

Gemini Embedding 2 هو أول نموذج تضمين من Google يكون متعدد الوسائط أصيلاً، يقوم بإسقاط النصوص والصور والصوت والفيديو وملفات PDF في فضاء متجهات دلالي واحد بعدد 3,072 بعداً (مع أحجام مخرجات قابلة للضبط). ويقدم تعلم تمثيلات ماتريوشكا لتوفير تضمينات متداخلة/مبتورة، وتحسين الأداء متعدد اللغات (أكثر من 100 لغة)، وضوابط محسّنة لتضمينات مخصصة للمهام (مثلاً: task:search، task:code).
ما هو Gemini Embedding 2؟
Gemini Embedding 2 هو نموذج تضمين موحّد من Google يقوم بإسقاط مدخلات متعددة الوسائط — النصوص والصور والصوت والفيديو والوثائق — في فضاء دلالي واحد. كل تضمين هو (افتراضياً) متجه أعداد عائمة بعدده 3,072 بُعداً يمثل المعنى الدلالي للمدخل بحيث تكون العناصر المتشابهة دلالياً (بغض النظر عن الوسيط) متقاربة في الفضاء المتجهي. أبرز القدرات هي:
- تغطية واسعة للغات والصيغ: نموذج واحد يقبل النصوص والصور والصوت والفيديو والوثائق ويضعها في فضاء دلالي واحد. موثّق أن Gemini Embedding 2 يلتقط القصد الدلالي عبر أكثر من 100 لغة ويقبل الصيغ الشائعة (PNG/JPEG، MP4/MOV، MP3/WAV، PDF)، مع حدود ملموسة لكل طلب (مثلاً حتى عدد قليل من الصور أو عشرات الثواني من الصوت/الفيديو لكل طلب — انظر “كيفية الاستخدام” أدناه).
- تعدد وسائط حقيقي: نموذج واحد يقبل النصوص والصور والصوت والفيديو والوثائق ويضعها في فضاء دلالي واحد حتى تتمكن من المقارنة أو الاسترجاع عبر الوسائط (مثلاً نص → صورة، صوت → نص).
- بعدية افتراضية كبيرة مع بتر مرن: يُرجع النموذج متجهات بعدد 3072 بُعداً افتراضياً، لكنه يستخدم تعلم تمثيلات ماتريوشكا (MRL) لتركيز المحتوى الدلالي الأهم في الأبعاد الأولى بحيث يمكنك البتر إلى 1536 أو 768 (أو أقل) مع انخفاض طفيف فقط في جودة الاسترجاع. هذا يقلل تكاليف التخزين والحوسبة.
لماذا هذا مهم. تاريخياً كانت التضمينات في الغالب للنص فقط أو تتطلب مُرمِّزات منفصلة لكل وسيط مع طبقات محاذاة معقدة عبر الوسائط. يزيل Gemini Embedding 2 هذا الحاجز بدعم متعدد الصيغ أصلاً — بحيث يمكن لاستعلام نصي استرجاع صورة أو مقطعاً قصيراً بالتشابه الدلالي مباشرةً دون نسخ وسيط أو مواءمة يدوية. هذا يبسّط RAG (التوليد المعزز بالاسترجاع)، والبحث الدلالي، وخطوط أنابيب الاسترجاع متعدد الوسائط.
الميزات والإمكانات الرئيسية (ما الجديد)
1. تعدد وسائط حقيقي أصيل (فضاء تضمين واحد)
نموذج واحد يقبل النصوص والصور والصوت والفيديو والوثائق ويضعها في فضاء دلالي واحد. يقوم Gemini Embedding 2 بإسقاط النصوص والصور والصوت والفيديو والوثائق في نفس فضاء التضمين بحيث يعمل الاسترجاع عبر الوسائط مباشرةً (نص→صورة، صوت→نص) دون محاذاة عبر نماذج مختلفة. هذا يقلل تعقيد خطوط الأنابيب ويبسّط حزم RAG (التوليد المعزز بالاسترجاع).
2. متجهات افتراضية بعدد 3,072 مع مخرجات قابلة للضبط
يُرجع Gemini Embedding 2 متجهات بعدد 3072 بُعداً افتراضياً، لكنه يستخدم تعلم تمثيلات ماتريوشكا (MRL) لتركيز المحتوى الدلالي الأهم في الأبعاد الأولى بحيث يمكنك البتر إلى 1536، 768 (أو أقل) مع انخفاض طفيف فقط في جودة الاسترجاع. هذا يقلل تكاليف التخزين والحوسبة.
3. تعلم تمثيلات ماتريوشكا (MRL)
تنتج MRL تضمينات "متداخلة" — كدمى الماتريوشكا الروسية — بحيث تحافظ المقاطع الأقل بعداً على الدلالات العليا. يتيح ذلك للأنظمة اختيار نقطة تشغيل (مفاضلة التخزين/الدقة) دون الحفاظ على عدة نماذج تضمين منفصلة. تصف تحليلات المدونات المبكرة والوثائق هذه التقنية كابتكار أساسي للمرونة.
4. تلميحات للمهام / أهداف تضمين مخصصة
تقبل الواجهة البرمجية API تلميحات task (مثلاً، task:search، task:code retrieval، task:semantic-similarity) بحيث يمكن للنموذج تحسين هندسة فضاء التضمين لعلاقات مخصصة لمهام معينة — على غرار تكييف المهام في أنظمة التضمين السابقة ولكن ممتدة للمدخلات متعددة الوسائط.
5. اتساع اللغات والوسائط
موثّق أن Gemini Embedding 2 يلتقط القصد الدلالي عبر أكثر من 100 لغة ويقبل الصيغ الشائعة (PNG/JPEG، MP4/MOV، MP3/WAV، PDF)، مع حدود ملموسة لكل طلب (مثلاً حتى عدد قليل من الصور أو عشرات الثواني من الصوت/الفيديو لكل طلب — انظر “كيفية الاستخدام” أدناه).
معايير الأداء
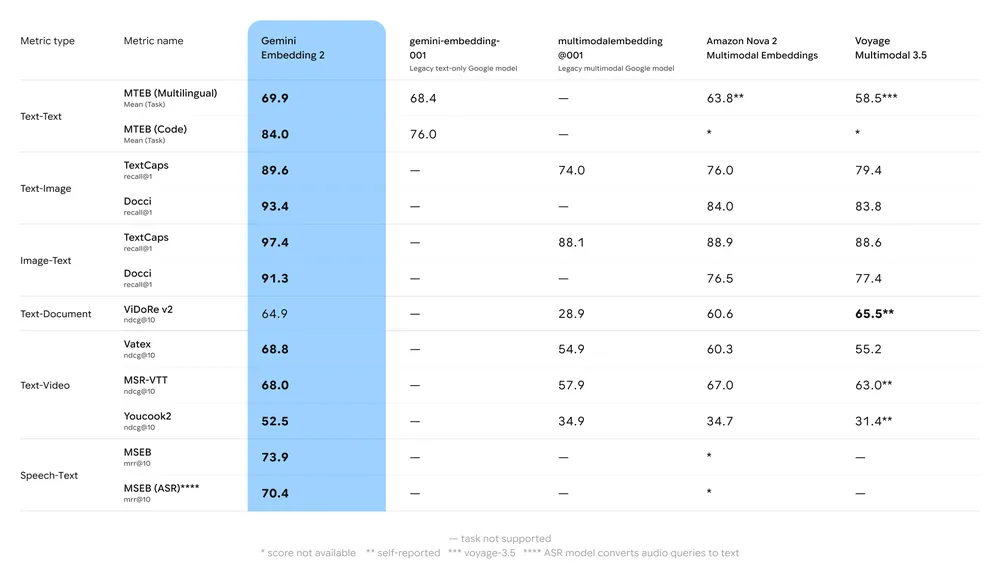
ملخص المعايير الرئيسية:
- MTEB (Massive Text Embedding Benchmark): تم الإبلاغ عن مراتب قوية على قوائم MTEB متعددة اللغات للمهام الإنجليزية ومتعددة اللغات؛ تُظهر التحليلات تحسناً ملموساً مقارنة بنماذج التضمين السابقة من Gemini والعديد من البدائل المملوكة.
- الاسترجاع متعدد الوسائط: يتفوق أو يضاهي أفضل التضمينات أحادية الوسيط عند استخدامه للتشابه عبر الوسائط (مثلاً، استرجاع نص→صورة)، بفضل التدريب متعدد الوسائط أصلاً.
- كمون وزمن معالجة: توليد التضمين مستضاف سحابياً، لكن حالات الاستخدام الحساسة للكمون قد تفضّل المتجهات المبتورة أو نماذج التضمين الخفيفة البديلة للاحتياجات على الطرفيات.
مقارنة بين Gemini Embedding 2 و gemini-embedding-001 و text-embedding-3-large
| السمة | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| الإطلاق/الإتاحة | 10 مارس 2026 — معاينة عامة (Gemini API / Vertex AI). | إصدار Gemini embedding الأقدم (متغيرات للنص أساساً) — GA في وقت سابق. | تم الإعلان في يناير 2024 (نص فقط GA). |
| الوسائط المدعومة | نصوص، صور، صوت، فيديو، وثائق (PDF) — فضاء متجه موحّد. | نص (أساساً). | نص فقط (متعدد لغات عالي الجودة). |
| البعد الافتراضي للتضمين | 3072 (MRL/البتر الموصى به: 1536، 768). | 3072 (للكبير) — نص فقط. | 3072 (text-embedding-3-large). |
| MTEB المُبلّغ (مثال) | في أواخر الستينيات على MTEB؛ يُظهر 68.17 عند 1536 في جدول المورّد (انظر الوثائق). | gemini-embedding-001 أبلغ عن متوسط ~68.32 في بعض جداول المتصدرين. | ~64.6 (المتوسط على MTEB كما أبلغت OpenAI لـ text-embedding-3-large). |
| دعم الصوت/الفيديو أصلاً | نعم (تضمين صوت/فيديو مباشر). | لا (نص فقط). | لا (نص فقط). |
| حالات الاستخدام النموذجية | استرجاع متعدد الوسائط، RAG، بحث دلالي عبر أنواع الملفات، استرجاع كلام، بحث فيديو. | استرجاع نصي، RAG متعدد اللغات. | استرجاع نصي، بحث دلالي، RAG — أداء قوي للنص متعدد اللغات. |
المواصفات التقنية والقيود
الحجم الافتراضي والقابل للتعديل للتضمين
- الافتراضي: 3,072 بُعداً.
- قابل للتعديل: يتيح معامل output_dimensionality طلب مخرجات بأبعاد أقل لتوفير التخزين/المعالجة. حالات الاستخدام ذات مخازن المتجهات الضخمة تخفّض الأبعاد غالباً إلى 512–1,024 لأسباب كلفة مع قبول بعض التنازل في الدقة.
الوسائط المدعومة والقيود لكل طلب
- الصور: PNG، JPEG — حتى 6 صور لكل طلب (حسب تقارير المورّد).
- الفيديو: MP4، MOV — يذكر المورّد حتى ~128 ثانية لكل فيديو في تضمين الطلب الواحد.
- الصوت: MP3، WAV — يذكر المورّد حتى ~80 ثانية لكل مدخل صوتي.
- الوثائق: PDF — حتى 6 صفحات لكل طلب (حسب تقارير المورّد).
- حدود الرموز للنص: يدعم النموذج مدخلات نصية كبيرة؛ توجد حدود عملية للرموز لكل طلب (تحقق من وثائق الواجهة وقيود Vertex AI).
التوفر والوصول
- معاينة عامة: تم إصدار Gemini Embedding 2 كمعاينة عامة ومتاح عبر Gemini API وVertex AI للاستخدام التجريبي الفوري
الأسئلة الشائعة (FAQ)
Q1: ما الوسائط التي يدعمها Gemini Embedding 2؟
A: نصوص، صور (PNG/JPEG)، فيديو (MP4/MOV)، صوت (MP3/WAV) ووثائق PDF — جميعها تُسقط في نفس الفضاء الدلالي للمتجهات.
Q2: ما حجم المتجه الافتراضي لـ Gemini Embedding 2؟
A: الافتراضي هو 3,072 بُعداً. يمكنك طلب بعدية أصغر للمخرجات عبر الواجهة البرمجية.
Q3: هل Gemini Embedding 2 متاح الآن؟
A: نعم — تم الإعلان عنه كمعاينة عامة وهو متاح عبر Gemini API وVertex AI (تحقق من معرّف النموذج gemini-embedding-2-preview وسجل التغييرات الحالي).
Q4: كيف يقارن مع التضمينات من مزودين آخرين؟
A: تفيد اختبارات جهات مستقلة بأن Gemini Embedding 2 يأتي ضمن أفضل النماذج المملوكة للنص متعدد اللغات ويظهر أداءً رائدًا في عدة مهام متعددة الوسائط. تختلف التصنيفات حسب المهمة ومجموعة البيانات؛ اختبر على بياناتك الخاصة.
Q5: هل سأحتاج إلى نسخ الصوت لاستخدام Gemini Embedding 2؟
A: لا — يمكن لـ Gemini Embedding 2 قبول الصوت مباشرةً وإنتاج تضمينات دون نسخ إلى نص أولاً، مما يمكّن استرجاعاً دلالياً للصوت طرفاً لطرف.
Q6: كيف أخفّض تكاليف التخزين لمتجهات 3,072 بُعداً؟
A: تتضمن الخيارات طلب output_dimensionality أقل، واستخدام float16/quantization/PQ، وتخزين تمثيلات مضغوطة في قاعدة بيانات المتجهات لديك. تنشر الجهة المورّدة مسارات عمل وأفضل الممارسات.
ما الخطوة التالية — هل ينبغي اعتماده الآن؟
يُعد Gemini Embedding 2 خطوة كبيرة نحو توحيد الاسترجاع متعدد الوسائط ويبسّط البنى التي كانت تتطلب سابقاً مسترجعات منفصلة للنص والرؤية والصوت. نقاط القرار الأساسية للاعتماد:
- اعتمد مبكراً إذا كان منتجك يحتاج إلى استرجاع قوي عبر الوسائط (نص↔صورة/فيديو/صوت)، أو إذا كان الحفاظ على عدة مسترجعات أحادية الوسيط مكلفاً ومعقداً.
- جرّب الآن إذا أردت تقييم بتر MRL وقياس الكلفة مقابل الجودة (حافظ على نشر هجين: 1536 كابتدائي، و3072 لإعادة الترتيب).
- انتظر إذا كان عبء العمل حساساً جداً للكلفة ولا يتطلب سوى الاسترجاع النصي — لا تزال النماذج النصية فقط الأعلى أداءً (مثلاً OpenAI text-embedding-3-large) تنافسية وأحياناً أرخص بحسب خط الأنابيب والعقد.
يمكن للمطورين الوصول إلى Gemini Embedding 2 وOpenAI text-embedding-3 عبر واجهة CometAPI الآن. للبدء، استكشف قدرات النموذج في Playground واطّلع على دليل API للحصول على تعليمات مفصلة. قبل الوصول، يرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. تقدم CometAPI سعراً أقل بكثير من السعر الرسمي لمساعدتك على الدمج.
Ready to Go?→ Sign up for cometapi today !
إذا أردت المزيد من النصائح والإرشادات وآخر أخبار الذكاء الاصطناعي، تابعنا على VK، وX وDiscord!