

في مشهد يهيمن عليه نهج «التوسعة بأي ثمن» — حيث تدفع نماذج مثل Flux.2 وHunyuan-Image-3.0 عدد المعاملات إلى نطاق ضخم يتراوح بين 30B و80B — ظهر منافس جديد ليُحدث اضطرابًا في الوضع الراهن. Z-Image، الذي طوّره مختبر Tongyi التابع لـAlibaba، انطلق رسميًا، محطّمًا التوقعات بهيكلية رشيقة تضم 6 مليارات معامل تنافس جودة مخرجات عمالقة الصناعة بينما تعمل على عتادٍ استهلاكي.
صدر في أواخر 2025، وقد أسر Z-Image (ومتغيره فائق السرعة Z-Image-Turbo) مجتمع الذكاء الاصطناعي على الفور، متجاوزًا 500,000 عملية تنزيل خلال 24 ساعة من إطلاقه. من خلال إنتاج صور فوتوغرافية واقعية في 8 خطوات استدلال فقط، لا يُعد Z-Image مجرد نموذجٍ آخر؛ إنه قوة ديمقراطية في الذكاء الاصطناعي التوليدي، يتيح إنشاءًا عالي الدقة على أجهزة الحاسوب المحمولة التي قد «تختنق» أمام منافسيه.
ما هو Z-Image؟
Z-Image هو نموذج أساس مفتوح المصدر لتوليد الصور، طوّرته فرق بحث Tongyi-MAI / Alibaba Tongyi Lab. إنه نموذج توليدي يضم 6 مليارات معامل مبني على بنية جديدة تُسمّى Scalable Single-Stream Diffusion Transformer (S3-DiT)، تقوم بربط رموز النص ورموز الدلالات البصرية ورموز VAE في تيار معالجة واحد. الهدف التصميمي واضح: تقديم واقعية فوتوغرافية من الطراز الأول والالتزام بالتعليمات مع خفض تكلفة الاستدلال بشكل جذري وتمكين الاستخدام العملي على العتاد الاستهلاكي. ينشر مشروع Z-Image الشيفرة وأوزان النموذج وعرضًا تجريبيًا عبر الإنترنت بموجب ترخيص Apache-2.0.
يأتي Z-Image بعدة متغيرات. الإصدار الأكثر تداولًا هو Z-Image-Turbo — نسخة مُقطّرة قليلة الخطوات مُحسّنة للنشر — إضافة إلى النسخة غير المُقطّرة Z-Image-Base (نقطة أساس مناسبة أكثر لإعادة الضبط/التخصيص) وZ-Image-Edit (مضبوطة بالتعليمات لتحرير الصور).
ميزة «Turbo»: استدلال من 8 خطوات
يستفيد الإصدار الرائد، Z-Image-Turbo، من تقنية تقطير تقدّمية تُعرف باسم Decoupled-DMD (Distribution Matching Distillation). يسمح ذلك للنموذج بضغط عملية التوليد من 30–50 خطوة قياسية إلى 8 خطوات فقط.
النتيجة: أزمنة توليد دون الثانية على وحدات GPU المؤسسية (H800) وأداء شبه لحظي على البطاقات الاستهلاكية (RTX 4090)، من دون المظهر «البلاستيكي» أو «المغسول» المعتاد في نماذج التوربو/البرق الأخرى.
4 ميزات رئيسية في Z-Image
يأتي Z-Image محمّلًا بميزات تلائم المطورين التقنيين والمهنيين المبدعين على حد سواء.
1. واقعية فوتوغرافية وجماليات لا تُضاهى
على الرغم من امتلاكه 6 مليارات معامل فقط، ينتج Z-Image صورًا بوضوح مبهر. إنه يتفوّق في:
- ملمس البشرة: استنساخ المسام والعيوب والإضاءة الطبيعية على البشر.
- فيزياء المواد: عرض دقيق للزجاج والمعادن وأنسجة الأقمشة.
- الإضاءة: معالجة متفوّقة للإضاءة السينمائية والحجمية مقارنة بـSDXL.
2. عرض نص ثنائي اللغة بشكل أصيل
كانت كتابة النص إحدى أكبر نقاط الألم في توليد الصور بالذكاء الاصطناعي. يحل Z-Image ذلك بدعم أصيل لِـ الإنجليزية والصينية معًا.
- يمكنه توليد ملصقات وشعارات ولافتات مع تهجئة وخط صحيحين باللغتين، وهي ميزة غالبًا ما تغيب عن النماذج ذات التركيز الغربي.
3. Z-Image-Edit: تحرير قائم على التعليمات
إلى جانب النموذج الأساسي، أطلقت الفريق Z-Image-Edit. هذا المتغير مضبوط على مهام صورة-إلى-صورة، ويسمح للمستخدمين بتعديل الصور القائمة باستخدام تعليمات لغة طبيعية (مثل "اجعل الشخص يبتسم"، "غيّر الخلفية إلى جبل ثلجي"). ويحافظ على اتساق عالٍ في الهوية والإضاءة أثناء هذه التحويلات.
4. إتاحة على عتادٍ استهلاكي
- كفاءة VRAM: يعمل بسلاسة على 6GB VRAM (مع التكميم) إلى 16GB VRAM (بدقة كاملة).
- تشغيل محلي: يدعم النشر المحلي عبر ComfyUI و
diffusers، مما يُحرّر المستخدمين من الاعتماد على السحابة.
كيف يعمل Z-Image؟
محوّل انتشار أحادي التيار (S3-DiT)
يبتعد Z-Image عن التصاميم الكلاسيكية ذات التيارين (مُشفرات/تيارات نص وصورة منفصلة)، وبدلًا من ذلك يربط رموز النص ورموز VAE للصورة ورموز الدلالات البصرية في مدخل مُحوّل واحد. هذا النهج أحادي التيار يحسّن استخدام المعاملات ويُبسّط المواءمة عبر الأنماط داخل العمود الفقري للمحوّل، وهو ما يقول المؤلفون إنه يُنتج مقايضة كفاءة/جودة مُواتية لنموذج بحجم 6B.
Decoupled-DMD وDMDR (تقطير + تعلم معزَّز)
لتمكين التوليد القليل الخطوات (8 خطوات) من دون عقوبة الجودة المعتادة، طوّر الفريق نهج تقطير Decoupled-DMD. تفصل التقنية تعزيز CFG (التوجيه الخالي من المصنّف) عن مطابقة التوزيع، مما يسمح بتحسين كل منهما على حدة. ثم يُطبقون خطوة تعلم معزَّز بعد التدريب (DMDR) لتحسين المواءمة الدلالية والجماليات. مجتمعةً، تُنتج هذه Z-Image-Turbo بعدد NFEs أقل بكثير من نماذج الانتشار المعتادة مع الحفاظ على واقعية عالية.
إنتاجية التدريب وتحسين التكلفة
تم تدريب Z-Image بنهج تحسين دورة الحياة: خطوط بيانات منتقاة، منهاج تدريجي مبسّط، وخيارات تنفيذ واعية بالكفاءة. يُفيد المؤلفون بإكمال سير التدريب الكامل في حوالي 314K ساعة GPU على H800 (≈ USD $630K) — مقياس هندسي صريح وقابل لإعادة الإنتاج يضع النموذج كخيار مُقتصد مقارنة بالبدائل الكبيرة جدًا (>20B).
نتائج معيارية لنموذج Z-Image
احتل Z-Image-Turbo مراتب عالية على عدة لوائح حديثة، بما في ذلك موقعًا مفتوح المصدر متقدمًا على لوحة Artificial Analysis للنص-إلى-صورة وأداء قوي في تقييمات تفضيلات البشر على Alibaba AI Arena.
لكن الجودة الواقعية تعتمد أيضًا على صياغة التوجيه، والدقة، وخط أنابيب الترقية، والمعالجة اللاحقة الإضافية.
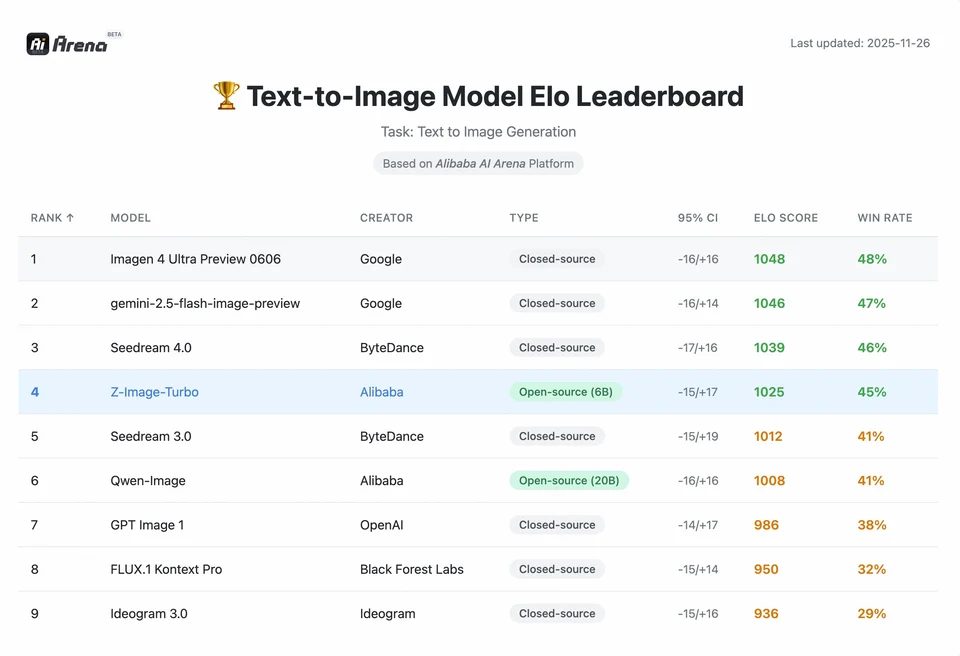
لفهم حجم إنجاز Z-Image، يجب أن ننظر إلى البيانات. أدناه تحليل مقارن لـZ-Image مقابل النماذج الرائدة المفتوحة المصدر والملكية.
ملخص المقارنة المعيارية
| الميزة / القياس | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| البنية | S3-DiT (تيار واحد) | MM-DiT (تياران) | U-Net | محول الانتشار |
| المعاملات | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| خطوات الاستدلال | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| الذاكرة المطلوبة (VRAM) | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| عرض النص | High (EN + CN) | High (EN) | Moderate (EN) | High (CN + EN) |
| سرعة التوليد (4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| درجة الواقعية الفوتوغرافية | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| الترخيص | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
تحليل البيانات ورؤى الأداء
- السرعة مقابل الجودة: رغم أن SDXL Turbo أسرع (خطوة واحدة)، إلا أن جودته تتدهور بشكل ملحوظ مع التوجيهات المعقّدة. يصل Z-Image-Turbo إلى «النقطة المثالية» عند 8 خطوات، فيُضاهي جودة Flux.2 بينما يكون أسرع 5x إلى 10x.
- ديمقراطية العتاد: على الرغم من قوة Flux.2، فهو فعليًا محجوب خلف بطاقات VRAM بسعة 24GB (RTX 3090/4090) لأداء معقول. يتيح Z-Image للمستخدمين ذوي البطاقات المتوسطة (RTX 3060/4060) توليد صور احترافية بدقة 1024x1024 محليًا.
كيف يمكن للمطورين الوصول إلى Z-Image واستخدامه؟
هناك ثلاثة أساليب نموذجية:
- استضافة / SaaS (واجهة ويب أو API): استخدم خدمات مثل z-image.ai أو مزودين آخرين ينشرون النموذج ويوفرون واجهة ويب أو API مدفوعًا لتوليد الصور. هذا أسرع طريق للتجربة دون إعداد محلي.
- Hugging Face + خطوط diffusers: تتضمن مكتبة
diffusersالتابعة لـHugging Face كلًا منZImagePipelineوZImageImg2ImgPipelineوتوفّر سير عمل اعتياديfrom_pretrained(...).to("cuda"). هذا المسار موصى به لمطوري Python الراغبين بتكامل مباشر وأمثلة قابلة لإعادة الإنتاج. - استدلال محلي أصيل من مستودع GitHub: يحتوي مستودع Tongyi-MAI على سكربتات استدلال أصلية وخيارات تحسين (FlashAttention، compilation، إزاحة إلى CPU)، وإرشادات لتثبيت
diffusersمن المصدر لأحدث تكامل. هذا المسار مفيد للباحثين والفرق التي ترغب بسيطرة كاملة أو تشغيل تدريب/ضبط مخصص.
كيف يبدو مثال Python الحد الأدنى؟
أدناه مقتطف Python موجز يستخدم diffusers من Hugging Face يوضّح توليد نص-إلى-صورة باستخدام Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
ملاحظات: تختلف القيم الافتراضية لـguidance_scale والإعدادات الموصى بها في نماذج Turbo؛ تُشير الوثائق إلى أنه قد يُضبط التوجيه على قيمة منخفضة أو صفر وفقًا للسلوك المستهدف.
كيف تُشغّل صورة-إلى-صورة (تحرير) باستخدام Z-Image؟
يدعم ZImageImg2ImgPipeline تحرير الصور. مثال:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
يعكس هذا الأنماط الرسمية للاستخدام وهو مناسب لمهام التحرير والملء (inpainting) الإبداعية.
كيف تتعامل مع التوجيهات وقيم الإرشاد؟
- كن صريحًا في البنية: للمشاهد المعقّدة، نظّم التوجيهات لتشمل تركيب المشهد، الكائن المحوري، الكاميرا/العدسة، الإضاءة، الحالة المزاجية، وأي عناصر نصية. يستفيد Z-Image من التوجيهات التفصيلية ويمكنه التعامل جيدًا مع الإشارات الموضعية/السردية.
- اضبط
guidance_scaleبعناية: قد تُوصي نماذج Turbo بقيم توجيه أقل؛ هناك حاجة للتجربة. في العديد من سير العمل لـTurbo، تُنتج القيمguidance_scale=0.0–1.0مع قيمة seed وخطوات ثابتة نتائج متّسقة. - استخدم صورة-إلى-صورة للتحكم في التعديلات: عندما تحتاج للحفاظ على التركيب مع تغيير النمط/التلوين/الكائنات، ابدأ بصورة مبدئية واستخدم
strengthللتحكم في مقدار التغيير.
أفضل حالات الاستخدام وأفضل الممارسات
1. النمذجة السريعة ورسم اللوحات القصصية
حالة الاستخدام: يحتاج المخرجون ومصممو الألعاب إلى تصور المشاهد فورًا.
لماذا Z-Image؟ مع توليد دون 3 ثوانٍ، يمكن للمبدعين تكرار مئات الأفكار في جلسة واحدة، وصقل الإضاءة والتركيب في الوقت الفعلي دون الانتظار دقائق من أجل التصيير.
2. التجارة الإلكترونية والإعلانات
حالة الاستخدام: توليد خلفيات المنتجات أو لقطات أسلوب حياة للسلع.
أفضل ممارسة: استخدم Z-Image-Edit.
ارفع صورة منتج خام واستخدم توجيهًا مثل: "ضع زجاجة العطر هذه على طاولة خشبية في حديقة مضيئة بالشمس." يحافظ النموذج على سلامة المنتج بينما «يهلوس» خلفية فوتوغرافية واقعية.
3. إنشاء محتوى ثنائي اللغة
حالة الاستخدام: حملات تسويق عالمية تتطلب أصولًا للأسواق الغربية والآسيوية.
أفضل ممارسة: استفد من قدرة عرض النص.
- توجيه: "لافتة نيون تقول 'OPEN' و'营业中' تتوهّج في زقاق مظلم."
- سيعرض Z-Image الأحرف الإنجليزية والصينية بشكل صحيح، وهو إنجاز يفشل معظم النماذج الأخرى في تحقيقه.
4. البيئات منخفضة الموارد
حالة الاستخدام: تشغيل التوليد على أجهزة الحافة أو الحواسيب المكتبية القياسية.
نصيحة تحسين: استخدم نسخة INT8 المُكمَّمة من Z-Image. هذا يُخفض استخدام VRAM إلى أقل من 6GB مع خسارة ضئيلة في الجودة، مما يجعله قابلًا للتطبيق للتطبيقات المحلية على الحواسيب غير المخصصة للألعاب.
الخلاصة: من يجب أن يستخدم Z-Image؟
صُمّم Z-Image للمنظمات والمطورين الذين يريدون واقعية فوتوغرافية عالية الجودة مع زمن انتظار وتكلفة عمليين، والذين يُفضّلون ترخيصًا مفتوحًا واستضافة داخلية أو مخصصة. يجذب بشكل خاص الفرق التي تحتاج إلى تكرار سريع (أدوات إبداعية، نماذج منتجات، خدمات فورية) والباحثين/أعضاء المجتمع المهتمين بإعادة ضبط نموذجٍ مُدمج لكن قوي.
تقدّم CometAPI نماذج Grok Image أقل تقييدًا بشكل مماثل، بالإضافة إلى نماذج مثل Nano Banana Pro، GPT- image 1.5، وSora 2(هل يمكن لـSora 2 توليد محتوى NSFW؟ كيف يمكننا تجربته؟) وغير ذلك — بشرط امتلاك نصائح وحيل NSFW المناسبة لتجاوز القيود والبدء في الإنشاء بحرية. قبل الوصول، يُرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح الـAPI. CometAPI تقدّم سعرًا أقل بكثير من السعر الرسمي لمساعدتك على التكامل.
مستعد للانطلاق؟→ تجربة مجانية للإنشاء !