

Claude Sonnet 4.5 (commonly shorted to Claude 4.5) is Anthropic’s September 29, 2025 frontier release focused on long-horizon agentic work, coding, and “computer use” (automating multi-step tasks across tools). It delivers large jumps in autonomous coding duration, tool use, and aligned behavior, while keeping the same per-token pricing as the previous Sonnet release. For teams building agentic workflows, developer productivity stacks, and regulated enterprise applications, Claude 4.5 represents a compelling, cost-sensible option.
What Claude Sonnet 4.5 is
Claude Sonnet 4.5 is Anthropic’s next major Claude model iteration (branded “Sonnet 4.5”) designed to run longer, more complex multi-step tasks, operate software tools on behalf of users, and do production-grade coding and reasoning for enterprise customers. The release emphasizes agentic capabilities (models that can act autonomously across multiple steps and tools), tighter alignment/safety, and richer in-app functionality such as code execution and file creation (spreadsheets, slides, docs).
Key breakthroughs and features
1. Sustained, long-running agent capability
Anthropic reports Claude Sonnet 4.5 can maintain focused, multi-step operation for more than 30 hours on complex tasks — a step-change for workflows that require an AI to orchestrate many sub-tasks and handle evolving context over long time spans. This is central to the “agent” use cases Anthropic targets.
2. State-of-the-art coding & computer-use performance
Claude 4.5 achieved top results on SWE-Bench Verified (an industry coding benchmark) and shows major gains in the model’s ability to actually use a computer (execute tool calls, manage terminal/IDE workflows, build apps). Anthropic and independent press describe it as the leading model for coding tasks and “best in the world” on several software engineering measures. This includes improvements to autonomous code generation, debugging, and sustained code-execution sessions.
3. Improved tool orchestration, context management, and memory
To support long agent runs, Claude Sonnet 4.5 introduces better context-management tooling (automatic “context editing” to clear stale tool outputs) plus a file-backed memory tool that allows the model to persist and retrieve state across sessions. Those system features reduce context bloat and help agents stay “on task” across long workflows.
4. Better system / OS interaction
In internal tests described by Anthropic and reported by outlets, the new Claude Sonnet 4.5 variant shows substantial gains on system-use benchmarks (e.g., Anthropic reported a jump on an OS benchmarking task from ~40% to ~60% proficiency), meaning the model is measurably better at interacting with and controlling other software. That’s valuable when you want the model to operate tools (edit files, run builds, call APIs) reliably.
5. Developer tooling & integrations
Anthropic is shipping developer-facing tooling alongside Claude Sonnet 4.5: a Claude Agent SDK, native VS Code integration, terminal/IDE workflows, and product integrations such as rollout to GitHub Copilot (Copilot Pro/Enterprise previews). Those integrations shorten the path from prototype to production for engineering teams.
6. Alignment and safety improvements
Anthropic calls Claude Sonnet 4.5 “the most aligned frontier model” it has released; it is deployed under AI Safety Level 3 (ASL-3) protections and includes improved classifiers and defenses (e.g., against prompt injection), with reductions in problematic behaviors reported by Anthropic.
Performance benchmarks — what the numbers mean
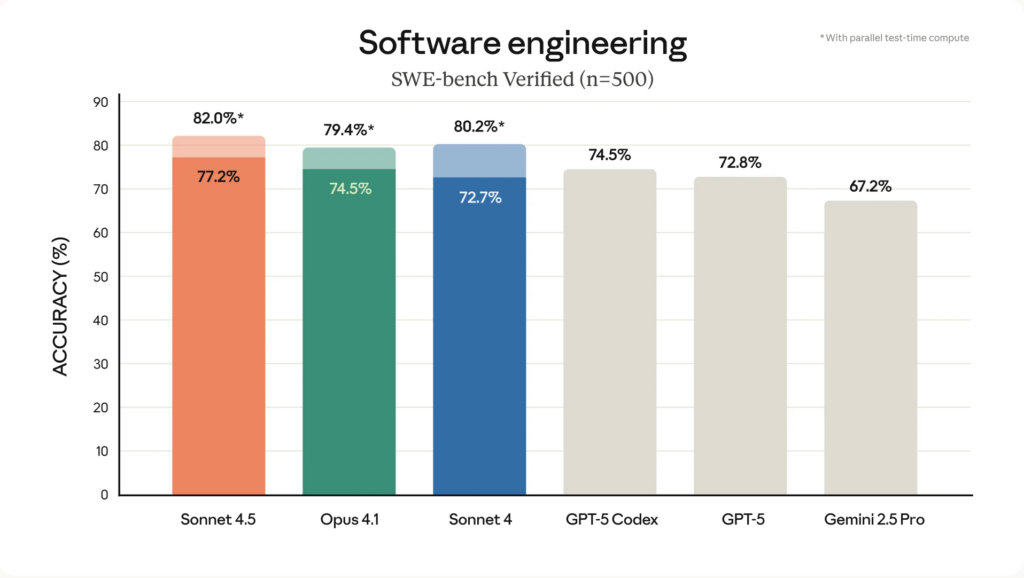
Anthropic’s announcement publishes several headline numbers (SWE-bench, OSWorld, internal terminal/agent benchmarks). Key published figures from Anthropic:
- SWE-bench Verified: 77.2% (200K thinking budget, scaffold + tools); 78.2% in 1M context; 82.0% reported for a “high-compute” candidate selection regime.
- OSWorld (computer tasks): 61.4% for Sonnet 4.5 vs 42.2% for Sonnet 4 (four months earlier).
- Autonomy length (internal tests): >30 hours continuous autonomous coding/agent operation (previous generation ~7 hours).
- Operating-system/tool benchmark: Anthropic reports a jump to ~60% versus ~40% for the predecessor on an OS interaction benchmark — showing improved reliability when the model controls software.
Pricing (developer / API)
Anthropic lists the Sonnet 4.5 developer pricing consistent with Sonnet 4: $3 per million input tokens and $15 per million output tokens (with standard savings available through prompt caching and batching). Sonnet 4.5 is available via the Claude API and the Claude apps. Enterprise and volume discounts / product tiers (Pro/Max/Team/Enterprise) are available through Anthropic’s commercial channels.
Why choose Claude Sonnet 4.5? Use cases where it shines
Agentic automation & orchestration
If you need models that run long workflows (multi-hour/days), manage memory across steps, coordinate subagents, or autonomously operate tools (terminals, web UIs, spreadsheets), Sonnet 4.5’s focus on sustained coherence and a dedicated Agent SDK is a major advantage.
Production coding and developer productivity
Anthropic’s benchmarks and partner reports (e.g., GitHub Copilot integrations) indicate Sonnet 4.5 can handle multi-file codebase edits, testing, and long debugging sessions—useful where developers want an assistant that can author, test, and iterate with less human prompting.
Regulated and enterprise contexts
Stronger alignment and ASL-3 deployment make Sonnet 4.5 attractive to finance, legal, security, and healthcare teams that need higher guardrails and documented safety practices. Anthropic explicitly positions the model at enterprise customers.
Cost-sensitive production usage
Because Sonnet 4.5 keeps Sonnet-level pricing (~$3/$15 per million tokens), the cost/performance tradeoff for heavy agentic workloads looks favorable compared with some higher-priced frontier models—especially when you factor in prompt caching and other platform optimizations
Consider alternatives if:
- Your priority is the lowest possible latency or the cheapest per-token inference for basic Q&A; lighter models or other vendors’ distilled models may be cheaper/faster for simple workloads. (Pricing and cost structure vary; compare per-token output pricing and caching strategies.)
When to choose Claude Sonnet 4.5 — practical guidance
Pick Claude Sonnet 4.5 if:
- You need an LLM to operate tools reliably over long sequences (agent orchestration, automation pipelines, autonomous assistants).
- Your primary workload is software engineering at scale (automated coding, long debug sessions, continuous integration tasks) — Sonnet 4.5 is reported to excel on SWE-Bench and related code benchmarks.
- You work in regulated or high-risk domains (legal, finance, security) and require a model tuned for more predictable, auditable behavior and safer outputs. Anthropic emphasizes enterprise reliability and safety.
Consider alternatives if:
Your priority is the lowest possible latency or the cheapest per-token inference for basic Q&A; lighter models or other vendors’ distilled models may be cheaper/faster for simple workloads. (Pricing and cost structure vary; compare per-token output pricing and caching strategies.)
How to Access Claude Sonnet 4.5
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Claude Sonnet 4.5 and Claude Sonnet 4 through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
Conclusion
Claude Sonnet 4.5 is a targeted evolution: it’s not just “a bit better at chat.” Anthropic designed it to be a reliable agent builder — one that can stay on task for long periods, orchestrate tools and code, and handle domain-heavy workflows (legal, financial, cybersecurity, and engineering). If your production use cases require robust tool orchestration, extended context stability, and top-tier coding performance — and you want to keep predictable per-token pricing — Claude 4.5 deserves a formal technical trial in your environment.