

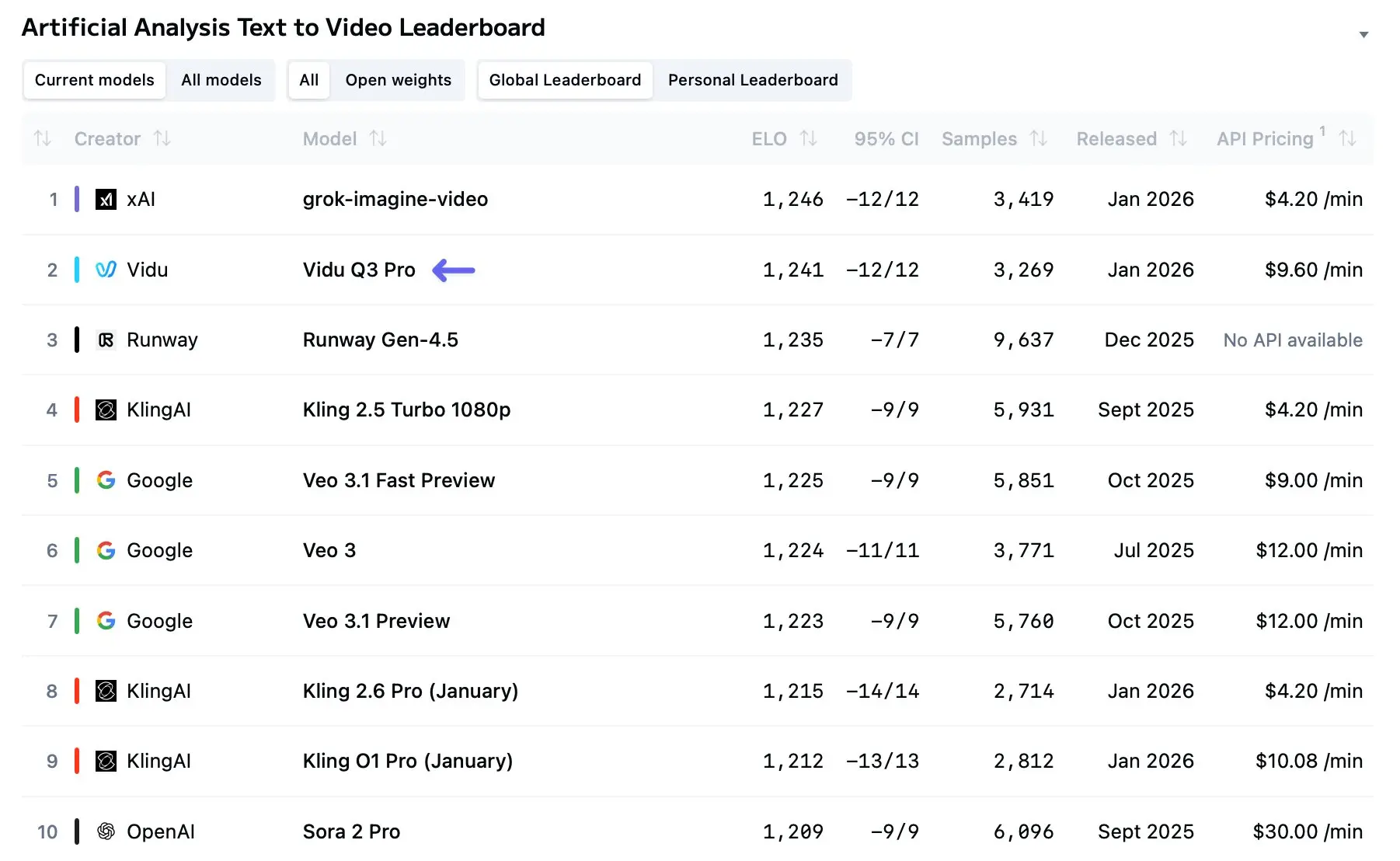
دخل Vidu Q3 المشهد في أوائل 2026 كأحد أوضح المؤشرات حتى الآن على أن توليد الفيديو بالذكاء الاصطناعي ينتقل من المقاطع القصيرة الطريفة إلى سرد قصصي حقيقي متعدد اللقطات. خلال الأشهر منذ طرحه على نطاق واسع، أصبح Vidu Q3 عنصرًا أساسيًا في سير عمل المبدعين، والطيارات البحثية، والطيارات التجارية — ولسبب وجيه: فهو يدفع حدود المدة، والتكامل السمعي البصري، واتساق اللقطات المتعددة أبعد من معظم النماذج السابقة، مع تقديم واجهة API موجهة للمطورين للاستخدام البرمجي.
ما هو Vidu Q3؟
Vidu Q3 هو أحدث إصدار رائد من معمارية نموذج الفيديو الكبير (LVM) لدى ShengShu Technology. وعلى عكس أسلافه (Vidu 1.0 و1.5) الذين كانوا يتطلبون سيرَي عمل منفصلين لتوليد الصورة ومعالجة الصوت لاحقًا، فإن Vidu Q3 هو محرك توليدي "الكل في واحد".
الاختراق الجوهري في Vidu Q3 هو قدرته على توليد صور عالية الدقة وصوت عالي الدقة في الوقت نفسه.[ من خلال فهم فيزياء الصوت والضوء معًا، يلغي النموذج "الوادي الغريب" للتزامن غير المحكم للصوت الذي يظهر غالبًا في النماذج المنافسة. يدعم حتى 16~ ثانية من التوليد المتواصل بدقة 1080p أصلية، ما يضعه كأداة جاهزة للإنتاج للأفلام القصيرة والإعلانات والسرد القصصي.
كيف يعمل Vidu Q3 تحت الغطاء؟
بينما تبقى تفاصيل المعمارية الأساسية ملكية خاصة، يبني Vidu على دمج U-ViT لنماذج الانتشار والمحولات — وهو تصميم معروف بتحقيق توازن بين الاتساق، والاستمرارية الزمنية، والتعبيرية في توليد الفيديو.
تمكّن هذه المعمارية الهجينة النموذج من الاستدلال على الحركة، والصوت، والسياق السردي عبر تسلسلات ممتدة.
6 من الميزات البارزة لـ Vidu Q3
1. توليد ممتد المدة — إلى متى يمكنه الاستمرار؟
إحدى أبرز ميزات Vidu Q3 هي إطالة مدة التوليد الواحدة. ركزت نماذج الجيل السابقة على المقاطع الصغيرة؛ أما Q3 فيمد طول المقطع عمدًا للسماح بمنحنيات قصصية بسيطة وتسلسلات متعددة اللقطات دون إجبار المبدعين على وصل العديد من المقاطع الصغيرة. توثق المنصة وبوابات الشركاء حتى نحو 16~ ثانية من التوليد الأصلي في تمريرة واحدة (قد تختلف خيارات التنسيق والجودة حسب المزود وخطة API). هذا مهم لأن الانتقال من 4–8 ثوان إلى 16 ثانية يغيّر طريقة تخطيط المبدعين للمشاهد، وكتابة الإيقاعات، وضبط توقيت الإشارات الصوتية.
2. دقة بصرية واتساق زمني
تُظهر التقييمات المستقلة والمعايير المبكرة أن Vidu Q3 ينتج صورًا أوضح وتشوهات أقل على مستوى الإطار مقارنة بالنماذج الاستهلاكية الأقدم. يبدو أن التحسينات في المعمارية وتعزيز البيانات تقللان الوميض وتحسنان استمرارية الحركة للمقاطع تحت 10–16 ثانية. ومع ذلك، قد يواجه النموذج صعوبة في المشاهد الكثيفة متعددة الكائنات (الحشود، التفاعلات الفيزيائية المعقدة) حيث يتطلب الحجب والحركة الدقيقة تعقّلًا فيزيائيًا قويًا. وقد وضعت مواقع التصنيف المقارن ولوحات صدارة النماذج Vidu Q3 عاليًا في قوائم T2V (تحويل النص إلى فيديو)، رغم اختلاف التصنيفات وفق الاختبارات ومجموعات البيانات.
3. توليد صوت + فيديو أصلي
على عكس الأنظمة التي تنتج صورًا صامتة وتترك الصوت لمرحلة ما بعد الإنتاج، يدمج Vidu Q3 توليد الصوت داخل النموذج. والنتيجة هي حوارات متزامنة مع حركة الشفاه، ومؤثرات صوتية مضبوطة التوقيت، وموسيقى خلفية اختيارية تُنتج جنبًا إلى جنب مع الإطارات. يقلل دمج الصوت على مستوى النموذج أخطاء المحاذاة (انجراف مزامنة الشفاه، الإشارات خارج الإيقاع) ويقصر دورة الإنتاج للعروض التوضيحية والمعاينات والعديد من القطع القصيرة الجاهزة.
4. تحكم ذكي بالكاميرا وسرد متعدد اللقطات
تفسر ميزات "الكاميرا الذكية" في Q3 المطالبات الخاصة بحركات الكاميرا (تحريك بان، دولي، تتبّع) وتسلسلات متعددة اللقطات. بدلًا من إنتاج منظور ثابت واحد، يمكن للنموذج توليد قصّات مخططة وانتقالات بحيث يُقرأ المقطع الناتج كمشهد مُخرج. بالنسبة للمبدعين، يحوّل هذا المخرجات من "صورة مركبة واحدة تتحرك" إلى "مشهد قصير متعدد اللقطات". ذلك يحسن قابلية المشاهدة ويتيح سردًا بصريًا أغنى في توليد واحد.
5. اتساق متعدد المراجع وثبات الشخصية
استثمرت منصة Vidu في أنظمة "من مرجع إلى فيديو" واتساق متعدد المراجع التي تسمح للمبدعين برفع عدة صور مرجعية لتثبيت هوية الشخصية عبر الإطارات. يمد Q3 تلك الأفكار ليحافظ على مظهر الشخصية والدعائم بشكل متسق عبر زوايا كاميرا متعددة وقصّات — وهو مطلب أساسي لإخراج سردي متماسك. هذا مفيد بشكل خاص لمشاريع الأنمي أو الاستايلات المُؤسلَفة حيث يكون الحفاظ على اتساق رسم الشخصيات أمرًا حاسمًا.
6. جاهزية المطورين: واجهات API وتدفق العمل
تتوفر مجموعة نماذج Vidu — بما فيها Q3 — عبر واجهات الويب وواجهة REST API برمجية. يمكن للمطورين إرسال مهام نص إلى فيديو أو صورة + نص إلى نقطة استدلال، والحصول على معرّف مهمة، والاستقصاء عن النتائج (نمط مهام غير متزامن معتاد). يوفر الـ API معلمات مثل الدقة، ونسبة العرض إلى الارتفاع، والمدة، وسعة الحركة، ومُبدّل لتوليد الصوت. هذا يجعل Q3 متاحًا للأتمتة، وسير العمل الدفعي، والتكامل مع خطوط تحرير المحتوى.
كيف يقارن Vidu Q3 مع Sora 2 وVeo 3.1؟
الإجابة المختصرة: ينافس Vidu Q3 بقوة في المخرجات السردية الأطول والتوليد المدمج للصوت/الفيديو لمشاهد 10–20 ثانية، يتفوق Sora 2 في الواقعية الفيزيائية للّقطة الواحدة والتكامل الاجتماعي، بينما يتصدر Veo 3.1 من حيث الصقل البصري على مستوى البكسل، وأدوات الاستمرارية متعددة الإطارات، وتكامل API للمؤسسات. أدناه نفصل الفروقات عبر محاور عملية.
أي نموذج أقوى في الواقعية والفيزياء: Sora 2 أم Vidu Q3؟
تم تدريب Sora 2 (OpenAI) صراحةً على المعقولية الفيزيائية ومحاكاة العالم — وتشير ملاحظاته العامة إلى سلوك فيزيائي متقدم، وتفاعلات كائنات دقيقة، ومسارات حركة شديدة الواقعية. يوفر Sora 2 أيضًا صوتًا متزامنًا وتكاملات مع تطبيقات اجتماعية (بما في ذلك الكاميو وتطبيقًا للهاتف)، ما يجعله قويًا للغاية للمشاهد الواقعية المتماسكة فيزيائيًا. إذا كان موجزك يتطلب تصادمات دقيقة، وديناميكيات واقعية، أو حركة بشرية فوتوريالية في لقطات قصيرة مكتفية ذاتيًا، غالبًا ما يكون Sora 2 متفوقًا.
في المقابل، يتموضع Vidu Q3 كمحرك للسرد القصصي: مقاطع أطول، تسلسل متعدد اللقطات، وتحكم بالكاميرا على نمط المخرج. هذا لا يعني أن Vidu يضحي بالواقعية، لكن مكاسبه الأساسية هي استمرارية السرد ومخرجات سمعية بصرية مجتمعة بدلًا من محاكاة فيزيائية خام. بالنسبة للسرد السينمائي القصير (مثل عرض منتج مدته 16 ثانية مع قصّات وتعليق صوتي)، يكون سير عمل Q3 غالبًا أسرع وأبسط.
أي نموذج أفضل في الصقل السينمائي والدقة العالية: Veo 3.1 أم Vidu Q3؟
تم تسويق Veo 3.1 (Google / DeepMind / Gemini) كخيار عالي الدقة وعلى مستوى المؤسسات مع ضوابط استمرارية قوية، وتوليد صوت أصلي، ودعم داخل سحابة Google/Vertex/Gemini. قدّم Veo 3.1 ميزات متقدمة "مكونات إلى فيديو"، ودعمًا رأسيًا (9:16) أصليًا، وترقية دقة إلى مستويات عالية (بما في ذلك قدرات 4K في بعض التدفقات). للمشاريع التي تتطلب أعلى جودة بكسل، وتناسقًا لونيًا دقيقًا، وواجهات API مؤسسية محكمة، غالبًا ما يكون Veo 3.1 الخيار الأمثل.
يحافظ Vidu Q3 على مكانته عبر التركيز على المدة الممتدة + اتساق القصة متعدد اللقطات ومنتج متمحور حول المبدعين (ساحات لعب ويب سريعة، تنظيم متعدد المراجع). إذا كانت أولويتك إنتاج مشهد قصير مُدار بشريًا مع عدة حركات كاميرا وإشارات صوتية مدمجة (وتُفضّل الطول على الصقل البصري الخام)، فإن Vidu Q3 جذاب. أما من حيث الفوتوريالية الخام، فعادة ما تكون الأفضلية لـ Veo 3.1.
اعتبارًا من أوائل 2026، يتكوّن ثالوث فيديو الذكاء الاصطناعي من Sora 2 من OpenAI، وVeo 3.1 من Google، وVidu Q3. إليك كيف يتراصون في مقارنة مباشرة:
| الميزة | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| الحد الأقصى لمدة المقطع الواحد | ~16 s | Up to ~25 s (Pro) | 8 s (مع ميزات وصل السرد) |
| توليد صوت أصلي | نعم (مُندمج) | نعم (تجريبي) | نعم (متقدم) |
| تحكم سينمائي بالكاميرا | نعم (واعي باللقطة) | قوالب محدودة | نعم (اتساق متعدد اللقطات) |
| سرد متعدد اللقطات | نعم | نعم | نعم |
| عرض النص داخل الإطارات | نعم | يتفاوت | يتفاوت |
| الدقة | 1080p | 1080p | 1080p / 4K في حالات خاصة |
| حالة الاستخدام الأساسية | سرد قصصي، تحريك | مفهوم/فيلم بميزانية مرتفعة | Youtube Shorts / TikTok |
التحليل:
- مقابل Sora 2: يظل Sora 2 الوزن الثقيل من حيث الصقل البصري الخالص والخيال السريالي ("جودة هوليوودية"). ومع ذلك، يتفوق Vidu Q3 عليه في كفاءة سير العمل بفضل حد 16 ثانية والتكامل الصوتي المتفوق. للمبدعين الذين يحتاجون إلى مقطع "منتهٍ في مرة واحدة"، يكون Q3 أسرع.
- مقابل Veo 3.1: يتفوق Veo 3.1 في السرعة للمقاطع الأقصر الموجهة لوسائل التواصل (4–8 ثوان) ويتكامل بعمق مع YouTube. يستهدف Vidu Q3 سلسلة قيمة أعلى، موجّهًا إلى رسامي التحريك المحترفين وصنّاع الأفلام الذين يحتاجون إلى لقطات أطول ومتواصلة يصعب على Veo الحفاظ على اتساقها.
ما التطبيقات العملية التي يتيحها Vidu Q3؟
الإعلانات والتسويق القصير
يمكن للعلامات التجارية نمذجة مفاهيم الإعلانات من البداية للنهاية بسرعة أكبر: كتابة نص، توليد فيديو مدته 16 ثانية مع تعليق صوتي ومؤثرات متزامنة، تكرار صياغة الكلمات وتكوين اللقطات، وإنتاج دبلجات بعدة لغات عبر توجيه لغوي مختلف. بالنسبة لاختبارات A/B للإبداعات الاجتماعية، يقل زمن التنفيذ بشكل واضح. تعرض دراسات الحالة كيف يستخدم المسوقون Vidu Q3 للإعلانات المصغرة ومقاطع تشويق المنتجات.
رسم اللوحات القصصية والمعاينة المسبقة للأفلام والتلفاز
يستخدم المخرجون والمحررون مقاطع الذكاء الاصطناعي القصيرة كمعاينات مسبقة (previz) لتنظيم المشاهد، واختبار حركات الكاميرا، وطرح المعالجات. تعد تسلسلات Q3 متعددة اللقطات وضوابط الكاميرا الذكية مفيدة جدًا هنا: يمكن للفرق الإبداعية التكرار على التنظيم والحوار دون تكلفة مواقع التصوير. ورغم أن المعاينة بالذكاء الاصطناعي لا تستبدل الإخراج في الموقع، فإنها تقصر دورات القرار المبكرة.
التعلم الإلكتروني وفيديوهات الشرح
يمكن لإدارات التعليم والتعلم المؤسسي توليد مقاطع شرح متحركة موجزة مع سرد متزامن ومؤثرات صوتية مُعلّمة. بالنسبة للمحتوى المعياري (تدريب المنتجات، التأهيل)، يقلل هذا الاعتماد على شركات الإنتاج المكلفة ويُسرّع النسخ المحلية. تجعل سرعة النشر وقدرات الصوت الأصلية Vidu Q3 جذابًا لهذه الحالات.
الألعاب، الرسم المفاهيمي، والإنتاج المستقل
يستخدم المطورون المستقلون وفرق الألعاب مقاطع سينمائية قصيرة بالذكاء الاصطناعي للعروض التشويقية، ومحاكاة حوارات NPC، أو استكشاف الأنماط. يساعد دعم Vidu Q3 للصور المرجعية واتساق الشخصيات في الحفاظ على هوية بصرية متماسكة لـ IP اللعبة في العروض التمهيدية. يُستخدم النموذج أيضًا لمواد العرض للحصول على التمويل أو اهتمام الناشرين.
إمكانية الوصول والتوطين السريع
نظرًا لتوليد الصوت أصلاً، يُبسّط Vidu Q3 النسخ متعددة اللغات: توليد اللقطة نفسها بمطالبات لغوية مختلفة، أو طلب طبقات صوتية متنوعة. يتيح ذلك توطينًا سريعًا لمحتوى التسويق أو التدريب مع الحفاظ على تقريبات مزامنة الشفاه الكافية للعديد من السياقات القصيرة (على أن مطابقة الشفاه على مستوى البث قد تتطلب ضبطًا بشريًا).
هل Vidu Q3 هو أفضل نموذج فيديو بالذكاء الاصطناعي في 2026؟
إعلان "أفضل" نموذج واحد يفوّت التفاصيل الدقيقة: الفائز يعتمد على حالة الاستخدام.
- للخرج الفوتوريالي الموثوق فيزيائيًا والتعامل المحافظ مع الأمان، يُنظر إلى Sora 2 من OpenAI غالبًا كخيار قمة. يركز على الواقعية والمراجعة المتينة، ما يجعله جذابًا للإنتاج عالي المستوى والمؤسسات حذرة المخاطر.
- للمحتوى القصير المُحسّن للتكامل مع المنصات، تجعل مخرجات Veo 3.1 الرأسية الأصلية وتكامل تطبيقات Google (YouTube Shorts وGoogle Photos) استخدامه مريحًا بشكل فريد.
- لنمذجة سريعة للصوت والفيديو، وتحكم سردي متعدد اللقطات، وتوازن قوي لميزات السرد، يبرز Vidu Q3 — خاصة عندما تكون سرعة التكرار والصوت المدمج أهم من الفوتوريالية المطلقة. تضع المعايير المبكرة وتقرير البائع Vidu Q3 عاليًا في تصنيفات T2V، وتجعله ميزاته خيارًا عمليًا للمسوقين، والمبدعين المستقلين، والاستوديوهات التي تُنمذج أفكارًا جديدة.
القيود والاعتبارات؟
بينما يمثل Vidu Q3 اختراقًا، لديه مقايضات:
- لا تزال مدة المقطع محدودة (~16 ثانية)، لذا تتطلب السرديات الأطول الوصل أو مطالبات متعددة.
- يمكن أن تتصاعد تكلفة الموارد مع التوليد عالي الدقة والصوت المعقد.
- لا تزال أدوات الذكاء الاصطناعي تتطلب حكمًا تحريريا لصقل المخرجات وتحريرها إلى منتجات نهائية.
إذًا: Vidu Q3 منافس من الفئة العليا في 2026، خصوصًا للمبدعين الذين يُعطون الأولوية لسير عمل الصوت الأصلي والسرد متعدد اللقطات. ما إذا كان هو الأفضل يعتمد على موجز الإنتاج الدقيق، والقيود التنظيمية، وخط توزيع المستخدم.
الخلاصة
يتألق Vidu Q3 في 2026 كنموذج فيديو رائد قادر على إنتاج مقاطع جاهزة للسرد مدمجة الصوت والفيديو تجسر بين الإبداع ومتطلبات الإنتاج. مقارنةً بـتماسك السرد القوي لدى Sora 2 والواقعية السينمائية لدى Veo 3.1، يقدم Vidu Q3 مجموعة أدوات متوازنة مثالية للرواة والمبدعين وسير العمل التجاري.
كما تُظهر المعايير أداءه العالي وميزاته المتكاملة، يمثل Vidu Q3 نقطة تحول في فيديو الذكاء الاصطناعي التوليدي — مما يجعل الإنتاج السمعي البصري المعقد أكثر إتاحة وكفاءة.
يمكن للمطورين الوصول إلى Vidu Q3، وVeo 3.1 وSora 2 عبر CometAPI، وآخر النماذج المدرجة حتى تاريخ نشر المقال. للبدء، استكشف قدرات النموذج في Playground واطلع على دليل API للحصول على إرشادات مفصلة. قبل الوصول، يرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. تقدم CometAPI سعرًا أقل بكثير من السعر الرسمي لمساعدتك على الاندماج.
جاهز للبدء؟→ Sign up fo Video generation today !
إذا كنت تريد المزيد من النصائح والإرشادات والأخبار حول الذكاء الاصطناعي فاتبعنا على VK، وX وDiscord!