

في 17 يونيو، قامت شركة شنغهاي للذكاء الاصطناعي يونيكورن MiniMax رسميًا بفتح المصدر ميني ماكس-M1، أول نموذج استدلال انتباه هجين واسع النطاق ومفتوح الوزن في العالم. بدمج بنية مزيج الخبراء (MoE) مع آلية Lightning Attention الجديدة، يُحقق MiniMax‑M1 تحسنًا كبيرًا في سرعة الاستدلال، ومعالجة السياقات فائقة الطول، وأداء المهام المعقدة.
الخلفية والتطور
بناء على أساس ميني ماكس-نص-01، الذي قدّم اهتمامًا فائقًا بإطار عمل مزيج الخبراء (MoE) لتحقيق سياقات بمليون رمز أثناء التدريب وما يصل إلى 1 ملايين رمز عند الاستدلال، يُمثّل MiniMax-M4 الجيل التالي من سلسلة MiniMax-1. احتوى النموذج السابق، MiniMax-Text-01، على 01 مليار معلمة إجمالية، مع 456 مليار مُفعّل لكل رمز، مما يُظهر أداءً يُضاهي أفضل أنظمة إدارة التعلم (LLM) مع توسيع قدرات السياق بشكل كبير.
الميزات الرئيسية لـ MiniMax‑M1
- هجين MoE + Lightning Attention:يدمج MiniMax‑M1 تصميم مزيج الخبراء المتناثر - 456 مليار معلمة إجمالية، ولكن 45.9 مليار فقط يتم تنشيطها لكل رمز - مع Lightning Attention، وهو انتباه ذو تعقيد خطي محسّن للتسلسلات الطويلة جدًا.
- سياق طويل للغاية: يدعم ما يصل إلى 1 مليون رموز الإدخال - حوالي ثمانية أضعاف الحد الأقصى البالغ 128 كيلو بايت لـ DeepSeek‑R1 - مما يتيح فهمًا عميقًا للمستندات الضخمة.
- كفاءة فائقة:عند إنشاء 100 ألف رمز، يتطلب Lightning Attention الخاص بـ MiniMax‑M1 حوالي 25-30% فقط من الحوسبة المستخدمة بواسطة DeepSeek‑R1.
المتغيرات النموذجية
- ميني ماكس-M1-40K:1 مليون سياق رمزي، و40 ألف ميزانية استدلال رمزي
- ميني ماكس-M1-80K:1 مليون سياق رمزي، و80 ألف ميزانية استدلال رمزي
في سيناريوهات استخدام أداة TAU‑bench، تفوقت النسخة 40K على جميع النماذج ذات الوزن المفتوح - بما في ذلك Gemini 2.5 Pro - مما يدل على قدراتها كوكيل.
تكلفة التدريب والإعداد
تم تدريب MiniMax-M1 من البداية إلى النهاية باستخدام التعلم التعزيزي واسع النطاق عبر مجموعة متنوعة من المهام، بدءًا من التفكير الرياضي المتقدم ووصولًا إلى بيئات هندسة البرمجيات القائمة على بيئة تجريبية. خوارزمية جديدة، سيسبو (أخذ عينات الأهمية المقصوصة لتحسين السياسات)، يُحسّن كفاءة التدريب بشكل أكبر من خلال اقتطاع أوزان أخذ العينات ذات الأهمية بدلاً من التحديثات على مستوى الرمز. سمح هذا النهج، بالإضافة إلى سرعة استجابة النموذج، بإكمال تدريب التعلم المعزز الكامل على 512 وحدة معالجة رسومية من طراز H800 في ثلاثة أسابيع فقط بتكلفة إيجار إجمالية قدرها 534,700 دولار أمريكي.
التوفر والتسعير
تم إصدار MiniMax-M1 بموجب أباتشي 2.0 ترخيص مفتوح المصدر ويمكن الوصول إليه فورًا عبر:
- مستودع جيثب، بما في ذلك أوزان النماذج، ونصوص التدريب، ومعايير التقييم.
- سيليكون كلاود الاستضافة، التي تقدم نوعين - 40 ألف رمز ("M1‑40K") و80 ألف رمز ("M1‑80K") - مع خطط لتمكين مسار الرمز 1 مليون بالكامل.
- تم تحديد التسعير حاليًا عند ¥4 لكل مليون رموز للإدخال و ¥16 لكل مليون رموز للإخراج، مع خصومات على الحجم متاحة لعملاء المؤسسات.
يمكن للمطورين والمؤسسات دمج MiniMax-M1 عبر واجهات برمجة التطبيقات القياسية، أو ضبط البيانات الخاصة بالنطاق، أو النشر محليًا لأحمال العمل الحساسة.
الأداء على مستوى المهمة
| فئة المهمة | تسليط الضوء | الأداء النسبي |
|---|---|---|
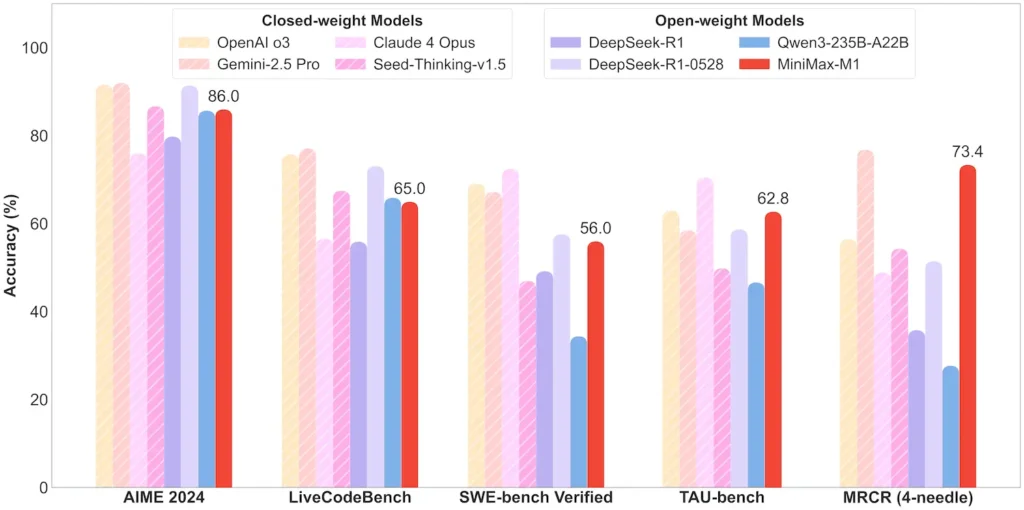
| الرياضيات والمنطق | AIME 2024: 86.0% | > Qwen 3، DeepSeek‑R1؛ مصدر مغلق تقريبًا |
| فهم السياق الطويل | المسطرة (4 رموز K–1 M): مستوى أعلى مستقر | يتفوق على GPT‑4 بما يتجاوز طول الرمز المميز 128 كيلو بايت |
| هندسة البرمجيات | SWE‑bench (أخطاء GitHub الحقيقية): 56% | الأفضل بين النماذج المفتوحة؛ الثاني بعد النماذج المغلقة الرائدة |
| استخدام الوكيل والأداة | اختبار TAU (محاكاة واجهة برمجة التطبيقات) | 62-63.5% مقابل الجوزاء 2.5، كلود 4 |
| الحوار والمساعد | التحدي المتعدد: 44.7% | مباريات كلود 4، DeepSeek‑R1 |
| حقيقة ضمان الجودة | SimpleQA: 18.5% | مجال للتحسين المستقبلي |
ملاحظة: النسب والمعايير من الإفصاح الرسمي لشركة MiniMax وتقارير الأخبار المستقلة
الابتكارات التقنية
- مجموعة الاهتمام الهجينة: انتباه البرق الطبقات (التكلفة الخطية) المتداخلة مع Softmax Attention الدوري (التربيعي ولكن أكثر تعبيرًا) لتحقيق التوازن بين الكفاءة وقوة النمذجة.
- توجيه وزارة التعليم المتفرق:32 وحدة خبيرة؛ كل رمز ينشط حوالي 10% فقط من إجمالي المعلمات، مما يقلل من تكلفة الاستدلال مع الحفاظ على السعة.
- التعلم المعزز CISPO:خوارزمية جديدة لتحسين سياسة الوزن المقطوع IS" تحتفظ بالرموز النادرة ولكن المهمة في إشارة التعلم، مما يؤدي إلى تسريع استقرار التعلم التعزيزي وسرعته.
يتيح إصدار MiniMax‑M1 المفتوح الوزن إمكانية الاستدلال عالي الكفاءة في سياق طويل للغاية للجميع - مما يسد الفجوة بين البحث والذكاء الاصطناعي القابل للنشر على نطاق واسع.
كيف تبدأ
يوفر CometAPI واجهة REST موحدة تجمع مئات نماذج الذكاء الاصطناعي، بما في ذلك عائلة ChatGPT، ضمن نقطة نهاية موحدة، مع إدارة مدمجة لمفاتيح واجهة برمجة التطبيقات، وحصص الاستخدام، ولوحات معلومات الفواتير. بدلاً من إدارة عناوين URL وبيانات اعتماد متعددة للموردين.
للبدء، استكشف قدرات النماذج في ملعب واستشر دليل واجهة برمجة التطبيقات للحصول على تعليمات مفصلة. قبل الدخول، يُرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API.
ستظهر أحدث واجهة برمجة تطبيقات MiniMax‑M1 للتكامل قريبًا على CometAPI، لذا ترقبوا ذلك! بينما ننتهي من تحميل نموذج MiniMax‑M1، استكشف نماذجنا الأخرى على صفحة النماذج أو جربهم في ملعب AI. أحدث طراز من MiniMax في CometAPI هو واجهة برمجة تطبيقات Minimax ABAB7-Preview و واجهة برمجة تطبيقات MiniMax Video-01 ،الرجوع إلى:
