

في ظل التطور السريع للذكاء الاصطناعي، شهد عام 2025 تطورات ملحوظة في نماذج اللغات الكبيرة (LLMs). ومن بين النماذج الرائدة نموذج Qwen2.5 من Alibaba، ونموذجي V3 وR1 من DeepSeek، وChatGPT من OpenAI. يقدم كل نموذج من هذه النماذج قدرات وابتكارات فريدة. تتناول هذه المقالة أحدث التطورات المتعلقة بنموذج Qwen2.5، بمقارنة ميزاته وأدائه مع DeepSeek وChatGPT لتحديد النموذج الذي يتصدر حاليًا سباق الذكاء الاصطناعي.
ما هو Qwen2.5؟
نظرة عامة
Qwen 2.5 هو أحدث نموذج لغوي كبير وكثيف من Alibaba Cloud، يعتمد على فك التشفير فقط، ويتوفر بأحجام متعددة تتراوح من 0.5 مليار إلى 72 مليار معلمة. وهو مُحسّن لمتابعة التعليمات، والمخرجات المنظمة (مثل JSON والجداول)، والترميز، وحل المسائل الرياضية. مع دعمه لأكثر من 29 لغة وطول سياق يصل إلى 128 ألف رمز، صُمم Qwen2.5 للتطبيقات متعددة اللغات والمتخصصة في المجالات.
الميزات الرئيسية
- دعم متعدد اللغات:يدعم أكثر من 29 لغة، لتلبية احتياجات قاعدة المستخدمين العالمية.
- طول السياق الممتد:يتعامل مع ما يصل إلى 128 ألف رمز، مما يتيح معالجة المستندات والمحادثات الطويلة.
- المتغيرات المتخصصة:يتضمن نماذج مثل Qwen2.5-Coder لمهام البرمجة و Qwen2.5-Math لحل المشكلات الرياضية.
- سهولة الوصول والشمولية:متوفر من خلال منصات مثل Hugging Face وGitHub وواجهة الويب التي تم إطلاقها حديثًا على دردشة.qwenlm.ai.
كيفية استخدام Qwen 2.5 محليًا؟
فيما يلي دليل خطوة بخطوة لـ دردشة 7 ب نقطة تفتيش؛ تختلف الأحجام الأكبر فقط في متطلبات وحدة معالجة الرسوميات.
1. المتطلبات الأساسية للأجهزة
| الموديل | ذاكرة الوصول العشوائي الافتراضية (VRAM) لـ 8 بت | vRAM لـ 4 بت (QLoRA) | حجم القرص |
|---|---|---|---|
| كوين 2.5‑7ب | 14 غيغابايت | 10 غيغابايت | 13 غيغابايت |
| كوين 2.5‑14ب | 26 غيغابايت | 18 غيغابايت | 25 غيغابايت |
تكفي بطاقة RTX 4090 واحدة (24 جيجابايت) لاستنتاج 7 بايت بدقة 16 بت كاملة؛ ويمكن لبطاقتين من هذا النوع أو تفريغ وحدة المعالجة المركزية بالإضافة إلى التكميم التعامل مع 14 بايت.
2. تركيب
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. نص الاستدلال السريع
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
(أراضي البوديساتفا) trust_remote_code=True العلم مطلوب لأن Qwen تشحن مخصصًا تضمين الوضع الدوراني غلاف.
4. الضبط الدقيق باستخدام LoRA
بفضل محولات LoRA ذات الكفاءة في استخدام المعلمات، يمكنك تدريب Qwen بشكل متخصص على حوالي 50 ألف زوج من المجالات (على سبيل المثال، المجال الطبي) في أقل من أربع ساعات على وحدة معالجة رسومية واحدة بسعة 24 جيجابايت:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
يمكن دمج ملف المحول الناتج (حوالي 120 ميجابايت) مرة أخرى أو تحميله عند الطلب.
اختياري: تشغيل Qwen 2.5 كواجهة برمجة التطبيقات
يعمل CometAPI كمركز مركزي لواجهات برمجة التطبيقات الخاصة بالعديد من نماذج الذكاء الاصطناعي الرائدة، مما يزيل الحاجة إلى التعامل مع العديد من موفري واجهات برمجة التطبيقات بشكل منفصل. كوميت ايه بي اي يُقدّم CometAPI سعرًا أقل بكثير من السعر الرسمي لمساعدتك على دمج واجهة برمجة تطبيقات Qwen، وستحصل على دولار واحد في حسابك بعد التسجيل وتسجيل الدخول! مرحبًا بك في CometAPI وتجربة التطبيق. للمطورين الذين يرغبون في دمج Qwen 1 في التطبيقات:
الخطوة 1: تثبيت المكتبات الضرورية:
bash
pip install requests
الخطوة 2: الحصول على مفتاح API
- انتقل إلى كوميت ايه بي اي.
- قم بتسجيل الدخول باستخدام حساب CometAPI الخاص بك.
- إختار ال لوحة المعلومات.
- انقر فوق "الحصول على مفتاح API" واتبع التعليمات لتوليد مفتاحك.
الخطوة الأولى: تنفيذ مكالمات API
استخدم بيانات اعتماد واجهة برمجة التطبيقات (API) لتقديم الطلبات إلى Qwen 2.5.استبدال باستخدام مفتاح CometAPI الفعلي الخاص بك من حسابك.
على سبيل المثال، في بايثون:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
يتيح هذا التكامل دمجًا سلسًا لإمكانيات Qwen 2.5 في تطبيقات مختلفة، مما يعزز الوظائف وتجربة المستخدم. حدد “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” نقطة النهاية لإرسال طلب واجهة برمجة التطبيقات (API) وتعيين نص الطلب. يمكن الحصول على طريقة الطلب ونصه من وثيقة واجهة برمجة التطبيقات (API) على موقعنا الإلكتروني. كما يوفر موقعنا اختبار Apifox لتسهيل الأمر عليك.
يرجى الرجوع إلى واجهة برمجة تطبيقات Qwen 2.5 Max للحصول على تفاصيل التكامل، قامت CometAPI بتحديث أحدث إصدار واجهة برمجة التطبيقات QwQ-32B.للحصول على مزيد من المعلومات حول النموذج في Comet API، يرجى الاطلاع على وثيقة API.
أفضل الممارسات والنصائح
| سيناريو | توصية مجاناً |
|---|---|
| أسئلة وأجوبة حول المستندات الطويلة | قم بتقسيم المقاطع إلى ≤16 ألف رمز واستخدم المطالبات المعززة بالاسترجاع بدلاً من سياقات 100 ألف الساذجة لتقليل زمن الوصول. |
| المخرجات المنظمة | أضف البادئة لرسالة النظام: You are an AI that strictly outputs JSON. تتميز عملية تدريب المحاذاة الخاصة بـ Qwen 2.5 بقدرتها على التوليد المقيد. |
| اكتمال الرمز | بكج temperature=0.0 و top_p=1.0 لتعظيم الحتمية، ثم قم بأخذ عينات من حزم متعددة (num_return_sequences=4) للتصنيف. |
| تصفية السلامة | استخدم حزمة التعابير العادية "Qwen‑Guardrails" مفتوحة المصدر من Alibaba أو text‑moderation‑004 من OpenAI كمحاولة أولى. |
القيود المعروفة لـ Qwen 2.5
- قابلية الحقن الفوري. تظهر عمليات التدقيق الخارجية معدلات نجاح كسر الحماية بنسبة 18% على Qwen 2.5‑VL - وهو تذكير بأن حجم النموذج الهائل لا يحمي من التعليمات المعادية.
- ضوضاء التعرف الضوئي على الحروف غير اللاتينية. عند ضبطها بدقة لمهام اللغة البصرية، فإن خط الأنابيب الشامل للنموذج يخلط أحيانًا بين الحروف الصينية التقليدية والحروف الصينية المبسطة، مما يتطلب طبقات تصحيح خاصة بالمجال.
- ذاكرة وحدة معالجة الرسوميات منخفضة للغاية عند 128 كيلو بايت. يقوم FlashAttention‑2 بإزاحة ذاكرة الوصول العشوائي (RAM)، ولكن تمريرة أمامية كثيفة بحجم 72 بايت عبر 128 ألف رمز لا تزال تتطلب >120 جيجابايت من ذاكرة الوصول العشوائي (VRAM)؛ يجب على الممارسين استخدام window‑attend أو KV‑cache.
خريطة الطريق والنظام البيئي المجتمعي
وقد ألمح فريق كوين إلى كوين 3.0يستهدف هيكل توجيه هجين (كثيف + MoE) وتدريبًا مسبقًا موحدًا للكلام والرؤية والنص. في الوقت نفسه، يستضيف النظام البيئي بالفعل:
- وكيل Q - وكيل سلسلة الأفكار على غرار ReAct باستخدام Qwen 2.5‑14B كسياسة.
- الألبكة المالية الصينية - LoRA على Qwen2.5‑7B المدرب باستخدام 1 مليون ملف تنظيمي.
- مكون إضافي لبرنامج Open Interpreter - تبديل GPT‑4 بنقطة تفتيش Qwen محلية في VS Code.
قم بزيارة صفحة "مجموعة Qwen2.5" من Hugging Face للحصول على قائمة محدثة باستمرار لنقاط التفتيش والمحولات وأشرطة التقييم.
تحليل مقارن: Qwen2.5 مقابل DeepSeek وChatGPT
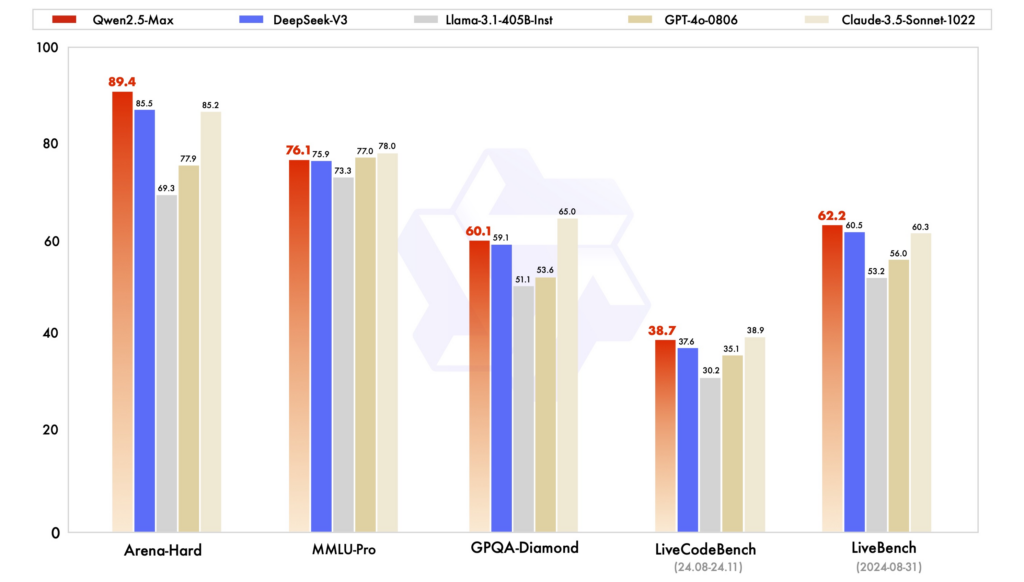
معايير الأداء: في تقييمات مختلفة، أظهر Qwen2.5 أداءً قويًا في المهام التي تتطلب التفكير المنطقي والترميز والفهم متعدد اللغات. يتميز DeepSeek-V3، ببنيته MoE، بالكفاءة وقابلية التوسع، موفرًا أداءً عاليًا بموارد حسابية أقل. ويظل ChatGPT نموذجًا قويًا، لا سيما في مهام اللغات متعددة الأغراض.
الكفاءة والتكلفة: تتميز نماذج DeepSeek بتدريبها واستنتاجها الفعالين من حيث التكلفة، مستفيدةً من بنى MoE لتفعيل المعلمات الضرورية فقط لكل رمز. يوفر Qwen2.5، على الرغم من كثافته، متغيرات متخصصة لتحسين الأداء لمهام محددة. تطلب تدريب ChatGPT موارد حسابية ضخمة، مما انعكس على تكاليفه التشغيلية.
إمكانية الوصول والتوفر مفتوح المصدر: تبنّى كلٌّ من Qwen2.5 وDeepSeek مبادئ المصدر المفتوح بدرجات متفاوتة، مع توفر نماذج على منصات مثل GitHub وHugging Face. يُحسّن إطلاق Qwen2.5 مؤخرًا لواجهة ويب من إمكانية الوصول إليه. ChatGPT، مع أنه ليس مفتوح المصدر، متاح على نطاق واسع من خلال منصة OpenAI وتكاملاتها.
الخاتمة
يقع Qwen 2.5 في مكان مثالي بين خدمات مميزة ذات وزن مغلق و نماذج هواة مفتوحة بالكاملإن مزيجها من الترخيص المتساهل، والقوة المتعددة اللغات، والكفاءة في السياق الطويل، ومجموعة واسعة من مقاييس المعلمات يجعلها أساسًا مقنعًا لكل من البحث والإنتاج.
مع تقدم مشهد LLM مفتوح المصدر، يوضح مشروع Qwen أن يمكن أن يتعايش الشفافية والأداءبالنسبة للمطورين وعلماء البيانات وصانعي السياسات على حد سواء، فإن إتقان Qwen 2.5 اليوم هو استثمار في مستقبل الذكاء الاصطناعي الأكثر تعددية وصديقًا للابتكار.