

GLM-5 هو نموذج أساس جديد مفتوح الأوزان من Zhipu AI يتمحور حول الوكلاء، ومصمم للبرمجة بعيدة المدى والوكلاء متعددي الخطوات. وهو متاح عبر عدة واجهات API مُستضافة (بما في ذلك CometAPI ونقاط مزوّدين) وكذلك كإصدار بحثي مع الشيفرة والأوزان؛ يمكنك دمجه باستخدام استدعاءات REST المتوافقة مع OpenAI القياسية، والبثّ، وحِزم SDK.
ما هو GLM-5 من Z.ai؟
GLM-5 هو النموذج الرائد من الجيل الخامس لدى Z.ai المصمم لأغراض الهندسة المعتمدة على الوكلاء: التخطيط بعيد المدى، استخدام الأدوات على خطوات متعددة، وتصميم الشيفرة/النظم على نطاق واسع. أُصدر علنًا في فبراير 2026، وهو نموذج Mixture-of-Experts (MoE) بإجمالي معلمات يقارب ~744 مليارًا ومجموعة معلمات نشطة في نطاق 40B لكل تمرير أمامي؛ تُعطي البنية وخيارات التدريب أولوية لتماسك السياق الطويل، واستدعاء الأدوات، واستدلال منخفض التكلفة لأعباء العمل الإنتاجية. تسمح هذه الاختيارات لـ GLM-5 بتشغيل سير عمل وكيلية ممتدة (مثلًا: استعراض → تخطيط → كتابة/اختبار الشيفرة → تكرار) مع الحفاظ على السياق عبر مدخلات طويلة جدًا.
أبرز الجوانب التقنية:
- بنية MoE بإجمالي ~744B / ~40B معلمات نشطة؛ تدريب موسّع مسبقًا (~28.5T رموز مُبلغ عنها) لتقليص الفجوة مع نماذج المقدّمة المغلقة.
- دعم سياق طويل وتحسينات (انتباه متفرق عميق، DSA) لخفض تكلفة النشر مقارنة بالتحجيم الكثيف البسيط.
- ميزات وكيليّة مدمجة: استدعاء الأدوات/الوظائف، دعم الجلسات ذات الحالة، ومخرجات مدمجة (قادرة على إنتاج عناصر
.docxو.xlsxو.pdfكجزء من سير عمل الوكيل في واجهات البائع). - توافر الأوزان المفتوحة (أوزان منشورة في مستودعات النماذج) وخيارات وصول مُستضافة (واجهات APIs وخدمات استدلال مصغّرة).
ما هي المزايا الرئيسية لـ GLM-5؟
التخطيط الوكيلي والذاكرة طويلة الأمد
تعطي بنية GLM-5 وضبطه أولوية للتفكير متعدد الخطوات المتسق والذاكرة عبر سير العمل — وهو مفيد لـ:
- الوكلاء المستقلون (مسارات CI، منظّمات المهام)،
- توليد الشيفرة على نطاق واسع عبر ملفات متعددة أو إجراء إعادة هيكلة، و
- ذكاء المستندات الذي يحتاج للاحتفاظ بسجلّات كبيرة.
نوافذ سياق كبيرة
يدعم GLM-5 أحجام سياق كبيرة جدًا (في حدود ~200k رمز وفق مواصفات النموذج المنشورة)، مما يتيح لك الاحتفاظ بالمزيد من الجلسة في طلب واحد ويقلّل الحاجة إلى التقسيم العدواني أو ذاكرة خارجية في العديد من حالات الاستخدام. (انظر مخطط المقارنة أدناه.)
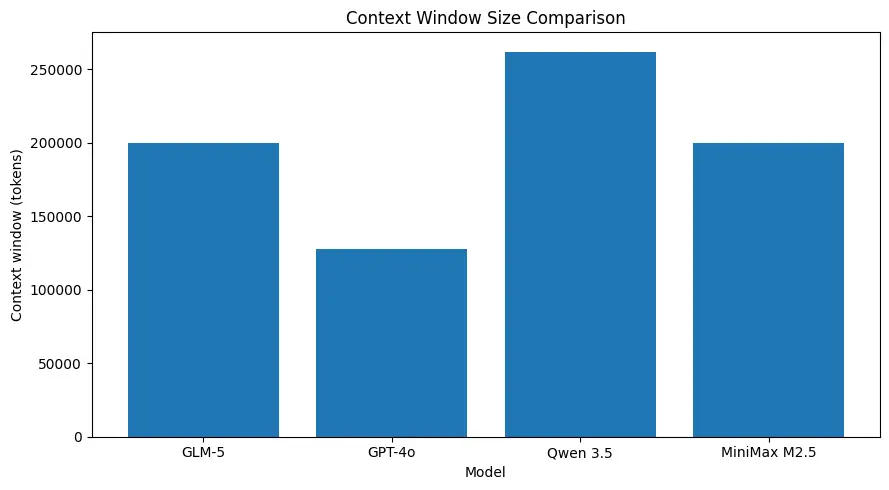
أداء ترميزي قوي لمهام على مستوى النظام
يسجّل GLM-5 أداءً رائدًا مفتوح المصدر على معايير هندسة البرمجيات (SWE-bench وأطقم الشيفرة + الوكلاء التطبيقية). على SWE-bench-Verified يبلّغ عن ~77.8%؛ وعلى اختبارات وكلاء الترميز/النمط الطرفي (Terminal-Bench 2.0) تتجمّع النتائج في منتصف الخمسينيات—ما يدل على قدرة عملية على البرمجة تقترب من النماذج الاحتكارية المتقدمة. تعني هذه المقاييس أن GLM-5 مناسب لمهام مثل توليد الشيفرة، إعادة الهيكلة الآلية، الاستدلال عبر ملفات متعددة، وسيناريوهات مساعدين CI/CD.
مفاضلات التكلفة/الكفاءة
نظرًا لاستخدام GLM-5 تقنيات MoE وابتكارات الانتباه “المتفرق”، فإنه يهدف إلى تقليل تكلفة الاستدلال لكل وحدة قدرة مقارنة بالتحجيم الكثيف بالقوة الغاشمة. CometAPI تقدّم نقاط تسعير تنافسية تجعل GLM-5 جذابًا لأعباء عمل الوكلاء عالية الإنتاجية.
كيف أستخدم واجهة GLM-5 عبر CometAPI؟
الإجابة المختصرة: اعتبر CometAPI بوابة متوافقة مع OpenAI — اضبط عنوان الأساس ومفتاح API، اختر glm-5 كنموذج، ثم استدعِ نقطة نهاية chat/completions. توفّر CometAPI واجهة REST بأسلوب OpenAI (نقاط نهاية مثل /v1/chat/completions) بالإضافة إلى SDKs ومشاريع نموذجية تجعل الانتقال بسيطًا.
فيما يلي دليل عملي موجّه للإنتاج: المصادقة، نداء الدردشة الأساسي، البثّ، استدعاء الوظائف/الأدوات، والتعامل مع التكلفة/الاستجابة.
الخطوات الأساسية للوصول إلى GLM-5 عبر CometAPI هي:
- اشترك على CometAPI واحصل على مفتاح API.
- اعثر على معرّف النموذج الدقيق لـ GLM-5 في كتالوج CometAPI (
"glm-5"حسب الإدراج). - أرسل طلب POST مُوثّقًا إلى نقطة نهاية chat/completions الخاصة بـ CometAPI (على نمط OpenAI).
تفاصيل الأساس (أنماط CometAPI): المنصة تدعم مسارات على نمط OpenAI مثل https://api.cometapi.com/v1/chat/completions، مصادقة Bearer، معامل model, رسائل النظام/المستخدم، البثّ، وأمثلة كلٍ من curl/python في الوثائق.
مثال: إتمام دردشة سريع بلغة Python (requests) مع GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
مثال: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
الاستجابة المتدفقة (نمط عملي)
يدعم CometAPI البثّ على نمط OpenAI (SSE / chunked). أبسط نهج في Python هو طلب "stream": true والتكرار على بيانات الاستجابة عند وصولها. هذا مهم عندما تحتاج إلى إخراج جزئي منخفض زمن الوصول (بناء مساعدين مطوّرين في الزمن الحقيقي، واجهات بثّ).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
مرجع: وثائق البثّ على نمط OpenAI وتوافق CometAPI.
استدعاء وظيفة/أداة (كيفية استدعاء أداة خارجية)
يدعم GLM-5 أنماط استدعاء الوظائف أو الأدوات المتوافقة مع أعراف OpenAI / المُجمِّعين (تقوم البوابة بتمرير استدعاءات وظيفية مُهيكلة ضمن استجابة النموذج). حالة استخدام: اطلب من GLM-5 استدعاء أداة محلية "run_tests"؛ سيُرجع النموذج تعليمات مُهيكلة يمكنك تحليلها وتنفيذها.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
عندما يُرجع النموذج حمولة function_call، نفّذ الأداة في الخادم ثم أعد تغذية نتيجة الأداة كرسالة بدور "tool" واستأنف المحادثة. يمكّن هذا النمط استدعاء أدوات آمنًا وتدفّقات وكلية ذات حالة. راجع وثائق وأمثلة CometAPI لمساعدات SDK ملموسة.
معاملات عملية والضبط
function_call: استخدمها لتمكين استدعاء الأدوات المُهيكل وتدفّقات تنفيذ أكثر أمانًا.
temperature: 0–0.3 لمخرجات نظامية حتمية (شيفرة، بنى تحتية)، أعلى للأفكار.
max_tokens: اضبطه لطول المخرجات المتوقع؛ يدعم GLM-5 مخرجات طويلة جدًا عند الاستضافة (تختلف الحدود لدى المزوّدين).
top_p / انتقاء النوى: مفيد لتقييد الذيول غير المحتملة.
stream: true لواجهات تفاعلية.
مقارنة GLM-5 مع Claude Opus من Anthropic ونماذج المقدمة الأخرى
الإجابة المختصرة: يقرّب GLM-5 الفجوة مع النماذج المغلقة المتقدّمة في مقاييس الوكلاء والترميز، بينما يقدّم نشرًا بأوزان مفتوحة وغالبًا تكلفة أفضل لكل رمز عند الاستضافة لدى المجمعين. التفصيل: في بعض مقاييس الترميز المطلقة (SWE-bench، متحورات Terminal-Bench) لا يزال Claude Opus (4.5/4.6) يتصدّر بهوامش قليلة في كثير من اللوائح المنشورة — لكن GLM-5 شديد التنافسية ويتفوّق على العديد من النماذج المفتوحة الأخرى.
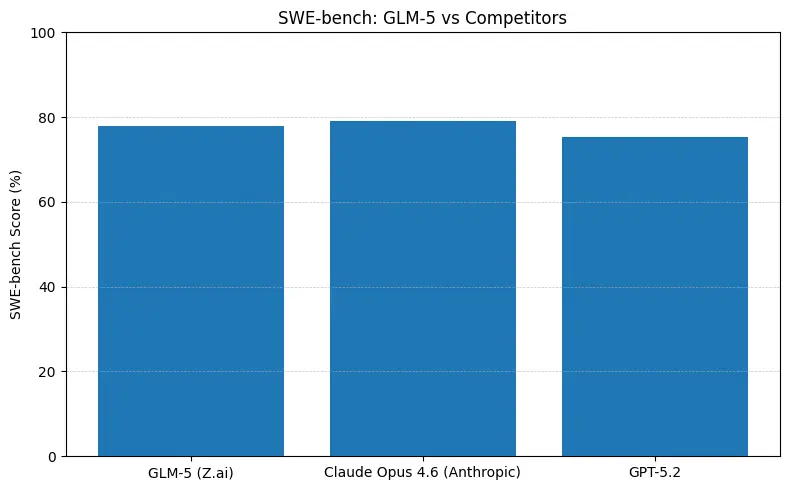
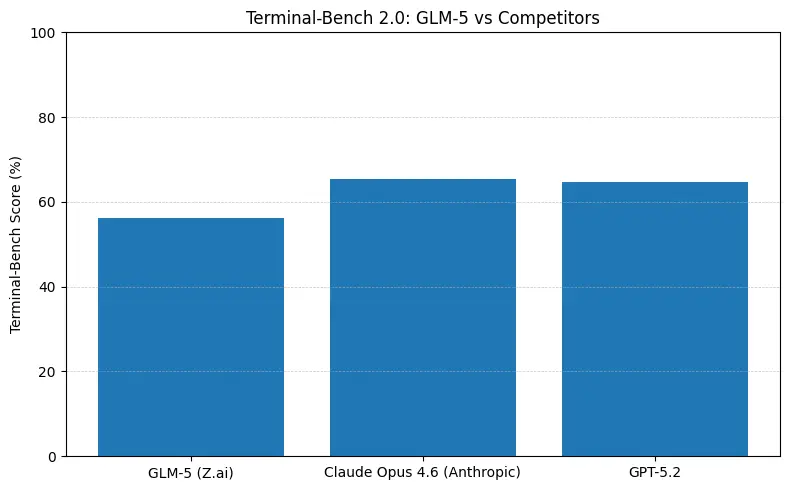
ماذا تعني الأرقام عمليًا
- SWE-bench (~صحة الشيفرة / الهندسة): يظهر Claude Opus تقدّمًا طفيفًا (≈79% مقابل GLM-5 ≈77.8%) على اللوائح المنشورة؛ في كثير من المهام الواقعية قد يُترجم ذلك إلى عدد أقل من التعديلات اليدوية، وليس بالضرورة إلى اختيار بنية مختلفة للنمذجة الأولية أو سير عمل وكيلية موسّعة.
- Terminal-Bench (مهام وكيلية على سطر الأوامر): Opus 4.6 يتصدّر (≈65.4% مقابل GLM-5 ≈56.2%) — إذا كنت تحتاج أتمتة طرفية قوية واعتمادية عالية على عمليات صدفة خارج التوزيع، غالبًا ما يكون Opus أفضل بهامش.
- الوكلاء وطويل الأمد: يقدّم GLM-5 أداءً قويًا على محاكاة أعمال طويلة الأمد (Vending-Bench 2 رصيد $4,432 مُبلغ عنه) ويُظهر تماسك تخطيطيًا قويًا لسير عمل متعدد الخطوات. إذا كان منتجك وكيلًا طويل التشغيل (مالية، عمليات)، فإن GLM-5 قوي.
كيف أصمم التوجيهات والأنظمة للحصول على مخرجات موثوقة من GLM-5؟
رسائل النظام والقيود الصريحة
امنح GLM-5 دورًا صارمًا وقيودًا واضحة، خصوصًا لمهام الشيفرة أو استدعاء الأدوات. مثال:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
اطلب اختبارات وتفكيرًا موجزًا لكل تغيير غير بسيط.
تفكيك المهام المعقّدة
بدلًا من “اكتب المنتج بالكامل”، اطلب:
- مخطط التصميم،
- تواقيع الواجهات،
- التنفيذ والاختبارات،
- نص التكامل النهائي.
يقلّل هذا التفكيك من الهلوسة ويمنح نقاط تحقّق حتمية يمكنك التحقق منها.
استخدم درجة حرارة منخفضة للحصول على شيفرة حتمية
عند طلب الشيفرة، اضبط temperature = 0–0.2 وmax_tokens لحد أعلى آمن. للكتابة الإبداعية أو العصف الذهني للتصميم، ارفع درجة الحرارة.
أفضل الممارسات عند دمج GLM-5 (عبر CometAPI أو الاستضافة المباشرة)
هندسة التوجيهات وتوجيهات النظام
- استخدم تعليمات النظام الصريحة التي تحدّد أدوار الوكلاء وسياسات الوصول إلى الأدوات وقيود السلامة. مثال: “أنت مهندس نظم: لا تقترح تغييرات إلا عندما تجتاز الاختبارات الوحدوية محليًا؛ اذكر أوامر CLI الدقيقة للتشغيل.”
- لمهام الترميز، قدّم سياق المستودع (قوائم الملفات، مقتطفات الشيفرة الأساسية) وأرفق مخرجات الاختبارات إن توفّرت. يساعد تعامل GLM-5 مع السياق الطويل — لكن دائمًا حافظ على السياق الأساسي أولًا (الدور، المهمة) ثم المواد الداعمة.
إدارة الجلسات والحالة
- استخدم معرفات جلسة للمحادثات الطويلة للوكلاء واحتفظ بذاكرة “مضغوطة” للخطوات السابقة (ملخّصات) لمنع انتفاخ السياق. توفّر CometAPI وبوابات مشابهة مساعدات للجلسات/الحالة — لكن ضغط الحالة على مستوى التطبيق ضروري للوكلاء طويل التشغيل.
- دوّن سياقًا موجزًا للقرارات والنتائج الرئيسية بعد كل خطوة لتسهل الاستئناف والاسترجاع.
الأدوات واستدعاءات الوظائف (السلامة + الاعتمادية)
- عرّض مجموعة أدوات ضيقة وقابلة للتدقيق. لا تسمح بتنفيذ صدفة/أوامر عامة دون إشراف بشري. استخدم تعريفات وظائف مُهيكلة وتحقق من وسيطاتها في الخادم.
- سجّل دائمًا استدعاءات الأدوات واستجابات النموذج لأغراض التتبع وتصحيح الأخطاء بعد الحدث.
ضبط التكلفة والتجميع
- للوكيلات عالية الحجم، وجّه المعالجة الخلفية إلى متغيرات نموذج أرخص عندما تكون مفاضلات الجودة مقبولة (يتيح لك CometAPI تبديل النماذج بالاسم). جمّع الطلبات المتشابهة وقلّص
max_tokensحيثما أمكن. راقب نسبة رموز الإدخال مقابل الإخراج — غالبًا ما تكون رموز الإخراج أغلى. - راقب استخدام السياق الطويل وقلّم التاريخ غير الضروري بانتظام لتجنّب تكلفة زائدة.
هندسة الكمون ومعدل النقل
- استخدم البثّ للجلسات التفاعلية. للوظائف الخلفية، فضّل البيئات غير المتزامنة، طوابير العمال، ومحددات المعدل. إن قمت بالاستضافة الذاتية (أوزان مفتوحة)، اضبط طوبولوجيا المسرّعات وفق بنية MoE — قد توفّر خيارات مثل FPGA / Ascend / سيليكون متخصّص مكاسب تكلفة.
ملاحظات ختامية
يمثّل GLM-5 خطوة عملية مفتوحة الأوزان نحو الهندسة المعتمدة على الوكلاء: نوافذ سياق كبيرة، قدرات تخطيط، وأداء قوي في الشيفرة تجعل منه خيارًا جذابًا لأدوات المطورين، تنسيق الوكلاء، والأتمتة على مستوى النظام. استخدم CometAPI لدمج سريع أو حدائق نماذج سحابية للاستضافة المُدارة؛ تحقق دائمًا على عبء عملك وادره بعناية للسيطرة على التكلفة والهلوسة.
يمكن للمطورين الوصول إلى GLM-5 عبر CometAPI الآن. للبدء، استكشف قدرات النموذج في Playground واطلع على API guide للحصول على تعليمات مفصّلة. قبل الوصول، يرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. CometAPI تقدّم سعرًا أقل بكثير من السعر الرسمي لمساعدتك على الاندماج.
هل أنت جاهز؟→ سجّل في M2.5 اليوم!
إذا أردت المزيد من النصائح، الأدلة، والأخبار حول الذكاء الاصطناعي فاتبعنا على VK، X وDiscord!