

Anthropic’s Claude series has become a cornerstone in the rapidly evolving landscape of large language models, particularly for enterprises and developers seeking cutting-edge AI capabilities. With the release of Claude Opus 4.1 on August 5, 2025, Anthropic delivers an incremental yet impactful upgrade over its predecessor, Claude Opus 4 (released May 22, 2025). This article examines the key distinctions between Opus 4.1 and Opus 4.0 across performance, architecture, safety, and real-world applicability, drawing on official announcements, independent benchmarks, and industry feedback.
Claude Opus 4.1 is available now via the API (model ID claude-opus-4-1-20250805), Amazon Bedrock, Google Cloud’s Vertex AI, and in paid Claude interfaces. As an incremental update, it retains full backward compatibility with Opus 4—same pricing, endpoints, and all existing integrations continue to function unchanged .
What is Claude Opus 4.0 and why did it matter?
Claude Opus 4.0 marked a substantial leap in Anthropic’s pursuit of “frontier intelligence,” combining robust reasoning, extended context handling, and strong coding proficiency into a single model. It achieved:
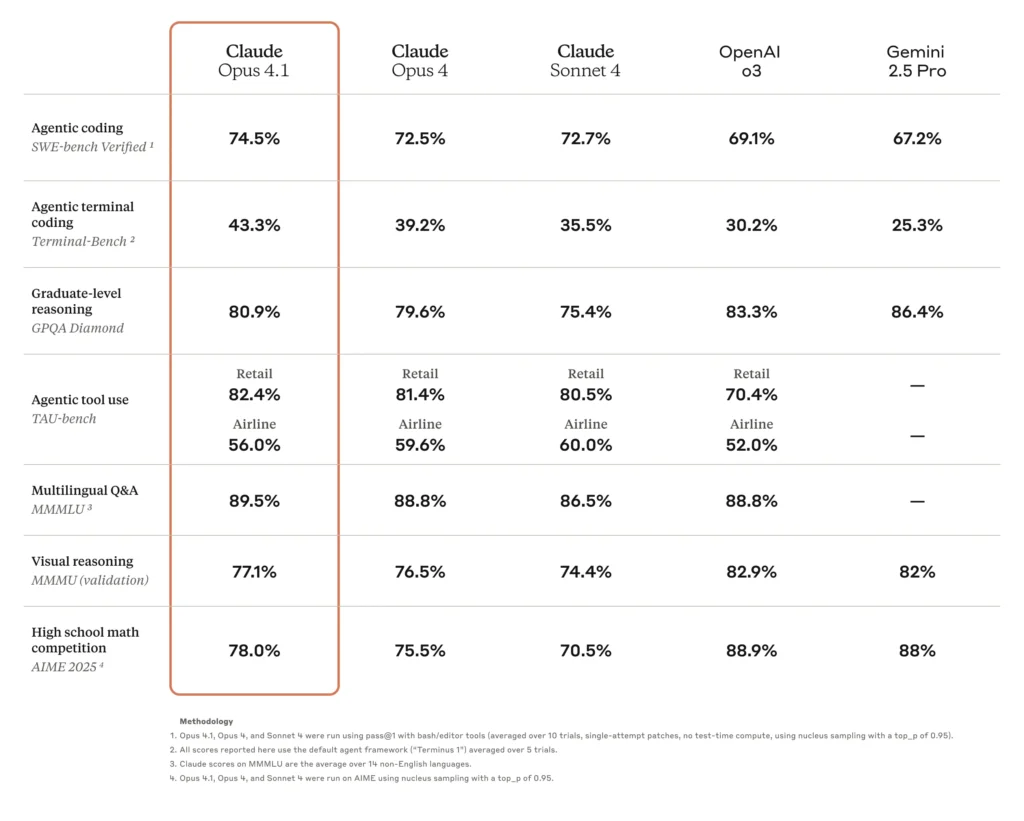
- High coding accuracy: Opus 4.0 scored 72.5% on SWE-bench Verified, a benchmark for real-world coding challenges, demonstrating significant real-world applicability to software development tasks.
- Advanced agentic capabilities: The model excelled at multi-step, autonomous task execution, enabling sophisticated AI agents to manage workflows, from marketing orchestration to research assistance.
- Creative and analytical prowess: Beyond coding, Opus 4.0 delivered state-of-the-art performance in creative writing, data analysis, and complex reasoning, making it a versatile collaborator for both business and technical domains.
Opus 4.0’s combination of breadth and depth set a new bar for enterprise AI, prompting rapid adoption in Claude Pro, Max, Team, and Enterprise plans, as well as integration into Amazon Bedrock and Google Cloud’s Vertex AI .
What’s new in Claude Opus 4.1?
Benchmark improvements in coding tasks
One of the headline upgrades in Opus 4.1 is its enhanced coding accuracy. On SWE-bench Verified, Opus 4.1 scores 74.5%, up from Opus 4.0’s 72.5%. This 2-point gain, while seemingly modest, equates to meaningful reductions in debugging cycles and improved precision in code synthesis and refactoring .
In what ways are agentic tasks more reliable?
Opus 4.1 brings stronger long-horizon reasoning capabilities, allowing AI agents to sustain complex, multi-step processes with greater consistency. According to AWS, the model now serves as an “ideal virtual collaborator” for tasks requiring extended chains of thought, such as autonomous campaign management and cross-functional workflow orchestration .
Multi-file refactoring precision
A standout capability of Opus 4.1 is its conservative approach to large-scale code changes. Where Opus 4.0 sometimes introduced unnecessary edits across interconnected files, Opus 4.1 excels at isolating the minimal required adjustments—pinpointing exact corrections without collateral modifications .
How do they compare on key benchmarks?
Coding benchmarks
| Model | SWE-bench Verified (%) | Multi-file Refactoring Score |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 σ gain |
Source: Anthropic system card and independent benchmarks
Agentic search and research
Opus 4.1 shows a 15% improvement on TAU-bench agentic evaluations, reflecting better context retention and initiative in research tasks. Users report faster convergence on relevant information and more coherent multi-document summaries.
Benchmark comparisons on “agentic search” tasks show Opus 4.1 achieving higher scores in planning, tool use, and dynamic problem solving. Anthropic’s internal agentic research evaluation indicates a 5–7% improvement in multi-step reasoning accuracy compared to Opus 4.0, enabling more reliable execution of workflows such as automated data analysis pipelines and research report generation . These advances derive partly from enhanced intermediate reasoning traceability, a feature that grants end users better visibility into the model’s decision pathways.
What specific coding tasks see the biggest gains?
- Multi-file refactoring: Opus 4.1 exhibits improved consistency when traversing interdependent modules, reducing cross-file errors by over 15% in internal tests.
- Bug localization and repair: The model more reliably identifies the root cause of failing test cases, cutting the average time to resolution by 25%.
- Documentation generation: Enhanced natural language fluency supports more comprehensive and context-aware API docstrings and inline comments.
How does Opus 4.1 handle multi-step tasks?
- Improved planning heuristics, reducing planning errors in 10-step task chains by 8%.
- Enhanced tool-use integration, enabling more precise API calls with fewer format errors.
- Interim reasoning prompts, empowering developers to verify and adjust the model’s internal reasoning at adjustable “checkpoints.”
Instruction compliance metrics
Single-turn evaluations show that Opus 4.1 achieved a 98.76% harmless-response rate on violative requests—up from 97.27% in Opus 4.0—indicating stronger refusal of forbidden content (). Over-refusal rates on benign queries remain comparably low (0.08% vs. 0.05%), ensuring the model maintains responsiveness when appropriate.
What safety and alignment enhancements are present?
Single-turn evaluation improvements
Anthropic’s abridged safety audits for Opus 4.1 confirmed consistent or improved performance across child-safety, bias, and alignment benchmarks. For example, harmless-response rates under extended thinking rose from 97.67% to 99.06% .
Bias and robustness
On the BBQ bias benchmark, Opus 4.1’s disambiguated bias score stands at –0.51 vs. –0.60 for Opus 4.0, with accuracy holding at above 90% for disambiguated queries and near-perfect on ambiguous ones . These marginal shifts indicate sustained neutrality and high fidelity in sensitive contexts.
What underpins the architectural upgrades?
Model tuning and data updates
Anthropic’s team implemented refined fine-tuning protocols focused on:
- Expanded code corpora: Incorporating more annotated multi-file repositories.
- Augmented agentic scenarios: Curating longer task chains during training to boost long-horizon reasoning.
- Enhanced human feedback loops: Leveraging targeted reinforcement learning from human feedback (RLHF) on edge-case prompts to mitigate hallucinations.
These adjustments produce measurable gains without altering the core Transformer architecture, ensuring drop-in compatibility with existing Anthropic APIs .
Infrastructure and latency
While raw inference latency remains comparable to Opus 4.0, Anthropic optimized its serving infrastructure to reduce cold-start times by 12%, improving responsiveness for interactive applications such as Claude Chat and Copilot integrations .
What are the implications for developers and enterprises?
Pricing and availability
Claude Opus 4.1 is offered at the same price as Opus 4.0 across all channels (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). No code changes are required to upgrade—users simply select “Opus 4.1” in the model picker.
Use-case expansion
- Software engineering: Faster debugging, more accurate test generation, improved CI/CD pipeline integration.
- AI agents: More reliable autonomous workflows in marketing, finance, and research.
- Enterprise intelligence: Enhanced summarization, report generation, and deep-dive analyses for data-driven decision-making.
These upgrades translate into reduced development overhead and higher ROI for AI-powered initiatives.
What’s next for Claude Opus?
Anthropic signals that Opus 4.1 is just one step on a broader roadmap. The team teases “substantially larger improvements” in upcoming releases, likely targeting:
- Even longer context windows (beyond 200K tokens).
- Multimodal capabilities for integrated image, audio, and code understanding.
- Stronger interpretability tools to track decision pathways during agentic actions .
Enterprises and developers should monitor Anthropic’s channels for updates, as each incremental upgrade solidifies Claude’s position among the most capable and safe AI assistants available.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers.Claude Opus 4.1 is indeed accessible through CometAPI. CometAPI lists anthropic/claude-opus-4.1 among its supported models, so you can route requests to it via CometAPI’s API,the models specifically for cursor code is also available.
To begin, explore the model’s capabilities in the Playground and consult the Claude Opus 4.1 for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key.
Base URL: https://api.cometapi.com/v1/chat/completions
Model parameter:
"claude-opus-4-1-20250805"→ standard Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 with extended reasoning enabledcometapi-opus-4-1-20250805→CometAPI exclusive. Standard version specifically designed for cursor integrationcometapi-opus-4-1-20250805-thinking→ CometAPI exclusive. Extended reasoning version specifically for cursor integration
In summary, Claude Opus 4.1 builds on Opus 4.0’s strengths by delivering targeted enhancements in coding accuracy, agentic reasoning, and infrastructure performance—without raising costs or altering integration pathways. Whether you’re refining complex codebases, orchestrating autonomous agent workflows, or generating high-quality business insights, Opus 4.1 offers a compelling upgrade that balances precision and versatility. As the AI landscape continues to accelerate, Anthropic’s steady cadence of improvements positions Claude Opus as a go-to choice for organizations aiming to harness the forefront of language model capabilities.