالدقة الواقعية الأساسية.
كيف يعمل "التفكير" مقابل "عدم التفكير" من الناحية الفنية؟
- Grok 4.1 Thinking (الاسم الرمزي
quasarflux) — يعرض خطوات استدلال واضحة (رموز التفكير) قبل إنتاج الإجابة النهائية؛ مُحسّن للمهام المعقدة وتصنيف Elo الأعلى في LMArena. تُستهلك الرموز الإضافية وقتًا للاستدلال، لكنها تُساعد في مهام الاستدلال متعددة الخطوات، وتصحيح الأخطاء، وسهولة التفسير. - Grok 4.1 عدم التفكير (الاسم الرمزي
tensor) يتجاوز الرموز الوسيطة الصريحة لاستجابة نهائية فورية واحدة. هذا يقلل من زمن الوصول وتكلفة الرموز مع الاستفادة من نفس أوزان السياسات المُحسّنة. تم تحسين وضع عدم التفكير ليكون زمن الوصول منخفضًا للغاية مع الحفاظ على قدراته العالية.
تحسين محاذاة المشاعر والأسلوب
إلى جانب إشارات "الصدق" البسيطة، يتضمن Grok 4.1 تحسينًا مُستهدفًا لتوافق المشاعر ونبرة الصوت وأسلوب التعامل. هذا يعني أن مسار التدريب يتضمن عناصر مكافأة أو خسارة تُعاقب صراحةً على عدم توافق نبرة الصوت (مثلًا، الفظاظة غير المُبررة عندما يكون التعاطف مُناسبًا) ومكافآت تُطابق الأسلوب أو نمط المشاعر المُراد. في Grok 4.1، قدّم الذكاء الاصطناعي لأول مرة هدف التحسين "توافق الشخصية".
يهدف إلى مساعدة النموذج على الحفاظ على هوية ثابتة ومستقرة. مقارنةً بـ Grok 4، يضيف 4.1 ما يلي إلى أهداف التدريب:
- مكافآت إيجابية لبعد التعبير العاطفي (مكافأة التوافق العاطفي)؛
- مقياس تماسك الشخصية.
كيف تم تقييم Grok 4.1 - وكيف كان أداؤه؟
ماذا أظهرت اختبارات التفضيل البشري العمياء؟
خلال عملية الطرح الصامت، تم تفضيل Grok 4.1 بنسبة 64.78% من الوقت مقارنة بنموذج الإنتاج السابق في حركة المرور المباشرة - وهي إشارة تفضيل بشرية قوية تشير إلى نتائج محادثة أفضل في البرية.
هل يتصدر Grok 4.1 قائمة المتصدرين؟
تُفيد تقارير xAI أن Grok 4.1 تفكير الوضع يجلس في #1 على ساحة النصوص في LMArena، مع تقرير ELO من 1483، ووضعها غير المنطقي (السريع) يحتل المرتبة الثانية مع 1465 Elo - ترتيب قوي في قائمة المتصدرين العامة لكل من الدقة والعرض (يلعب التحكم في الأسلوب دورًا).
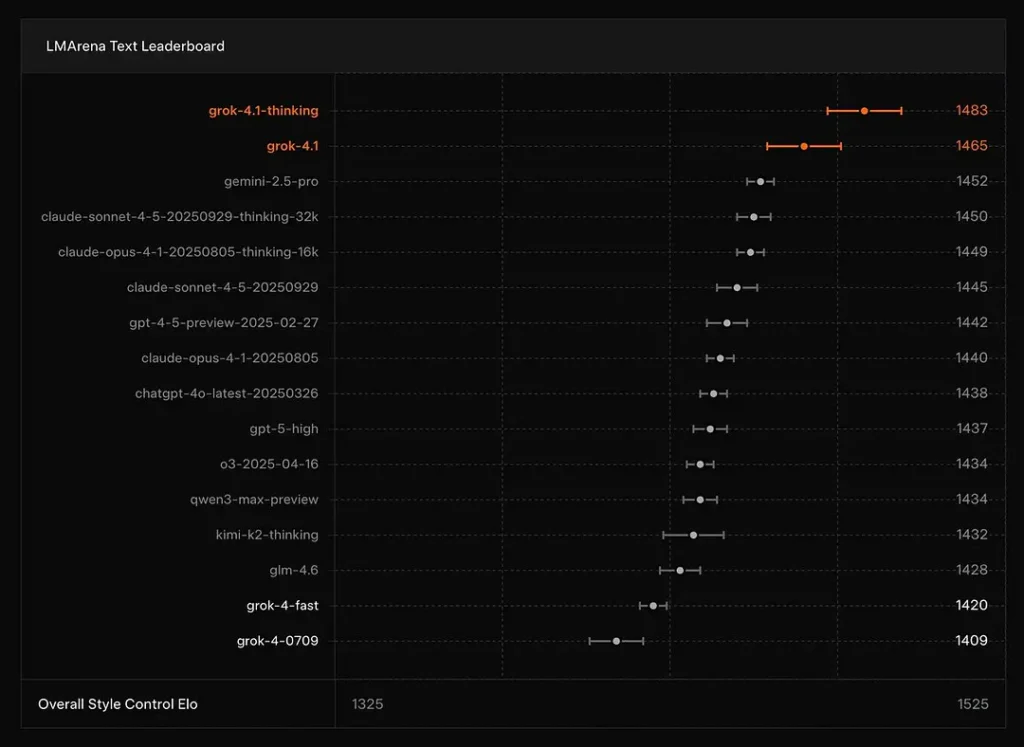
الاستنتاج: يتفوق Grok 4.1 على نماذج GPT-4.5 وسلسلة Claude السائدة في فهم النصوص وتوليدها والجودة الشاملة، ويأتي في المرتبة الثانية فقط بعد إصدار GPT-5 Advanced Preview.
الذكاء العاطفي
أجرت شركة xAI اختبار EQ-Bench3، وهو اختبار متخصص للذكاء العاطفي يغطي 45 سيناريو لعب أدوار صعب، وأفادت أن Grok 4.1 يظهر مكاسب قوية في التعاطف والوتيرة والبصيرة الشخصية. وسجل Grok 4.1 أعلى الدرجات في فهم سياقات الحزن والتعاطف والراحة.

الكتابة الإبداعية - هل هي في الواقع أكثر إبداعًا؟
تم تقييم Grok 4.1 على الكتابة الإبداعية الإصدار 3 (32 مُطالبة عبر 3 إصدارات مع معايير التقييم + تقييم ELO). تُشير شركة xAI إلى أن أسلوب الكتابة، وتناسق الصوت، والإبداع السردي في الإصدار 4.1 قد تحسن بشكل ملحوظ، مما جعله قريبًا من صدارة قوائم المتصدرين الأخيرة للمهام الإبداعية (أمثلة على المُطالبات مُضمنة في الإصدار). وقد عكست التقارير المستقلة هذه النتائج: فقد لاحظ المُراجعون "صوتًا مميزًا" بشكل ملحوظ وتماسكًا أفضل في النص المُطول. من حيث جودة الكتابة، يأتي Grok 4.1 في المرتبة الثانية بعد طُرز سلسلة GPT-5، ويتفوق على جميع خطوط إنتاج Claude وGemini وKimi.

انخفاض الهلوسة / الصدق
تدعي شركة xAI حدوث انخفاض ملحوظ في معدلات الهلوسة: فقد ذكرت (في الإعلان والمنشورات الاجتماعية) أن Grok 4.1 هو ~3 مرات أقل عرضة للهلوسة بالمقارنة مع نماذج Grok السابقة، التي تعتمد على تحليلات حركة الإنتاج وتقييمات FActScore (مثل مجموعات أسئلة السيرة الذاتية، كلما كان العدد أقل كان أفضل). خاصةً في الوضع غير المنطقي حيث تتوفر أدوات بحث خارجية، يكون اتساق الحقائق أكثر استقرارًا.

لماذا يتفوق Grok 4.1 على النماذج الأخرى - هل هذا مبالغة؟
"Crushes" هي عبارة عن حملة تسويقية، ولكن هناك ادعاءات موضوعية وراء هذه الادعاءات:
- الصدارة: يحتل Grok 4.1 مراكز متقدمة في قوائم صدارة LMArena العامة في توليد النصوص (1483 Elo لوضع التفكير) وعروض إبداعية قوية ونتائج اختبار الذكاء الاصطناعي لكل إصدار من xAI. هذه مقاييس تنافسية متقاربة تُستخدم في جميع أنحاء المجتمع.
- تفضيلات حركة المرور الحقيقية تفوز: أفادت تقارير xAI بتفوق التفضيلات البشرية في المقارنات العمياء (حوالي 65% تفضيل مقارنةً بنموذج الإنتاج السابق) من خلال طرح صامت على حركة مرور مباشرة. يعكس هذا تحسينات المستخدمين الفعليين، وليس مجرد معايير مرجعية.
- القدرة العملية الجديدة: إن الجمع بين مصنفي النماذج، والتعزيز على الإشارات غير القابلة للتحقق، ومرشحات الإدخال الأكثر صرامة هو خطوة هندسية عملية تعمل بشكل مباشر على تحسين تجربة المستخدم في المهام المحادثة والتعاطفية والإبداعية حيث يكون أداء المنافسين ضعيفًا تاريخيًا.
لذا، في حين أن "السحق" هي طريقة ملونة لقول "القيادة في العديد من التقييمات العامة والداخلية"، فإن المقاييس العامة الأساسية التي نشرتها xAI تدعم هذا الاستنتاج
كيفية الوصول إلى Grok 4.1
وصول المستهلك / التطبيق
لقد قامت شركة xAI بشكل دوري بإتاحة Grok 4.1 في الوضع "التلقائي" مجانًا أو كنافذة ترويجية، ولكن الطبقات المتميزة (SuperGrok، SuperGrok Heavy) وإمكانية الوصول إلى واجهة برمجة التطبيقات ذات الحصص الأعلى موجودة وتستمر كعروض مدفوعة.
Grok 4.1 متاح لجميع المستخدمين on جروك.كوم, X (تويتر سابقًا)، وتطبيقات Grok لنظامي التشغيل iOS وAndroid، والتي يتم طرحها على الفور في الوضع التلقائي مع إمكانية تحديدها صراحةً كـ "Grok 4.1" في أداة اختيار النموذج.
خطط الوصول إلى واجهة برمجة التطبيقات والمطورين
تتوفر نقاط نهاية Grok 4.1 عبر واجهة برمجة تطبيقات xAI. حتى تاريخ نشر هذه المقالة، لم تُصدر واجهة برمجة تطبيقات GPT 4.1 الرسمية.
كوميت ايه بي اي وعد بتتبع أحدث ديناميكيات النموذج بما في ذلك واجهة برمجة تطبيقات Grok 4.1، والذي سيصدر بالتزامن مع الإصدار الرسمي. ترقبوه وتابعوا CometAPI. أثناء انتظاركم، يمكنكم الاطلاع على نماذج Grok الأخرى مثل جروك-كود-فاست-1 و جروك 4استكشف إمكانياتهم في ساحة اللعب، وراجع دليل واجهة برمجة التطبيقات (API) للحصول على تعليمات مفصلة للاتصال. قبل الوصول، يُرجى التأكد من تسجيل دخولك إلى CometAPI والحصول على مفتاح واجهة برمجة التطبيقات.
نصائح عملية لاستخدام Grok 4.1 في الإنتاج
كيفية تقليل خطر الهلوسة
- تمكين البحث المباشر أو سلسلة أدوات تم التحقق منها لاستفسارات البحث عن المعلومات.
- توفير خطوات التحقق: اطلب من النموذج إرجاع المصادر والأدلة للادعاءات الواقعية؛ استخدم
responseالبيانات الوصفية لفحص الاستشهادات (إذا كانت متوفرة). - تشغيل فحوصات حتمية (ماجستير في القانون للتحقق من الحقائق، ومحققي البيانات المنظمة) كخطوة لاحقة في المعالجة للمخرجات ذات المخاطر العالية.
كيفية التحكم في النغمة والأسلوب
- استخدم إشارات نظامية صريحة لإصلاح الصوت ("أنت رسمي ومتعاطف").
- استخدم الإرشادات الخاضعة للإشراف والقوالب المحلية الصغيرة للحصول على صوت متسق عبر التطبيقات.
- عند توفرها، استفد من خيار التحكم في الأسلوب في xAI ومقابض التوجيه المدفوعة بالمكافآت.
الحكم النهائي: هل يعتبر Grok 4.1 تغييراً كبيراً؟
جروك 4.1 هو لست هندسة معمارية جديدة تمامًا؛ بل هي هندسة معمارية متطورة ومدروسة ما بعد التدريب / المحاذاة إصدار يركز على ما يهتم به البشر فعليًا في الدردشة: الشخصية، والذكاء العاطفي، والإبداع، والأخطاء الواقعية الأقلتحسينات ملحوظة في قوائم المتصدرين، وتفضيلات واسعة النطاق لحركة المرور الفعلية، وأدوات أمان مُحسّنة. بالنسبة للتطبيقات التي تعتمد على محادثات عالية الجودة، أو تعاون إبداعي، أو مساعدة مُراعية للأسلوب، يُعدّ Grok 4.1 خطوةً كبيرةً للأمام، وفي العديد من معايير مجتمع المستخدمين، كان الأفضل أداءً وقت إصداره.
CometAPI هي منصة تجارية لتجميع واجهات برمجة التطبيقات (API)، تُتيح للمطورين وصولاً موحدًا، بنمط OpenAI، إلى مئات نماذج الذكاء الاصطناعي من مُورِّدين مُختلفين - مثل نماذج LLM النصية، ومُولِّدات الصور/الفيديو، والتضمينات، وغيرها - من خلال واجهة واحدة مُتسقة. بدلًا من ربط حزم تطوير برمجيات (SDKs) مُنفصلة أو نقاط نهاية مُخصصة لـ OpenAI أو Anthropic أو Google أو Meta أو مُورِّدي نماذج مُتخصصين أصغر حجمًا، تُتيح لك CometAPI استدعاء نماذج مُختلفة عن طريق تغيير سلاسل النماذج وبعض المُعاملات.
هل أنت مستعد للمحاولة؟→ سجل في CometAPI اليوم !
إذا كنت تريد معرفة المزيد من النصائح والإرشادات والأخبار حول الذكاء الاصطناعي، فتابعنا على VK, X و ديسكورد!