

GPT-5.2 هو إصدار نقطة من OpenAI في ديسمبر 2025 ضمن عائلة GPT-5: عائلة نماذج متعددة الوسائط رائدة (نص + رؤية + أدوات) مخصصة لـ"العمل المعرفي الاحترافي، والاستدلال بسياق طويل، والاستخدام الوكيلي للأدوات، والهندسة البرمجية". تصف OpenAI GPT-5.2 بأنه الأكثر قدرة حتى الآن ضمن سلسلة GPT-5 وتقول إنه طُوِّر مع التركيز على الاستدلال متعدد الخطوات بشكل موثوق، والتعامل مع المستندات الكبيرة جدًا، وتحسين السلامة/الامتثال للسياسات؛ ويتضمن الإصدار ثلاثة متغيرات موجهة للمستخدم — Instant وThinking وPro — ويبدأ طرحه أولًا لمشتركي ChatGPT المدفوعين وعملاء واجهة البرمجة (API).
ما هو GPT-5.2 ولماذا يهم؟
GPT-5.2 هو أحدث عضو في عائلة GPT-5 — سلسلة نماذج "حدودية" جديدة صُممت خصيصًا لسد الفجوة بين المساعدين الحواريين أحاديي الدورة والأنظمة التي يجب أن تستدل عبر مستندات طويلة، وتستدعي الأدوات، وتفسر الصور، وتنفذ سير عمل متعددة الخطوات بشكل موثوق. تضع OpenAI الإصدار 5.2 باعتباره أكثر إصداراتها قدرة لأعمال المعرفة الاحترافية: فهو يحقق نتائج معيارية رائدة وفق اختباراتهم الداخلية (لا سيما معيار GDPval الجديد لأعمال المعرفة)، ويُظهر أداءً أقوى في الترميز على معايير الهندسة البرمجية، ويوفر قدرات محسّنة بشكل ملحوظ في السياق الطويل والرؤية.
عمليًا، GPT-5.2 أكثر من مجرد "نموذج دردشة أكبر". إنه عائلة من ثلاثة متغيرات مضبوطة (Instant وThinking وPro) توازن بين زمن الاستجابة وعمق الاستدلال والتكلفة — ويمكن استخدامها مع واجهة برمجة OpenAI وتوجيه ChatGPT لتشغيل مهام بحث طويلة، وبناء وكلاء يستدعون أدوات خارجية، وتفسير صور ورسوم معقدة، وتوليد شيفرة إنتاجية بدقة أعلى من الإصدارات السابقة. يدعم النموذج نوافذ سياق كبيرة جدًا (توثق مستندات OpenAI نافذة سياق 400,000 رمز وحد أقصى للإخراج 128,000 للطرز الرائدة)، وميزات API جديدة لمستويات جهد الاستدلال الصريحة، وسلوك استدعاء أدوات "وكِيلي" agentic.
5 قدرات أساسية تمت ترقيتها في GPT-5.2
1) هل GPT-5.2 أفضل في المنطق متعدد الخطوات والرياضيات؟
يقدم GPT-5.2 استدلالًا متعدد الخطوات أكثر حدة وأداءً أقوى بشكل ملحوظ في الرياضيات وحل المشكلات المُنظمة. تقول OpenAI إنها أضافت تحكمًا أدق في جهد الاستدلال (مستويات جديدة مثل xhigh)، وهندست دعم "رموز الاستدلال"، وضبطت النموذج للحفاظ على سلسلة التفكير عبر آثار استدلال داخلية أطول. تظهر المعايير مثل FrontierMath واختبارات على نمط ARC-AGI مكاسب جوهرية مقارنة بـ GPT-5.1؛ كما يحقق هوامش أكبر على معايير متخصصة بمجالات علمية ومالية. باختصار: GPT-5.2 "يفكّر أطول" عندما يُطلب منه ذلك، ويمكنه إنجاز عمل رمزي/رياضي أكثر تعقيدًا بثبات أفضل.

| RC-AGI-1 (Verified) الاستدلال المجرد | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) الاستدلال المجرد | 52.9% | 17.6% |
يسجل GPT-5.2 Thinking أرقامًا قياسية في عدة اختبارات متقدمة للعلوم والرياضيات:
- GPQA Diamond Science Quiz: 92.4% (إصدار Pro 93.2%)
- ARC-AGI-1 الاستدلال المجرد: 86.2% (أول نموذج يتخطى عتبة 90%)
- ARC-AGI-2 الاستدلال الأعلى ترتيبًا: 52.9%، مع رقم قياسي جديد لطراز Thinking Chain
- FrontierMath اختبار الرياضيات المتقدمة: 40.3%، متفوقًا بفارق كبير على سلفه
- HMMT مسائل مسابقة الرياضيات: 99.4%
- اختبار AIME للرياضيات: 100% حل كامل
علاوة على ذلك، يحقق GPT-5.2 Pro (High) ريادة الحالة على ARC-AGI-2، مسجلًا 54.2% بتكلفة 15.72$ لكل مهمة! متفوقًا على جميع النماذج الأخرى.
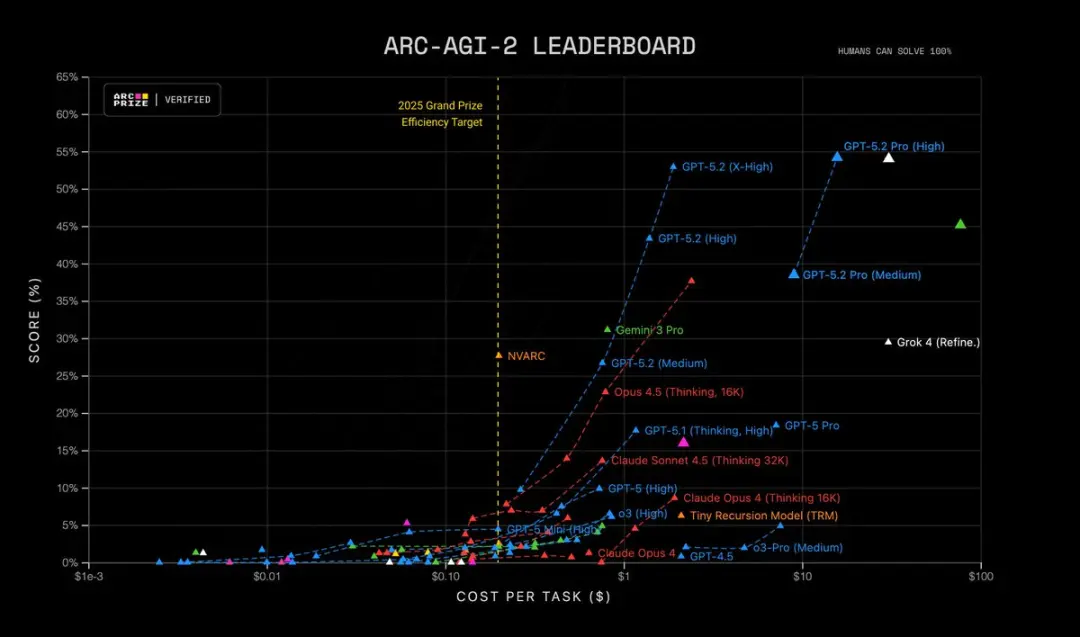
لماذا يهم هذا: العديد من المهام الواقعية — مثل النمذجة المالية، وتصميم التجارب، وتوليد البرامج الذي يتطلب استدلالًا رسميًا — اختناقها هو قدرة النموذج على ربط العديد من الخطوات الصحيحة. يقلل GPT-5.2 من "الخطوات المتوهمة" ويُنتج آثار استدلال وسيطة أكثر استقرارًا عندما تطلب منه إظهار خطواته.
2) كيف تحسّن فهم النصوص الطويلة والاستدلال عبر المستندات؟
يُعد فهم السياق الطويل من أبرز التحسينات. يدعم النموذج الأساسي في GPT-5.2 نافذة سياق 400 ألف رمز — والأهم — يحافظ على دقة أعلى مع انتقال المحتوى ذي الصلة عميقًا داخل ذلك السياق. في GDPval، وهي حزمة مهام لـ"أعمال معرفة مُحَدَّدة جيدًا" عبر 44 مهنة، يصل GPT-5.2 Thinking إلى التكافؤ أو أفضل من الحكام الخبراء البشر في نسبة كبيرة من المهام. تؤكد تقارير مستقلة أن النموذج يحتفظ بالمعلومات ويُركّبها عبر العديد من المستندات أفضل بكثير من النماذج السابقة. هذه قفزة عملية حقيقية لمهام مثل العناية الواجبة، والتلخيص القانوني، ومراجعات الأدبيات، وفهم قواعد الشيفرة.
يمكن لـ GPT-5.2 التعامل مع سياقات تصل إلى 256,000 رمز (ما يعادل تقريبًا 200+ صفحة من المستندات). علاوة على ذلك، في اختبار "OpenAI MRCRv2" لفهم النصوص الطويلة، حقق GPT-5.2 Thinking معدل دقة يقترب من 100%.
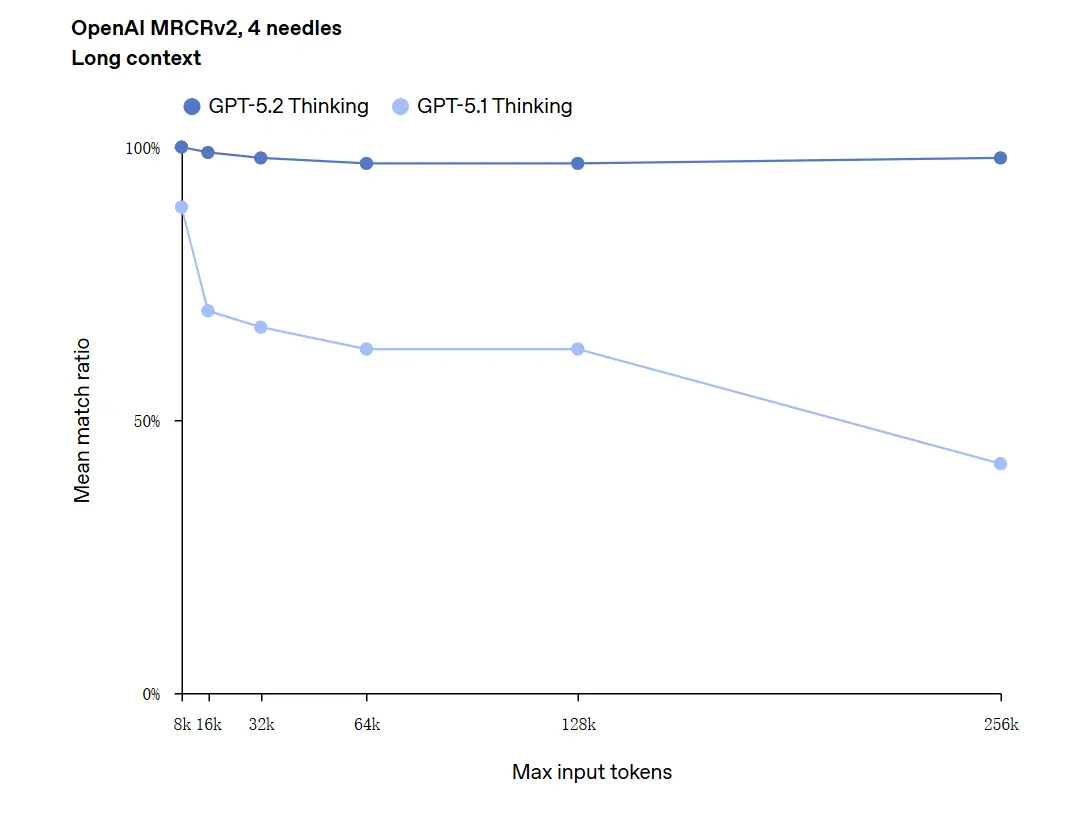
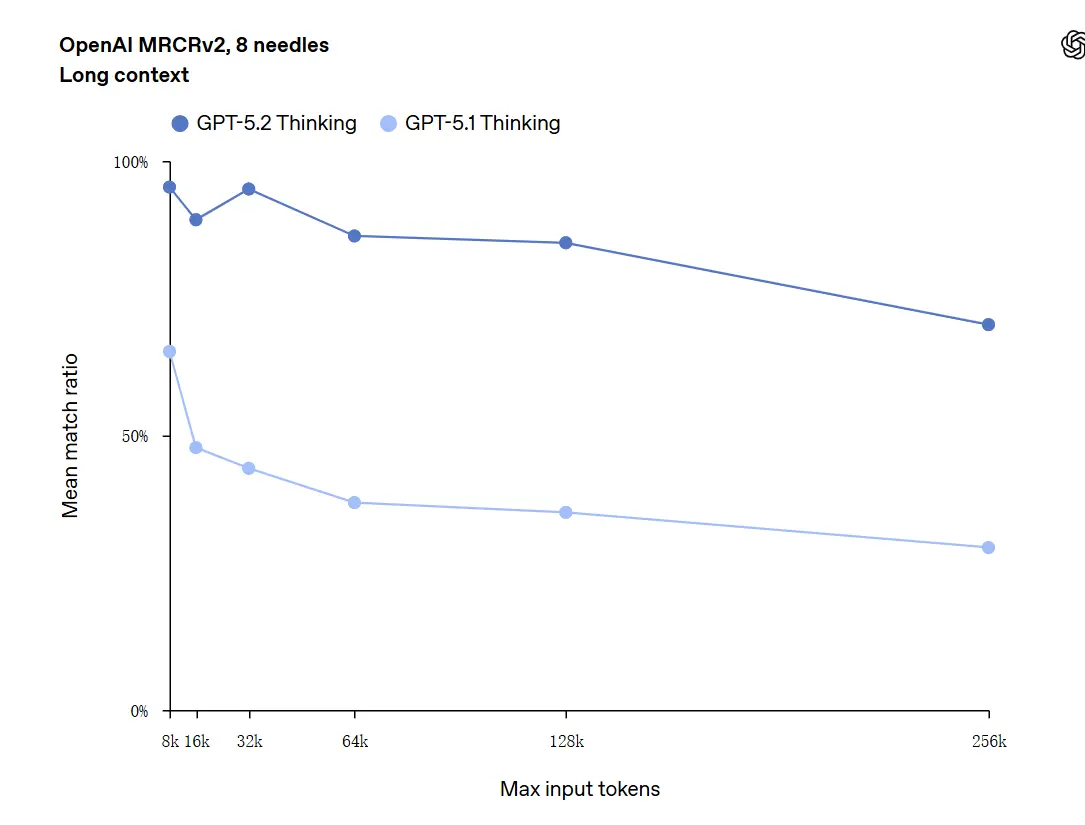
تحذير بشأن "100% دقة": وُصفت التحسينات بأنها "تقترب من 100%" في المهام المصغرة الضيقة؛ بيانات OpenAI أوضح ما تكون بوصفها "ريادة على مستوى الحالة وغالبًا عند أو فوق مستويات الخبراء البشريين في المهام المقيمة"، وليست مثالية حرفيًا عبر جميع الاستخدامات. تظهر المعايير مكاسب كبيرة ولكن ليست كمالًا شاملاً.
3) ما الجديد في الفهم البصري والاستدلال متعدد الوسائط؟
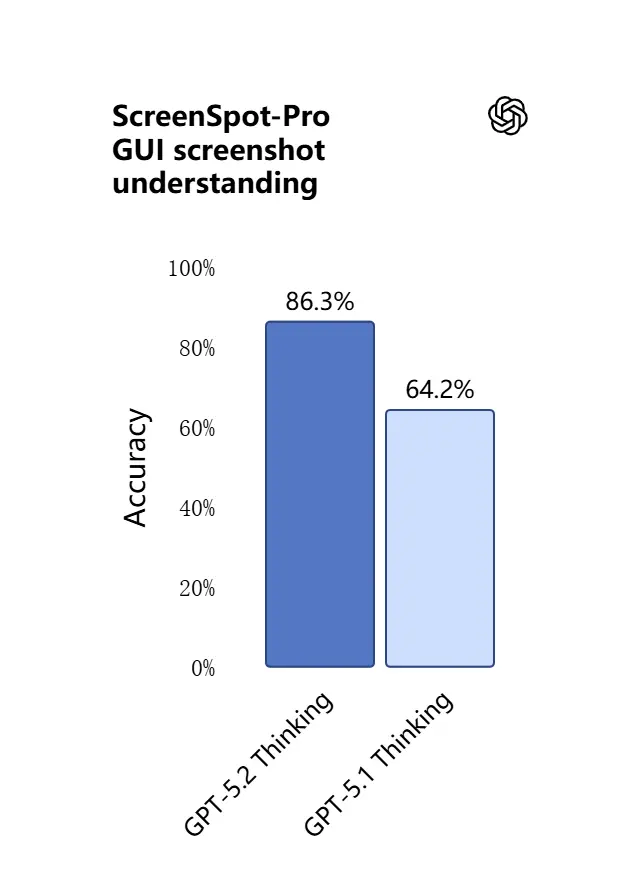
قدرات الرؤية في GPT-5.2 أكثر حدة وأكثر عملية. النموذج أفضل في تفسير لقطات الشاشة، وقراءة الرسوم البيانية والجداول، والتعرف على عناصر واجهة المستخدم، ودمج المدخلات البصرية مع سياق نصي طويل. الأمر ليس مجرد توليد وصف: يستطيع GPT-5.2 استخراج بيانات منظمة من الصور (مثل الجداول في ملف PDF)، وشرح الرسوم البيانية، والاستدلال على المخططات بطرق تدعم إجراءات الأدوات اللاحقة (مثل إنشاء جدول بيانات من تقرير مُصوَّر).
.webp)
الأثر العملي: يمكن للفرق تمرير عروض شرائح كاملة، أو تقارير بحث ممسوحة، أو مستندات كثيفة بالصور مباشرة إلى النموذج وطلب تركيبات عبر المستندات — ما يقلل كثيرًا من عمل الاستخراج اليدوي.
4) كيف تغير استدعاء الأدوات وتنفيذ المهام؟
يدفع GPT-5.2 أبعد في السلوك الوكيلي: فهو أفضل في تخطيط المهام متعددة الخطوات، وتقرير متى يستدعي الأدوات الخارجية، وتنفيذ تسلسلات من استدعاءات API/الأدوات لإنهاء العمل من البداية إلى النهاية. تحسّن "الاستدعاء الوكيلي للأدوات" — سيقترح النموذج خطة، ويستدعي أدوات (قواعد بيانات، حوسبة، أنظمة ملفات، متصفح، مشغلات كود)، ويُركّب النتائج في مُخرج نهائي بشكل أكثر موثوقية من الإصدارات السابقة. تقدم الـ API ميزات توجيه وضوابط سلامة (قوائم الأدوات المسموح بها، سقالات الأدوات)، ويمكن لواجهة ChatGPT أن تُوجه الطلب تلقائيًا إلى المتغير المناسب من 5.2 (Instant مقابل Thinking).
سجل GPT-5.2 نسبة 98.7% في معيار Tau2-Bench لقطاع الاتصالات، مما يُظهر نضجه في استدعاء الأدوات ضمن مهام متعددة الدورات معقدة.
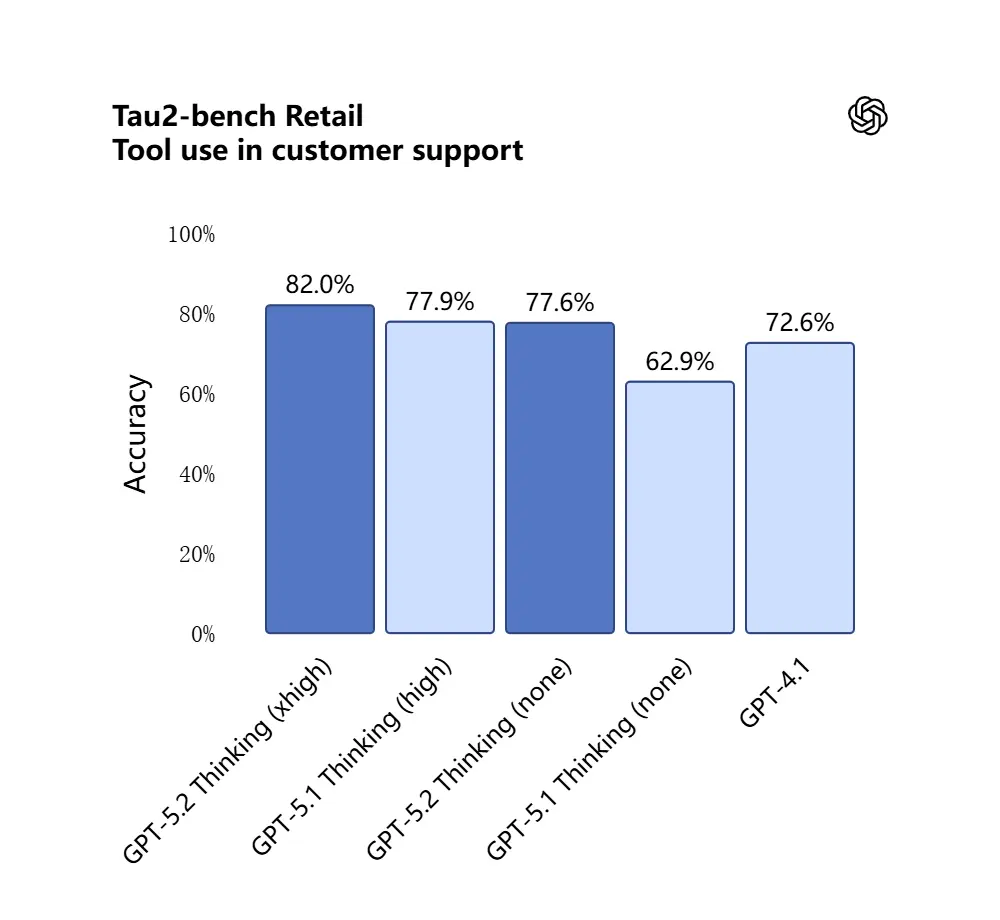
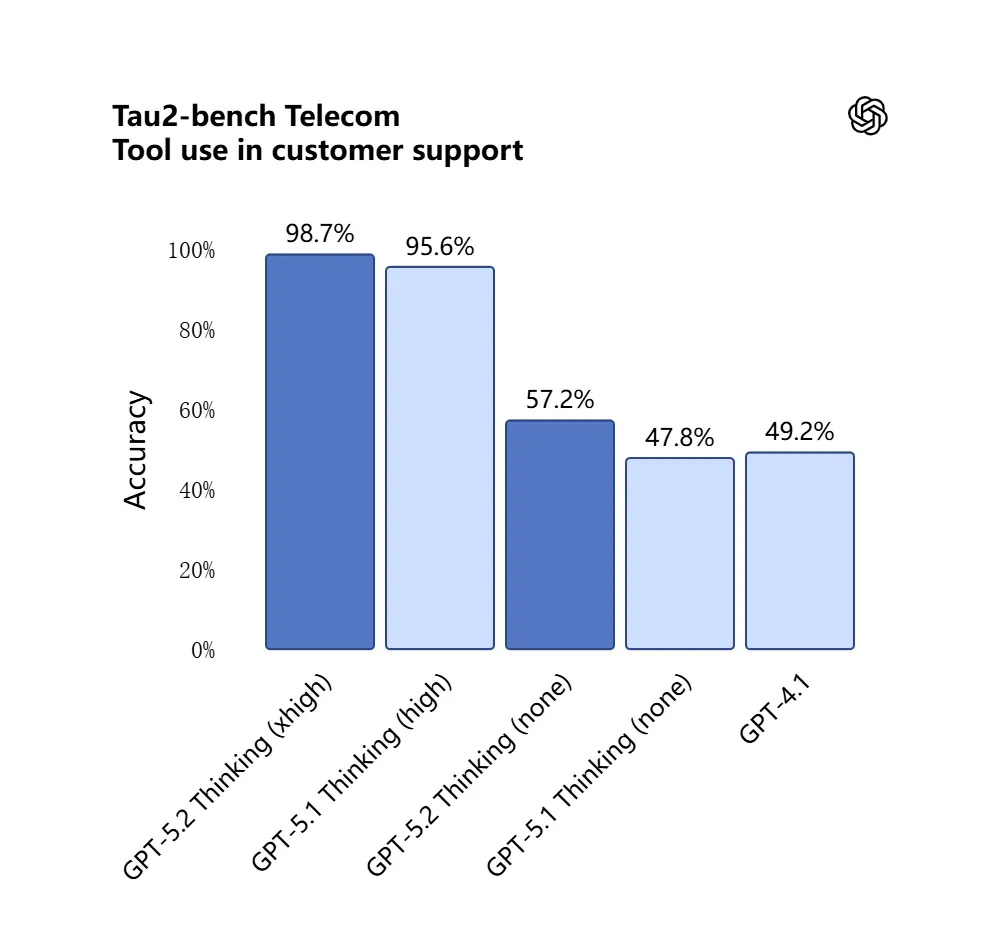
لماذا يهم: هذا يجعل GPT-5.2 أكثر فائدة كمساعد مستقل لسير عمل مثل "استوعب هذه العقود، استخرج البنود، حدّث جدول بيانات، واكتب رسالة تلخيصية" — مهام كانت سابقًا تتطلب orchestrations دقيقة.
5) تطور القدرة البرمجية
GPT-5.2 أفضل بشكل ملحوظ في مهام الهندسة البرمجية: يكتب وحدات أكثر اكتمالًا، ويولد ويشغل اختبارات بشكل أكثر موثوقية، ويفهم رسوم اعتماد المشاريع المعقدة، وهو أقل عرضة لـ"البرمجة الكسولة" (تجاوز القوالب أو الفشل في ربط الوحدات). على معايير ترميز بمستوى صناعي (SWE-bench Pro، إلخ) يضع GPT-5.2 أرقامًا قياسية جديدة. للفرق التي تستخدم LLMs كشريك برمجة، قد يقلل هذا التحسن التحقق اليدوي وإعادة العمل بعد التوليد.
في اختبار SWE-Bench Pro (مهمة هندسة برمجيات صناعية واقعية)، تحسن سجل GPT-5.2 Thinking إلى 55.6%، كما حقق رقمًا جديدًا 80% في اختبار SWE-Bench Verified.
_Software%20engineering.webp)
في التطبيقات العملية، يعني هذا:
- تصحيح تلقائي لشيفرة بيئة الإنتاج يؤدي إلى استقرار أكبر؛
- دعم للبرمجة متعددة اللغات (ليس محصورًا بـ Python)؛
- القدرة على إتمام مهام إصلاح شاملة من طرف إلى طرف بشكل مستقل.
ما الفروقات بين GPT-5.2 وGPT-5.1؟
الجواب المختصر: GPT-5.2 ترقية تكرارية لكنها جوهرية. يحافظ على بنية عائلة GPT-5 وأسس التعدد الوسائطي، لكنه يتقدم في أربعة أبعاد عملية:
- عمق واتساق الاستدلال. يقدم 5.2 مستويات أعلى من جهد الاستدلال وربطًا أفضل للمشكلات متعددة الخطوات؛ حسّن 5.1 الاستدلال سابقًا، لكن 5.2 يرفع السقف للرياضيات المعقدة والمنطق متعدد المراحل.
- موثوقية السياق الطويل. كلا الإصدارين وسّعا السياق، لكن 5.2 مضبوط للحفاظ على الدقة عميقًا داخل المدخلات الطويلة جدًا (تدعي OpenAI احتفاظًا محسنًا حتى مئات آلاف الرموز).
- دقة الرؤية + التعدد الوسائطي. يحسّن 5.2 الربط المتبادل بين الصور والنص — مثل قراءة رسم بياني ودمج بياناته في جدول بيانات — مقدمًا دقة أعلى على مستوى المهمة.
- سلوك الأدوات الوكيلية وميزات الـ API. يكشف 5.2 معلمات جهد استدلال جديدة (
xhigh) وميزات ضغط السياق في API، وقد حسّنت OpenAI منطق التوجيه في ChatGPT بحيث تختار الواجهة أفضل متغير تلقائيًا. - أخطاء أقل، واستقرار أكبر: يقلل GPT-5.2 "معدل الوهم" (معدل الاستجابة الخاطئة) بنسبة 38%. يجيب على أسئلة البحث والكتابة والتحليل بشكل أكثر موثوقية، مع تقليل حالات "الحقائق المختلقة". في المهام المعقدة، يكون مخرجه المُنظم أوضح ومنطقه أكثر استقرارًا. وفي الوقت نفسه، تحسنت سلامة الاستجابة بشكل كبير في المهام المتعلقة بالصحة النفسية. يقدم أداءً أكثر متانة في السيناريوهات الحساسة مثل الصحة النفسية وإيذاء النفس والانتحار والاعتماد العاطفي.
في تقييمات النظام، سجل GPT-5.2 Instant نسبة 0.995 (من 1.0) في مهمة "دعم الصحة النفسية"، أعلى بكثير من GPT-5.1 (0.883).
وبالأرقام، تُظهر المعايير المنشورة من OpenAI مكاسب قابلة للقياس على GDPval، ومعايير الرياضيات (FrontierMath)، وتقييمات الهندسة البرمجية. يتفوق GPT-5.2 على GPT-5.1 في مهام جداول المصارف الاستثمارية للمبتدئين بنسبة عدة نقاط مئوية.
هل GPT-5.2 مجاني — وكم يكلف؟
هل يمكنني استخدام GPT-5.2 مجانًا؟
بدأت OpenAI طرح GPT-5.2 بدءًا من خطط ChatGPT المدفوعة وإتاحة API. تقليديًا، تحافظ OpenAI على أسرع/أعمق النماذج ضمن الفئات المدفوعة بينما توفر متغيرات أخف نطاقًا أوسع لاحقًا؛ ومع 5.2 قالت الشركة إن الطرح سيبدأ في الخطط المدفوعة (Plus وPro وBusiness وEnterprise) وأن الـ API متاحة للمطورين. هذا يعني أن الوصول المجاني الفوري محدود: قد يحصل المستوى المجاني على وصول مُخفّض أو مُوجّه (مثل متغيرات أخف) لاحقًا مع توسيع الطرح.
الخبر السار هو أن CometAPI أصبح الآن مدمجًا مع GPT-5.2، وهو حاليًا ضمن تخفيضات عيد الميلاد. يمكنك الآن استخدام GPT-5.2 عبر CometAPI؛ يتيح لك الـ Playground التفاعل بحرية مع GPT-5.2، ويمكن للمطورين استخدام API الخاصة بـ GPT-5.2 (CometAPI مسعَّرة عند 20% من أسعار OpenAI) لبناء سير عمل.
كم يكلف عبر الـ API (للمطورين/الاستخدام الإنتاجي)؟
يتم احتساب استخدام API لكل رمز. تُظهر تسعيرة منصة OpenAI المنشورة عند الإطلاق (CometAPI مسعَّرة عند 20% من أسعار OpenAI):
- GPT-5.2 (دردشة قياسية) — 1.75$ لكل 1M رموز إدخال و14$ لكل 1M رموز إخراج (تُطبق خصومات على المدخلات المُخزنة مؤقتًا).
- GPT-5.2 Pro (الرائد) — 21$ لكل 1M رموز إدخال و168$ لكل 1M رموز إخراج (أعلى تكلفة بشكل ملحوظ لأنه مخصص لأعباء العمل عالية الدقة وكثيفة الحوسبة).
- للمقارنة، كان GPT-5.1 أرخص (مثلًا: 1.25$ إدخال / 10$ إخراج لكل 1M رمز).
التفسير: ارتفعت تكاليف API مقارنة بالأجيال السابقة؛ تشير الأسعار إلى أن قدرات 5.2 في الاستدلال المتميز والسياق الطويل مُسعَّرة كفئة منتج مميزة. بالنسبة للأنظمة الإنتاجية، تعتمد التكاليف كثيرًا على عدد الرموز الداخلة/الخارجة وعدد مرات إعادة استخدام المدخلات المخزنة مؤقتًا (تحصل المدخلات المخزنة على خصومات كبيرة).
ماذا يعني ذلك عمليًا
- للاستخدام العرضي عبر واجهة ChatGPT، تُعد خطط الاشتراك الشهرية (Plus وPro وBusiness وEnterprise) المسار الأساسي. لم تتغير أسعار طبقات اشتراك ChatGPT مع إصدار 5.2 (تحافظ OpenAI على ثبات الأسعار حتى لو تغيرت عروض النماذج).
- للاستخدام الإنتاجي والمطورين، خطط لتكاليف الرموز. إذا كان تطبيقك يبث الكثير من الردود الطويلة أو يعالج مستندات طويلة، فسوف تهيمن تكلفة رموز الإخراج (14$ / 1M رموز لـ Thinking) ما لم تقم بتخزين المدخلات مؤقتًا وإعادة استخدام المخرجات بعناية.
GPT-5.2 Instant مقابل GPT-5.2 Thinking مقابل GPT-5.2 Pro
أطلقت OpenAI GPT-5.2 بثلاثة متغيرات موجهة للغرض لتناسب حالات الاستخدام: Instant وThinking وPro:
- GPT-5.2 Instant: سريع وفعّال من حيث التكلفة، مضبوط للعمل اليومي — الأسئلة الشائعة، الإرشادات، الترجمات، المسودات السريعة. زمن استجابة منخفض؛ مسودات أولى جيدة وسير عمل بسيط.
- GPT-5.2 Thinking: ردود أعمق وأعلى جودة للعمل المستمر — تلخيص مستندات طويلة، تخطيط متعدد الخطوات، مراجعات كود مفصلة. توازن بين زمن الاستجابة والجودة؛ "حصان العمل" الافتراضي للمهام الاحترافية.
- GPT-5.2 Pro: أعلى جودة ومصداقية. أبطأ وأكثر تكلفة؛ الأفضل للمهام الصعبة وعالية المخاطر (هندسة معقدة، تركيبات قانونية، قرارات عالية القيمة) وحيث يتطلب جهد استدلال "xhigh".
جدول المقارنة
| السمة / المعيار | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| الغرض المقصود | مهام يومية، مسودات سريعة | تحليل عميق، مستندات طويلة | أعلى جودة، مشكلات معقدة |
| زمن الاستجابة | الأقل | متوسط | الأعلى |
| جهد الاستدلال | قياسي | عالٍ | xHigh متاح |
| الأفضل لـ | الأسئلة الشائعة، الدروس، الترجمات، مطالبات قصيرة | ملخصات، تخطيط، جداول بيانات، مهام ترميز | هندسة معقدة، تركيبات قانونية، بحث |
| أمثلة أسماء API | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| سعر رمز الإدخال (API) | 1.75$ / 1M | 1.75$ / 1M | 21$ / 1M |
| سعر رمز الإخراج (API) | 14$ / 1M | 14$ / 1M | 168$ / 1M |
| التوفر (ChatGPT) | طرح تدريجي؛ الخطط المدفوعة ثم الأوسع | يطرح للخطط المدفوعة | مستخدمو Pro / المؤسسات (مدفوع) |
| مثال حالة استخدام نمطية | صياغة بريد، مقتطفات كود صغيرة | بناء نموذج مالي متعدد الأوراق، سؤال وجواب لتقرير طويل | تدقيق قاعدة كود، توليد تصميم نظام بمستوى الإنتاج |
من المناسب له استخدام GPT-5.2؟
صُمم GPT-5.2 مع مجموعة واسعة من المستخدمين المستهدفين. فيما يلي توصيات حسب الدور:
المؤسسات وفرق المنتجات
إذا كنت تبني منتجات لأعمال المعرفة (مساعدات بحث، مراجعة عقود، خطوط تحليلات، أو أدوات مطورين)، يمكن لقدرات السياق الطويل والسلوك الوكيلي في GPT-5.2 أن تقلل التعقيد التكامل بشكل كبير. المؤسسات التي تحتاج فهمًا قويًا للمستندات، وتقريرًا آليًا، أو مساعدين أذكياء ستجد Thinking/Pro مفيدين. Microsoft وشركاء منصات آخرون يدمجون 5.2 بالفعل في أجنحة الإنتاجية (مثل Microsoft 365 Copilot).
المطورون وفرق الهندسة
الفرق التي ترغب في استخدام LLMs كشركاء برمجة أو لأتمتة التوليد/الاختبار ستستفيد من دقة البرمجة المحسّنة في 5.2. يتيح الوصول عبر API (بوضع thinking أو pro) تركيبات أعمق لقواعد شيفرة كبيرة بفضل نافذة السياق 400k رمز. توقع دفع المزيد على API عند استخدام Pro، لكن تقليل التصحيح والمراجعة اليدوية قد يبرر تلك التكلفة للأنظمة المعقدة.
الباحثون والمحللون كثيفو البيانات
إذا كنت تركّب الأدبيات بانتظام، أو تُحلل تقارير تقنية طويلة، أو تريد تصميم تجارب بمساعدة النموذج، فإن قدرات السياق الطويل والرياضيات في GPT-5.2 تساعد على تسريع سير العمل. لأبحاث قابلة للتكرار، اقترن النموذج بهندسة مطالبات دقيقة وخطوات تحقق.
الشركات الصغيرة والمستخدمون المحترفون
سيحصل مشتركو ChatGPT Plus (وPro للمستخدمين المحترفين) على وصول موجَّه إلى متغيرات 5.2؛ هذا يجعل الأتمتة المتقدمة والمخرجات عالية الجودة في المتناول للفرق الصغيرة دون بناء تكامل API. للمستخدمين غير التقنيين الذين يحتاجون تلخيص مستندات أفضل أو إنشاء شرائح، يقدم GPT-5.2 قيمة عملية ملحوظة.
ملاحظات عملية للمطورين والمشغلين
ميزات API الجديرة بالاهتمام
- مستويات
reasoning.effort(مثلmediumوhighوxhigh) تتيح لك إخبار النموذج بكمية الحوسبة التي ينفقها على الاستدلال الداخلي؛ استخدمها للموازنة بين زمن الاستجابة والدقة على أساس كل طلب. - ضغط السياق: تتضمن API أدوات لضغط التاريخ وتجميعه بحيث يُحافظ على المحتوى ذي الصلة حقًا لسلاسل طويلة. هذا أمر حاسم عندما يجب إبقاء استخدام الرموز فعالًا.
- سقالات الأدوات وضوابط الأدوات المسموح بها: على الأنظمة الإنتاجية أن تُصرح صراحة بالأدوات التي يمكن للنموذج استدعاؤها وأن تُسجل استدعاءات الأدوات للتدقيق.
نصائح ضبط التكلفة
- خزّن تضمينات المستندات المستخدمة كثيرًا، واستخدم المدخلات المخزنة مؤقتًا (التي تحصل على خصومات حادة) للاستعلامات المتكررة على نفس المتن. تتضمن تسعيرة منصة OpenAI خصومات كبيرة للمدخلات المخزنة.
- وجّه الاستعلامات الاستكشافية/منخفضة القيمة إلى Instant واحتفظ بـ Thinking/Pro للدفعات أو المرور النهائي.
- قدّر استخدام الرموز بدقة (إدخال + إخراج) عند توقع تكاليف API لأن المخرجات الطويلة تضاعف التكلفة.
الخلاصة — هل ينبغي الترقية إلى GPT-5.2؟
إذا كان عملك يعتمد على الاستدلال عبر مستندات طويلة، والتركيب عبر المستندات، والتفسير متعدد الوسائط (صور + نص)، أو بناء وكلاء يستدعون أدوات، فإن GPT-5.2 ترقية واضحة: فهو يرفع الدقة العملية ويقلل عمل التكامل اليدوي. إذا كنت تدير أساسًا روبوتات دردشة عالية الحجم ومنخفضة الكمون أو تطبيقات مقيدة الميزانية بشكل صارم، فقد يظل Instant (أو نماذج أقدم) خيارًا معقولًا.
يمثل GPT-5.2 تحولًا متعمدًا من "دردشة أفضل" إلى "مساعد احترافي أفضل": حوسبة أكثر، وقدرة أكبر، وطبقات تكلفة أعلى — لكنه يقدم أيضًا مكاسب إنتاجية حقيقية للفرق القادرة على الاستفادة من سياق طويل موثوق، ورياضيات/استدلال محسّن، وفهم للصور، وتنفيذ وكِيلي للأدوات.
للبدء، استكشف نماذج GPT-5.2(GPT-5.2;GPT-5.2 pro، GPT-5.2 chat) في الـ Playground واطلع على API guide للحصول على إرشادات مفصلة. قبل الوصول، يرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. تقدم CometAPI سعرًا أقل بكثير من السعر الرسمي لمساعدتك على التكامل.
Ready to Go?→ Free trial of gpt-5.2 models !