تم تصميم Gemini 2.5 Flash لتقديم استجابات سريعة دون المساس بجودة المخرجات. يدعم إدخالات متعددة الوسائط، بما في ذلك النصوص والصور والصوت والفيديو، ما يجعله مناسبًا لتطبيقات متنوعة. يمكن الوصول إلى النموذج عبر منصات مثل Google AI Studio وVertex AI، موفّرًا للمطورين الأدوات اللازمة لدمجه بسلاسة في مختلف الأنظمة.
المعلومات الأساسية (الميزات)
يقدم Gemini 2.5 Flash عدة ميزات بارزة تميّزه ضمن عائلة Gemini 2.5:
- الاستدلال الهجين: يمكن للمطورين ضبط معامل thinking_budget للتحكم بدقة في عدد الرموز التي يخصصها النموذج للاستدلال الداخلي قبل الإخراج.
- حد بارِتو: يتموضع عند نقطة التكلفة مقابل الأداء المثلى، ويقدّم Flash أفضل نسبة السعر إلى الذكاء بين نماذج 2.5.
- دعم متعدد الوسائط: يعالج النص والصور والفيديو والصوت أصلاً، ما يتيح قدرات حوارية وتحليلية أغنى.
- سياق بطول 1 مليون رمز: يتيح طول السياق غير المسبوق تحليلًا عميقًا وفهمًا لوثائق طويلة ضمن طلب واحد.
إصدارات النموذج
مرّ Gemini 2.5 Flash عبر الإصدارات الرئيسية التالية:
- gemini-2.5-flash-lite-preview-09-2025: تحسين سهولة استخدام الأدوات: تم تحسين الأداء في المهام المعقدة متعددة الخطوات، مع زيادة بنسبة 5% في درجات SWE-Bench Verified (من 48.9% إلى 54%). تحسين الكفاءة: عند تفعيل الاستدلال، يتم تحقيق مخرجات أعلى جودة باستخدام عدد أقل من الرموز، ما يقلل زمن الاستجابة والتكاليف.
- Preview 04-17: إصدار وصول مبكر بقدرة «التفكير»، متاح عبر gemini-2.5-flash-preview-04-17.
- Stable General Availability (GA): اعتبارًا من 17 يونيو 2025، يستبدل الطرف النهائي المستقر gemini-2.5-flash إصدار المعاينة، مع ضمان موثوقية على مستوى الإنتاج ودون أي تغييرات على API مقارنةً بمعاينة 20 مايو.
- Deprecation of Preview: كان من المقرر إيقاف نقاط نهاية المعاينة في 15 يوليو 2025؛ ويجب على المستخدمين الانتقال إلى نقطة نهاية GA قبل هذا التاريخ.
اعتبارًا من يوليو 2025، أصبح Gemini 2.5 Flash متاحًا علنًا ومستقرًا (دون تغييرات مقارنةً بـ gemini-2.5-flash-preview-05-20). إذا كنت تستخدم gemini-2.5-flash-preview-04-17، فستستمر تسعيرة المعاينة الحالية حتى موعد إيقاف نقطة نهاية النموذج في 15 يوليو 2025، حين سيتم إيقافها. يمكنك الانتقال إلى النموذج المتاح عمومًا "gemini-2.5-flash".
أسرع، أرخص، أذكى:
- أهداف التصميم: زمن وصول منخفض + إنتاجية عالية + تكلفة منخفضة؛
- تسريع شامل في الاستدلال ومعالجة الوسائط المتعددة والمهام ذات النصوص الطويلة؛
- انخفض استهلاك الرموز بنسبة 20–30%، ما يقلل بشكل ملحوظ تكاليف الاستدلال.
المواصفات التقنية
نافذة سياق الإدخال: تصل إلى 1 مليون رمز، ما يتيح الاحتفاظ بسياق واسع.
رموز الإخراج: قادرة على توليد ما يصل إلى 8,192 رمزًا لكل استجابة.
الوسائط المدعومة: نصوص وصور وصوت وفيديو.
منصات التكامل: متاحة عبر Google AI Studio وVertex AI.
التسعير: نموذج تسعير تنافسي قائم على الرموز، مما يسهل النشر بتكلفة فعالة.
التفاصيل التقنية
على المستوى الداخلي، يعد Gemini 2.5 Flash نموذج لغة ضخمًا قائمًا على Transformer تم تدريبه على مزيج من بيانات الويب والشفرة والصور والفيديو. تشمل المواصفات التقنية الرئيسية ما يلي:
التدريب متعدد الوسائط: تم تدريبه على مواءمة وسائط متعددة، ويمكن لـ Flash مزج النص مع الصور أو الفيديو أو الصوت بسلاسة، وهو ما يفيد في مهام مثل تلخيص الفيديو أو إنشاء تسميات توضيحية للصوت.
عملية تفكير ديناميكية: يطبق حلقة استدلال داخلية يخطط فيها النموذج ويجزّئ المطالبات المعقدة قبل الإخراج النهائي.
ميزانيات تفكير قابلة للتهيئة: يمكن ضبط قيمة thinking_budget من 0 (من دون استدلال) وحتى 24,576 رمزًا، مما يتيح الموازنة بين زمن الوصول وجودة الإجابات.
تكامل الأدوات: يدعم Grounding with Google Search وCode Execution وURL Context وFunction Calling، مما يتيح تنفيذ إجراءات في العالم الحقيقي مباشرة من المطالبات باللغة الطبيعية.
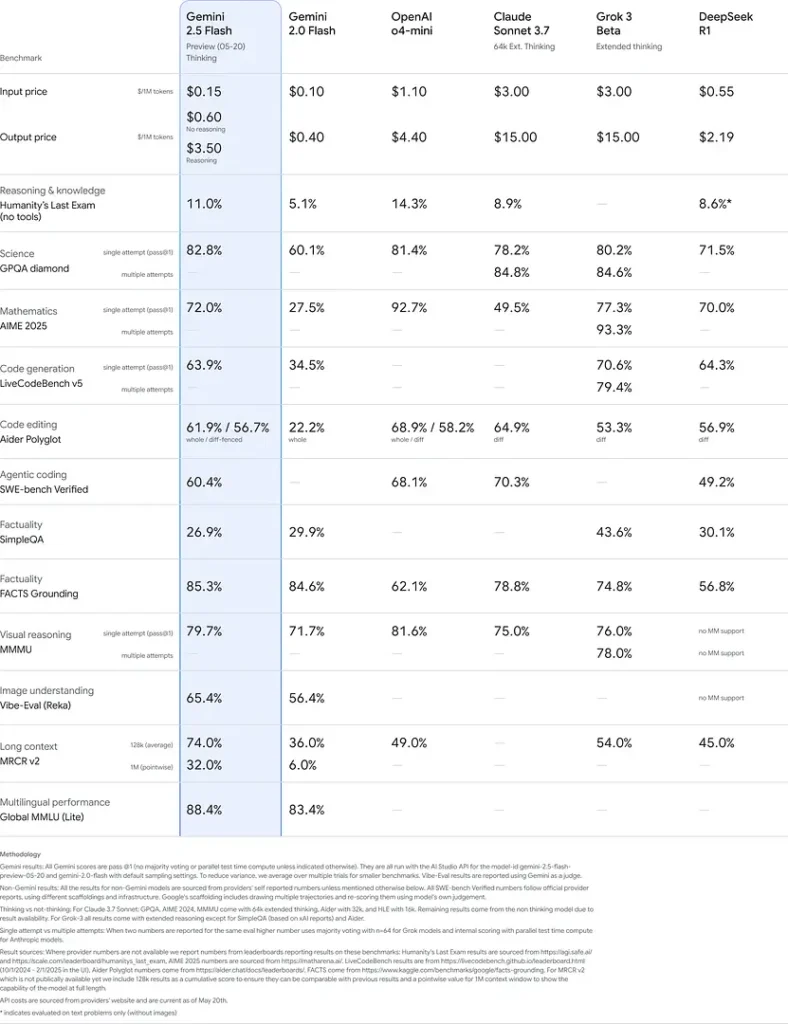
أداء المقاييس القياسية
في تقييمات صارمة، يُظهر Gemini 2.5 Flash أداءً رائدًا على مستوى الصناعة:
- LMArena Hard Prompts: حقق المركز الثاني بعد 2.5 Pro فقط على مقياس Hard Prompts الصعب، ما يبرز قدرات قوية على الاستدلال متعدد الخطوات.
- درجة MMLU تبلغ 0.809: يتجاوز متوسط أداء النماذج بدقة MMLU قدرها 0.809، ما يعكس معارفه الواسعة عبر المجالات وبراعته في الاستدلال.
- الكمون والإنتاجية: يحقق سرعة فك ترميز تبلغ 271.4 tokens/sec مع 0.29 s Time-to-First-Token، ما يجعله مثاليًا لأعباء العمل الحساسة للكمون.
- الريادة في السعر مقابل الأداء: عند \$0.26/1 M tokens، يتفوّق Flash على العديد من المنافسين مع مجاراتهم أو تجاوزهم في المقاييس الرئيسية.
تشير هذه النتائج إلى تفوق Gemini 2.5 Flash التنافسي في الاستدلال، والفهم العلمي، وحل المسائل الرياضية، والبرمجة، والتفسير البصري، والقدرات متعددة اللغات:
القيود
على الرغم من قوته، يحمل Gemini 2.5 Flash بعض القيود:
- مخاطر السلامة: قد يُظهر النموذج نبرة «وعظية» وقد ينتج مخرجات تبدو معقولة لكنها غير صحيحة أو متحيزة (هلوسات)، خصوصًا في الاستعلامات الطرفية. وتظل الرقابة البشرية الصارمة ضرورية.
- حدود المعدل: يخضع استخدام API لقيود في المعدل (10 RPM، و250,000 TPM، و250 RPD في الطبقات الافتراضية)، ما قد يؤثر في المعالجة الدُفعية أو التطبيقات عالية الحجم.
- حد أدنى للذكاء: على الرغم من قدراته الاستثنائية كنموذج Flash، يظل أقل دقة من 2.5 Pro في أكثر المهام القائمة على الوكلاء تطلبًا مثل البرمجة المتقدمة أو التنسيق متعدد الوكلاء.
- مقايضات التكلفة: رغم تقديمه أفضل سعر مقابل أداء، فإن الاستخدام المكثف لوضع التفكير يزيد الاستهلاك الإجمالي للرموز، ما يرفع التكاليف للمطالبات التي تتطلب استدلالًا عميقًا.