
.webp&w=3840&q=75)
يمثل GLM-5.1 تحولاً محورياً في مشهد الذكاء الاصطناعي. فمع تسارع الشركات الصينية في التسويق التجاري بالتوازي مع فتح المصدر للقدرات المتقدمة، يضيّق هذا النموذج الفجوة مع القادة المملوكين مثل GPT-5.4 من OpenAI وClaude Opus 4.6 من Anthropic وGemini 3.1 Pro من Google—لا سيما في هندسة البرمجيات الواقعية. وباعتماده على البنية نفسها ذات 744 مليار مُعامِل من نوع Mixture-of-Experts (MoE) المستخدمة في GLM-5، لكنه مُحسَّن بقوة لسير العمل الوكيلية، يتفوق حيث تتعثر معظم النماذج اللغوية: المهام الطويلة والغامضة والتكرارية التي تتطلب التخطيط والتجريب وتصحيح الأخطاء والتصحيح الذاتي عبر آلاف استدعاءات الأدوات.
الآن يدمج CometAPI كلاً من GLM-5.1 وGLM-5، كما يمكن للمطورين الاطلاع على نماذج غربية رائدة أخرى والوصول إليها بسعر واجهة برمجية منخفض جداً (وهو أيضاً من مزايا CometAPI مقارنةً بالمنافسين).
ما هو GLM-5.1؟
GLM-5.1 هو نموذج اللغة الرائد الأحدث من Z.ai وخطوتها التالية نحو أعمال البرمجيات الوكيلية طويلة الأفق. ووفقاً لـ Z.ai، فقد صُمم للمهام التي تحتاج تنفيذاً مستمراً بدلاً من ردود أحادية، ويتموضع كنموذج يمكنه التخطيط والتنفيذ والتنقيح والتسليم ضمن دورة تشغيل ممتدة واحدة. وتشير ملاحظات الإصدار من Z.ai إلى أن GLM-5.1 مبني على الضبط الخاضع للإشراف متعدد الأدوار، والتعلم التعزيزي، وإطار تقييم جودة العملية، وأنه يحسن الاستقرار والاتساق واستخدام الأدوات عبر المهام الممتدة.
تكتسب هذه الترسيمة أهميتها لأن GLM-5.1 لا يُباع كـ“مجرد نموذج محادثة آخر”. إنه موجّه لسير عمل هندسي يحتاج فيه النموذج إلى الحفاظ على الهدف، والتعامل مع الخطوات الوسيطة، والتعافي من الأخطاء من دون فقدان النسق؛ كنموذج للتخطيط الذاتي والتنفيذ المستدام وإصلاح العيوب وتكرار الاستراتيجيات—وهو طرح مختلف تماماً عن مساعد عابر أو مرافق ترميز قصير السياق.
تفصيل عملي مفيد: GLM-5.1 نصّي فقط، وهو مدعوم في GLM Coding Plan ويمكن استخدامه ضمن عملاء ترميز شائعة مثل Claude Code وOpenClaw، ما يجعله ذا صلة خاصة للفرق التي ترغب بإدخال نموذج ضمن سير عمل المطورين القائم بدلاً من استبداله.
المواصفات التقنية الأساسية (مورَّثة ومُهذَّبة من GLM-5):
- البنية: Mixture-of-Experts (MoE) بإجمالي 744 مليار مُعامِل وحوالي 40 مليار مُعامِل مُفعّل لكل استدلال.
- نافذة السياق: 203K–204.8K رمزاً (مع دعم حتى 131K رمز إخراج).
- التحسينات المفتاحية: DeepSeek Sparse Attention (DSA) لمعالجة فعّالة للسياقات الطويلة وتقليل تكاليف النشر؛ بنية تحتية متقدمة للتعلم التعزيزي غير المتزامن (عبر إطار “slime” من Z.ai) لتحسين ما بعد التدريب.
- التوفر: أوزان مفتوحة (ترخيص MIT على Hugging Face عبر zai-org/GLM-5.1)، وصول عبر واجهة Z.ai ومن خلال مجمّعات مثل CometAPI، ومتكامل ضمن أدوات GLM Coding Plan (متوافق مع Claude Code / OpenClaw).
على عكس نماذج GLM السابقة التي ركزت على الذكاء العام أو “vibe coding” القصير، يستهدف GLM-5.1 وكلاء مستقلين بمستوى الإنتاج. يمكنه التخطيط والتنفيذ والقياس وتصحيح الأخطاء والتكرار على مشاريع هندسية معقدة لساعات من دون تدخل بشري—قدرات تضعه في موقع منافس مباشر لعملاء الترميز المتخصصين من Anthropic وOpenAI.
تزامن الإصدار مع زيادة لسعر الواجهة البرمجية بنحو ~10% (رموز الإدخال ~$0.54/M، رموز الإخراج ~$4.40/M)، ومع ذلك يظل أرخص بكثير من نظرائه مثل Anthropic Opus 4.6 (أغلى بنسبة 250–470%).
أداء GLM-5.1 على المعايير
تضع Z.ai نموذج GLM-5.1 كأقوى نموذج مفتوح المصدر في العالم وضمن أفضل 3 عالمياً في الترميز الوكيلي. تأتي بيانات الأداء من تقييمات رسمية على SWE-Bench Pro وNL2Repo وTerminal-Bench 2.0 وسيناريوهات طويلة الأفق مخصصة.
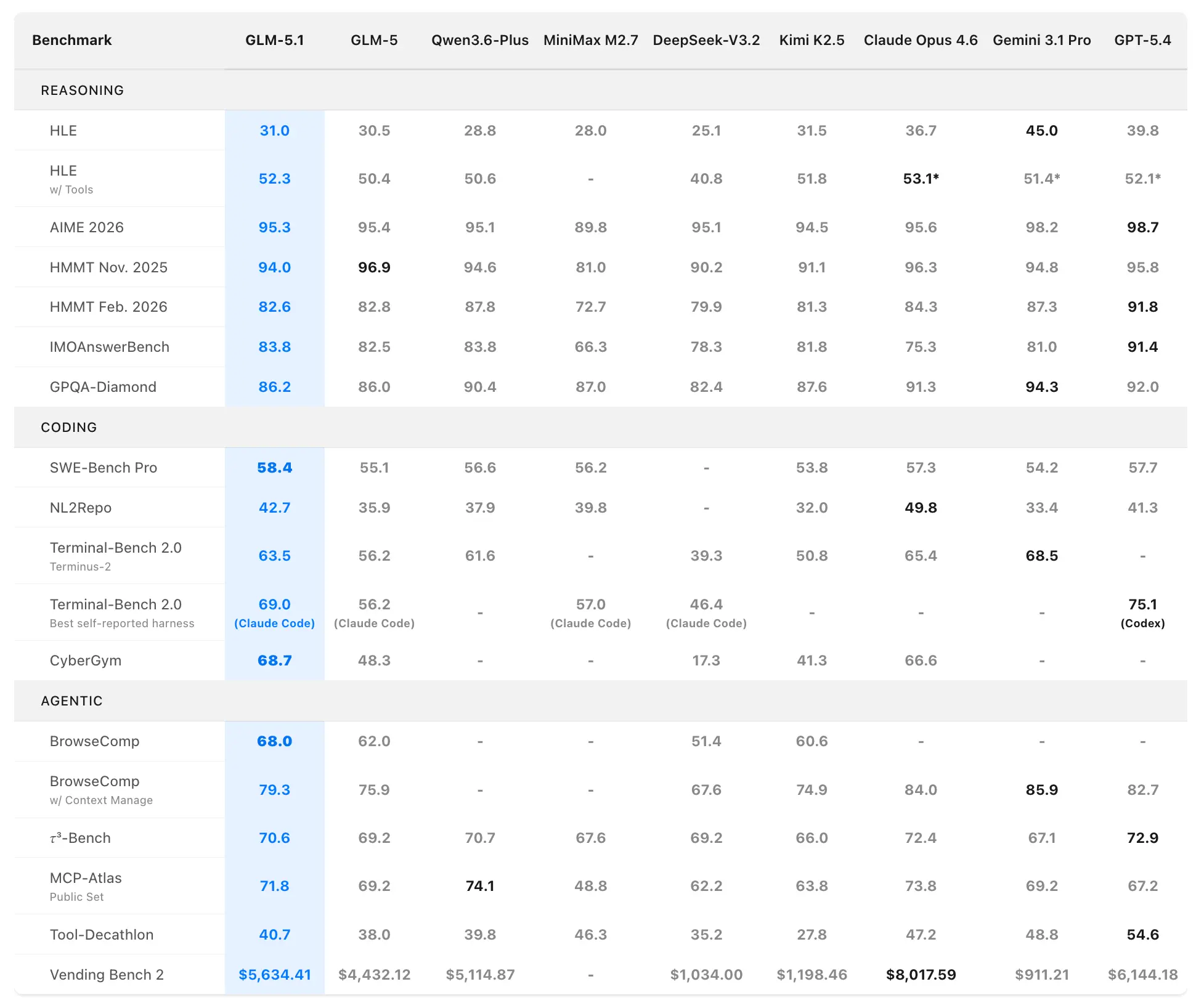
معايير الترميز والوكيلية
SWE-Bench Pro (مهام هندسة برمجيات واقعية تتطلب تصفّح المستودعات وتحرير الشيفرة والتحقق الوظيفي):
- GLM-5.1: 58.4 (أحدث رقم قياسي)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
يعد GLM-5.1 أول نموذج محلي (صيني) ومفتوح المصدر يعتلي الصدارة على هذا المعيار الصارم الذي يحاكي عن كثب سير عمل المطورين المحترفين.
NL2Repo (تحويل اللغة الطبيعية إلى مستودع كامل):
- GLM-5.1: 42.7 (تفوق واسع على GLM-5 الذي سجل 35.9)
- النماذج المنافسة تتراوح بين 32.0–49.8 (القادة المحددون يختلفون حسب بيئة القياس).
Terminal-Bench 2.0 (مهام حقيقية على الطرفية والأنظمة):
- بيئة Terminus-2: سجّل GLM-5.1 63.5 (مقابل 56.2 لـ GLM-5)
- أفضل نتيجة مُعلَن ذاتياً (Claude Code): حتى 69.0.
في تقييم بيئة ترميز منفصل (على نمط Claude Code)، سجّل GLM-5.1 45.3—ليصل إلى 94.6% من 47.9 الخاصة بـ Claude Opus 4.6، وبزيادة 28% على 35.4 الخاصة بـ GLM-5.
التصنيف المركب: الأول مفتوح المصدر، الأول صينياً، الثالث عالمياً عبر SWE-Bench Pro + NL2Repo + Terminal-Bench.
أداء المهام طويلة الأفق: عامل التميّز الحقيقي
تقيس المعايير القياسية الأداء أحادي اللقطة أو قصير الجلسة. يلمع GLM-5.1 في التشغيل الذاتي الممتد:
- تحسين VectorDBBench (أكثر من 600 تكرار، 6,000+ استدعاء أدوات): انطلاقاً من هيكل Rust أولي، أعاد GLM-5.1 تصميم الفهرسة والضغط والتوجيه والاقتطاع بشكل تكراري، محققاً 21.5k QPS (6× أفضل من أفضل نتيجة 50 دورة سابقة 3,547 QPS بواسطة Claude Opus 4.6) مع الحفاظ على ≥95% استرجاع على SIFT-1M. أظهر تقدماً “متدرجاً كالسلم” مع اختراقات هيكلية كل 100–200 تكرار.
- KernelBench المستوى 3 (تحسين نموذج تعلم آلي كامل، 1,000+ دورة): متوسط هندسي لتسريع قدره 3.6× عبر 50 مسألة معقدة (متجاوزاً 1.49× الخاصة بـ torch.compile max-autotune). واصل GLM-5.1 التحسن طويلاً بعد أن وصل GLM-5 إلى منصة؛ ولم يتفوق عليه سوى Claude Opus 4.6 بـ 4.2×.
- بناء تطبيق ويب لسطح مكتب Linux (أكثر من 8 ساعات، مفتوحة النهاية): معطىً له مطلب باللغة الطبيعية فقط ومن دون شيفرة بدء، بنى GLM-5.1 بشكل مستقل بيئة سطح مكتب بأسلوب Linux—مكتملة بشريط مهام ونوافذ وتفاعلات ولمسات جمالية—حيث لم تنتج النماذج السابقة سوى هياكل أساسية.
تُظهر هذه النتائج قدرة GLM-5.1 على الحفاظ على الاتساق، وتقييم الذات، ومراجعة الاستراتيجيات، والهرب من الحلول المحلية المثلى عبر آفاق طويلة جداً—وهي قدرات عملت Z.ai صراحةً على هندستها للأنظمة الوكيلية الواقعية.
كيف يختلف GLM-5.1 عن GLM-5؟
يرتبط GLM-5 وGLM-5.1 ارتباطاً وثيقاً، لكنهما لا يتموضعان بالشكل نفسه. GLM-5 هو نموذج الأساس الأسبق من Z.ai لأجل Agentic Engineering. وقد صُمم لهندسة الأنظمة المعقدة والمهام الوكيلية طويلة الأفق، مع ترميز SOTA مفتوح الأوزان وقدرات وكيلية متقدمة، وأداء ترميز يقترب من Claude Opus 4.5 في سيناريوهات البرمجة الواقعية. يسجل 77.8 على SWE-bench Verified و56.2 على Terminal Bench 2.0.
أما GLM-5.1، فيتم تقديمه باعتباره الخطوة التالية نحو المهام طويلة الأفق وتنفيذاً مستمراً أكثر موثوقية، مع تحسينات في الاستقرار والاتساق واستخدام الأدوات عبر المهام الممتدة، وهو أقرب مواءمةً إلى Claude Opus 4.6 إجمالاً. بعبارة أخرى، GLM-5 هو نموذج الأساس الهندسي الأسبق، بينما GLM-5.1 هو الرائد المخصص لتحمل المهام.
هناك أيضاً فروق معمارية وتدريبية في جيل GLM-5 تفسر هذه القفزة. فقد توسّع GLM-5 من 355B مُعامِلاً (32B مُفعّلة) إلى 744B مُعاملاً (40B مُفعّلة)، وزاد بيانات ما قبل التدريب من 23T إلى 28.5T، وأضاف إطار تعلم تعزيزي غير متزامن، ودمج DeepSeek Sparse Attention للحفاظ على جودة النصوص الطويلة مع تحسين الكفاءة. تشكّل هذه التفاصيل قاعدةً يبدو أن GLM-5.1 بُني عليها.
GLM-5.1 مقابل النماذج المتقدمة الأخرى
يبرز GLM-5.1 كأقوى منافس مفتوح المصدر مع عرض سعر/أداء جذاب.
جدول المقارنة: معايير الترميز والوكيلية الرئيسية (أبريل 2026)
| النموذج | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | درجة بيئة الترميز | استدامة طويلة الأفق؟ | مفتوح المصدر؟ | السعر التقريبي للواجهة البرمجية (لكل M من رموز الإدخال/الإخراج) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% من Opus) | نعم (600+ تكرار، 8 ساعات) | نعم | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | محدودة | نعم | أقل (قبل الزيادة) |
| GPT-5.4 | 57.7 | — | — | — | قوي | لا | أعلى |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | الأقوى | لا | ~أغلى بنسبة 250–470% |
| Gemini 3.1 Pro | 54.2 | — | — | — | جيد | لا | أعلى |
الخلاصة: يفوز GLM-5.1 في سهولة الوصول المفتوح المصدر والتكلفة ومقاييس الترميز طويلة الأفق المحددة. إنه ينافس القادة المغلقين المصدر في السيناريوهات الوكيلية بينما يُعمّم القدرات المتقدمة.
سيناريوهات استخدام GLM-5.1
1) هندسة البرمجيات الذاتية
يكون GLM-5.1 أكثر إقناعاً عندما تشبه المهمة سباقاً هندسياً حقيقياً: قراءة قاعدة الشيفرة، التخطيط للتغيير، التنفيذ، الاختبار، إصلاح الارتدادات، والاستمرار في التكرار حتى يصبح الناتج مستقراً. تؤكد ملاحظات إصدار Z.ai على التخطيط الذاتي والتنفيذ المستدام وإصلاح العيوب وتكرار الاستراتيجيات، ما يجعل النموذج يبدو مُصمماً خصيصاً لعملاء الترميز وخطوط تسليم البرمجيات.
2) سير عمل الوكلاء طويلة التشغيل
إذا كان استخدامك يتضمن العديد من استدعاءات الأدوات، وسير عمل متعدد الخطوات طويل، أو تصحيحاً ذاتياً متكرراً، فإن تصميم GLM-5.1 ملائم جداً. توضح الوثائق استدعاء الأدوات، المخرجات المُهيكلة، تكامل MCP، ودعم بثّ الأدوات—وهي أمور مفيدة عندما لا يكتفي النموذج بالإجابة بل يعمل داخل نظام أكبر.
3) أعمال المعرفة المؤسسية وإعداد التقارير
يُقدَّم GLM-5.1 أيضاً لمهام الإنتاجية المكتبية مثل PowerPoint وWord وPDF وExcel. تقول Z.ai إنه يُحسن تنظيم المحتوى المعقد وتصميم التخطيط والمخرجات المُهيكلة واللمسات البصرية، ما يجعله مناسباً لتوليد التقارير ومواد التدريس والملخصات البحثية وغيرها من الأعمال كثيفة الوثائق.
4) النمذجة الأولية للواجهات الأمامية والمخرجات
تقول Z.ai إن GLM-5.1 مناسب لتوليد مواقع الويب والصفحات التفاعلية والنمذجة الأولية للواجهات الأمامية، مع بنية أقل قوالبية وجودة إنجاز أفضل. يوحي ذلك بملاءمته لفرق المنتجات التي تحتاج جسراً سريعاً من الملخّص إلى نموذج أولي، خاصةً عندما يجب أن يكون النموذج قابلاً للاستخدام لا جميلاً فحسب.
5) محادثة معقدة والامتثال للتعليمات
على الرغم من أن القصة الأبرز هي الترميز، يوصف GLM-5.1 أيضاً بأنه أقوى في الأسئلة والأجوبة المفتوحة، والتعليمات المعقدة، والتفاعل متعدد الأدوار. يجعل ذلك منه مفيداً لسير عمل على نمط المساعد حيث يجب على النموذج تتبّع القيود، وتنقيح المخرجات، والحفاظ على السياق عبر محادثات أطول.
الخلاصة: لماذا يهم GLM-5.1 في 2026
GLM-5.1 ليس مجرد إصدار تدريجي آخر—إنه يُعلن وصول ذكاء اصطناعي وكيل مفتوح المصدر قادر فعلاً. من خلال تفوقه على أصعب معايير الهندسة الواقعية مع بقائه ميسور التكلفة ومفتوحاً، رفعت Z.ai سقف التوقعات للصناعة بأسرها. سواء كنت مطوراً منفرداً أو فريق مؤسسة أو باحثاً، يقدم GLM-5.1 استقلالية لا تضاهى لمهام الترميز طويلة الأفق بجزء بسيط من تكلفة النماذج المملوكة.
مستعد للتجربة؟ اطّلع على نموذج CometAPI GLM-5.1، مستودع Hugging Face، أو GLM Coding Plan للوصول الفوري.