

I sine oktoberopdateringer rapporterede OpenAI, at omkring 0.15 % af ugentlige aktive brugere have samtaler, der indeholder eksplicitte indikatorer for potentiel selvmordsplanlægning eller -intention – en andel, der, når den skaleres til ChatGPT's store brugerbase, svarer til mere end en million mennesker hver uge Ved at diskutere selvmordsrelaterede emner med tjenesten har det rettet fokus mod et anspændt spørgsmål: Kan store sprogmodeller reagere meningsfuldt og sikkert, når folk bringer alvorlige psykiske bekymringer - herunder psykose, mani, selvmordstanker og dyb følelsesmæssig afhængighed - ind i en samtale?
Derfor blev OpenAIs oktoberopdateringer til GPT-5 – rullet i produktion som gpt-5-oct-3 opdatering — repræsenterer virksomhedens mest eksplicitte, afmålte pres for at gøre store sprogmodeller (LLM'er) sikrere og mere nyttige, når brugerne rejser bekymringer om mental sundhed. Ændringerne er ikke en enkeltstående magisk løsning; de er et sæt tekniske, procesmæssige og evalueringsmæssige tiltag, der har til formål at reducere skadelige eller uhensigtsmæssige output, afdække professionelle ressourcer og afskrække brugere fra at stole på modellen som en erstatning for klinisk behandling. Men hvor meget bedre er systemet i praksis, hvad er præcist ændret, og hvad er de resterende risici?
Hvad opdaterede OpenAI i gpt-5 om, og hvorfor er det vigtigt?
OpenAI implementerede en opdatering til ChatGPTs standard GPT-5-model (almindeligvis omtalt i kommunikation som gpt-5-oct-3) specifikt beregnet til at styrke modellens adfærd i følsomme samtaler — dem, der omfatter tegn på psykose eller mani, selvmordstanker eller -planlægning eller den form for følelsesmæssig afhængighed af en AI, der kan fortrænge forhold i den virkelige verden.
Ændringerne blev informeret af konsultationer med mere end 170 eksperter inden for mental sundhed og af nye interne taksonomier og automatiserede evalueringer designet omkring konkrete "ønskede adfærdsmønstre", efter at være blevet optimeret af psykologieksperter, GPT-5-modellen:
- På målrettede mentale sundhedsudfordringssæt scorede den nye GPT-5-model ~ 92% i overensstemmelse med virksomhedens taksonomi for ønsket adfærd (sammenlignet med meget lavere procentdele for tidligere versioner på vanskelige testsæt).
- For selvskade- og selvmordsscenarier steg automatiserede evalueringer til ~ 91% overholdelse fra 77% på den tidligere GPT-5-variant i den specifikke benchmark, der er beskrevet. OpenAI rapporterer også ~ 65% reduktion i antallet af svar, der "ikke fuldt ud overholder reglerne" på tværs af flere domæner inden for mental sundhed i produktionstrafikken.
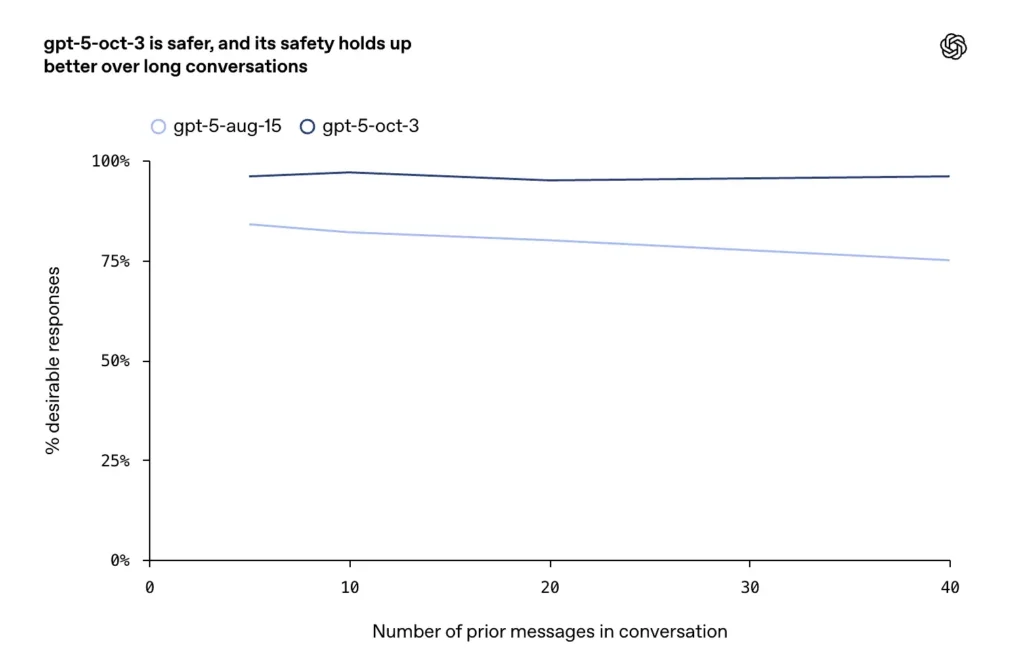
- Der blev rapporteret forbedringer på lange, konfliktfyldte eller langvarige samtaler (en kendt fejltilstand for chatmodeller), hvor virksomheden siger, at oktoberopdateringerne opretholder højere konsistens og sikkerhed på tværs af længerevarende dialogrunder.
hvorfor betyder det noget
OpenAI sagde, at – givet ChatGPTs nuværende skala – svarer selv meget små procentdele af følsomme samtaler til meget store absolutte antal personer. Virksomheden rapporterede, at i en typisk uge:
- om 0.07% af aktive brugere viser mulige tegn, der stemmer overens med psykose eller mani; og
- om 0.15% af aktive brugere har samtaler, der indeholder eksplicitte indikatorer for potentiel selvmordsplanlægning eller -intention; og
- groft 0.15% af aktive brugere viser "forhøjede niveauer" af følelsesmæssig tilknytning til ChatGPT.
For at gøre disse procenter konkrete: OpenAIs administrerende direktør sagde, at ChatGPT har ~800 millioner ugentlige aktive brugereMultiplikation giver absolutte brugerantal:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Kategorierne er støjende og overlappende (en enkelt samtale kan forekomme i mere end én kategori), og at disse er skøn afledt af interne detektionstaksonomier snarere end kliniske diagnoser.
Hvordan implementerede OpenAI disse ændringer – en forbedringsmekanisme i fem trin?
OpenAI beskriver en flerstrenget, ekspertinformeret proces. Nedenfor er en destilleret, reproducerbar femtrins forbedringsmekanisme der stemmer overens med virksomhedens oplysninger og almindelig praksis inden for modelsikkerhedsteknik.
Fem-trins forbedringsmekanisme
- Ekspertstyret taksonomi og mærkning. Indkald psykiatere, psykologer og praktiserende læger for at definere den adfærd og det sprog, der indikerer psykose/mani, selvskade eller usund følelsesmæssig afhængighed; opbyg mærkede datasæt og vurderingsregler.
- Målrettet dataindsamling og kuraterede prompts. Saml repræsentative samtaleuddrag, eksempler på kantscenarier og input fra modparter; suppler med kontrollerede rollespilsudskrifter produceret under klinikertilsyn.
- Modeljustering / finjustering med sikkerhedsmål. Træn eller finjuster basismodellen på det kuraterede datasæt med tabsudtryk, der straffer forstærkning af vrangforestillinger, leverer skabeloner til sikre reaktioner og fremmer routing til kriseressourcer.
- Klassifikator + rækværkslag (kørselssikkerhed). Implementer en hurtig klassifikator eller et overvågningslag, der registrerer højrisiko-vendinger i realtid og enten ændrer modellens afkodningsparametre, skifter til en specialiseret responder eller eskalerer til menneskelige gennemgangspipelines. (Dette er afgørende for at undgå skrøbelig adfærd, når samtalen glider af sporet.)
- Menneskelig ekspertvurdering og løbende kalibrering. Få klinikere til at blindvurdere modelresponser ved hjælp af kliniske evalueringsrubrikker; mål uønskede responsrater; iterer på taksonomien, træningsdata og systemprompter. Vedligehold produktionstelemetri og gentag benchmarks regelmæssigt.
Nedenfor er en kompakt pseudokode/teknisk skitse, der indfanger det runtime-flow, som de fleste sikkerhedsteams implementerer (dette er illustrativ og ikke-proprietær):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Produktionspipelinen kombinerer typisk kortsigtede klassifikatorer (hurtige), langsomme, men højkvalitets respondenter (specialiserede prompts/justerede checkpoints) og menneskelig gennemgang af markerede tilfælde. Dette er ikke udelukkende akademisk: klinikere har gennemgået over 1,800 modelsvar og bedømte dem i forhold til taksonomien, og at disse gennemgange i væsentlig grad formede, hvordan prompts og fallback-adfærd blev skrevet.
OpenAIs offentlighed angiver, at de brugte variationer af alle fem trin og klinikervurderinger til at evaluere resultaterne:
- Eksperter gennemgik over 1,800 modelsvar.
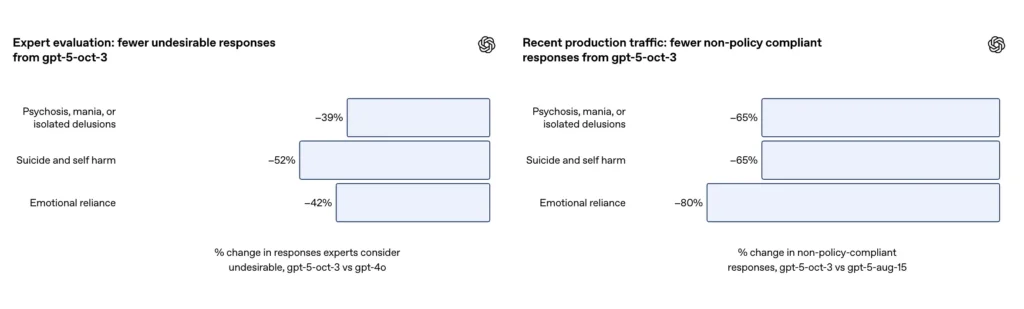
- GPT-5 reducerede "utilfredsstillende svar" med 39-52% på tværs af alle kategorier.
- Interrater-reliabiliteten varierede fra 71-77%, hvilket indikerer en høj grad af generel konsensus på trods af subjektive forskelle.
Hvordan reagerer GPT-5 nu på psykose eller mani?
Hvad OpenAI lærte modellen at gøre (og ikke gøre)
Måle: Forbedre modellens genkendelse og reaktion på alvorlige symptomer såsom hallucinationer og mani. For samtaler, der signalerer mulige vrangforestillinger, hallucinationer eller mani, omskrev OpenAI dele af modelspecifikationen og leverede eksempler på superviseret træning, så GPT-5 reagerer uden at bekræfte eller forstærke ubegrundede overbevisninger. Modellen opfordres til at være empatisk, undgå at validere vrangforestillinger og forsigtigt omformulere eller omdirigere en bruger til praktiske sikkerhedstrin og professionel hjælp, når det er berettiget.
Hvad evalueringen viser
OpenAI rapporterer, at den nyere GPT-5 reducerede uønskede reaktioner betydeligt i et testsæt af udfordrende samtaler om psykose/mani sammenlignet med tidligere baselines, og at automatiserede evalueringer scorer den opdaterede model som høj compliance på deres taksonomi.
| metric | GPT-4o | GPT-5 | Forbedring |
|---|---|---|---|
| Ikke-overensstemmende svarprocent | Baseline | ↓ 65% | Betydelig forbedring |
| Klinisk ekspertvurdering | — | Reducerede bivirkninger med 39% | — |
| Overholdelsesgrad for automatisk evaluering | 27% | 92% | ↑65 procentpoint |
| Brugerinvolveringsrate | ~0.07% ugentlige aktive brugere | Ekstremt lav, men tydeligt overvåget | — |
Bemærk:
- Upassende svar faldt med 65%;
- Kun 0.07 % af brugerne og 0.01 % af beskederne indeholdt sådant indhold;
- I ekspertvurderinger producerede GPT-5 39 % færre upassende reaktioner end GPT-4o;
- I automatiserede vurderinger opnåede GPT-5 en compliance-rate på 92 % (sammenlignet med 27 % for sin forgænger).
Hvordan håndterer GPT-5 selvmordstanker og selvskade?
Stærkere routing til støtte og afvisning af at give instruktioner
OpenAI beskriver udvidet og eksplicit træning i selvskade- og selvmordstilfælde: modellen er trænet til at genkende direkte og indirekte signaler om hensigt eller planlægning, anvende empatisk og deeskalerende sprog, præsentere kriseressourcer (hotlines, lokale nødinstruktioner) og nægte at give instruktioner om selvskade. Oktoberopdateringerne understreger mere holdbar adfærd i lange samtaler, hvor tidligere modeller nogle gange gled hen imod usikre eller inkonsistente svar.
Målte resultater
På baggrund af et kurateret evalueringssæt af udfordrende samtaler om selvskade og selvmord rapporterer OpenAI, at den opdaterede GPT-5 opnåede resultater 91 % overensstemmelse med OpenAIs ønskede adfærd, sammenlignet med 77% for den tidligere GPT-5-model. Virksomheden siger også, at fageksperter vurderede, at den opdaterede model reducerede uønskede svar med omtrent 52% versus GPT-4o på det samme problemsæt. Derudover hævder OpenAI et anslået reduktion 65% i produktionstrafik af svar, der "ikke fuldt ud overholder" deres taksonomi for selvskadesituationer efter implementeringen af de nye sikkerhedsforanstaltninger.
| metric | GPT-4o | GPT-5 | Forbedring |
|---|---|---|---|
| Upassende svarprocent | Baseline | ↓ 65% | Betydelig forbedring |
| Klinisk ekspertvurdering | — | Upassende svar reduceret med 52% | — |
| Overholdelsesgrad for automatisk evaluering | 77% | 91% | ↑14 procentpoint |
| Brugerinvolveringsrate | 0.15 % ugentligt (millioner af brugere) | Meget lav, men socialt betydningsfuld | — |
Bemærk:
- Upassende svar faldt med 65%;
- Cirka 0.15 % af brugerne og 0.05 % af beskederne involverede potentielle selvmordsrisici;
- Ekspertvurderinger viste, at GPT-5 reducerede upassende reaktioner med 52% sammenlignet med GPT-4;
- Overholdelsesraten i automatiserede evalueringer steg til 91 % (sammenlignet med 77 % for den foregående generation);
- I længerevarende samtaler opretholdt GPT-5 over 95% stabilitet.
Hvad er "følelsesmæssig afhængighed", og hvordan håndteres det?
Udfordringen med at brugerne danner vedhæftede filer
OpenAI definerer følelsesmæssig afhængighed som mønstre, hvor en bruger viser potentielt usund afhængighed af AI'en til skade for virkelige relationer, ansvar eller velvære. Dette er ikke en umiddelbar fysisk sikkerhedsfejl, sådan som instruktioner om selvskade er, men det er et adfærdsmæssigt sikkerhedsproblem, der kan undergrave en persons sociale støtte og modstandsdygtighed over tid. Virksomheden gjorde følelsesmæssig afhængighed til en eksplicit kategori i sit modelspecifikationsarbejde og lærte modellen at fremme forbindelse i den virkelige verden, at normalisere det at række ud til mennesker og at undgå sprog, der forstærker eksklusivitet af tilknytning.
I disse samtaler blev modellen trænet til at:
- Opfordr brugerne til at kontakte venner, familie eller en terapeut;
- Undgå at forstærke tilknytningen til AI'en;
- Reager på vrangforestillinger eller falske overbevisninger på en blid og rationel måde.
Resultater rapporteret
Ifølge OpenAIs tillæg producerede opdateringen en ~80% reduktion i antallet af modelresponser, der ikke fuldt ud overholder taksonomien for følelsesmæssig afhængighed i produktionstrafik. På kuraterede evalueringssamtaler scorede automatiserede evalueringer den opdaterede model til 97 % overensstemmelse med ønsket adfærd for scenarier med følelsesmæssig afhængighed, sammenlignet med 50 % for den tidligere GPT-5. Tallene tyder på en stor forbedring i forhold til den specifikke taksonomi og testsættet; måling af følelsesmæssig afhængighed i naturen er dog i sagens natur støjende og følsom over for kulturelle og kontekstuelle forskelle.
| metric | GPT-4o | GPT-5 | Forbedring |
|---|---|---|---|
| Ikke-overensstemmende svarprocent | 50% | 97 % kompatibel | ↓80% upassende svar |
| Ekspertvurdering | Upassende svar reduceret med 42% | — | — |
| Brugerinvolveringsrate | 0.15 % brugere/uge, 0.03 % beskeder | Sjælden, men findes | — |
| Model adfærd | Opmuntrer til virkelige forhold; afviser "simuleret social romance" | — | — |
Bemærk:
- Upassende svar faldt med 80%;
- Cirka 0.15 % af brugerne/0.03 % af beskederne viste tegn på potentiel følelsesmæssig afhængighed af AI'en;
- Ekspertvurdering viste, at GPT-5 reducerede uhensigtsmæssige reaktioner med 42% sammenlignet med GPT-4;
- Overholdelse af reglerne for automatiseret evaluering forbedredes markant fra 50 % til 97 %.
Hvad er grænserne og de udestående risici?
Falske negative og falske positive resultater
- Falske negativerModellen kan muligvis ikke identificere subtile eller kodificerede signaler om, at en bruger er i akut fare – især når folk kommunikerer indirekte eller i kode.
- Falske positive tingSystemet kan eskalere eller sende krisebeskeder i tilfælde, der ikke kræver det, hvilket kan undergrave brugertilliden eller skabe unødvendig alarm. Begge fejltyper er vigtige, fordi de former brugeradfærd og opfattelse af pleje. OpenAI anerkender, at detektion er ufuldkommen.
Overdreven afhængighed af automatisering
Selv den bedste model kan opfordre nogle brugere til at stole på øjeblikkelige, altid tilgængelige AI-responser i stedet for at søge vedvarende menneskelig støtte. OpenAI markerer eksplicit følelsesmæssig afhængighed som en sikkerhedskategori på grund af denne risiko; virksomhedens opdateringer forsøger at skubbe brugerne mod menneskelig forbindelse, men sociale dynamikker er vanskelige at ændre alene ved hjælp af beskedprompter.
Kontekstuelle og kulturelle huller
Sikkerhedsfraser, der ser passende ud i én kultur eller et bestemt sprog, kan overse nuancer i en anden. Grundig lokalisering og kulturelt bevidst evaluering er nødvendig; OpenAIs offentliggjorte resultater giver endnu ikke fuldstændige opdelinger efter sprog eller region.
Juridisk og etisk eksponering
Når sjældne fejl har alvorlige konsekvenser, står virksomheder over for juridisk og omdømmemæssig risiko (som mediedækning og retssager har fremhævet). OpenAIs gennemsigtighed omkring problemets størrelse og virksomhedens indsats for at afbøde skader er et vigtigt skridt, men det opfordrer også til lovgivningsmæssig og juridisk kontrol.
Så — kan GPT-5 nu håndtere psykiske problemer?
Kort svar: Det er betydeligt bedre til mange snævre, målbare opgaver, og OpenAIs offentliggjorte målinger viser betydelige reduktioner i uønskede reaktioner på tværs af testpakker for selvskade, psykose/mani og følelsesmæssig afhængighed. Det er reelle forbedringer, muliggjort af ekspertinput, klarere taksonomier samt aggressiv evaluering og overvågning. Virksomhedens offentlige tal - høje compliance-rater og kraftige reduktioner i ikke-compliance-responser på kuraterede sæt - er det stærkeste bevis hidtil på, at bevidst, tværfaglig ingeniørvidenskab og klinisk samarbejde væsentligt kan ændre modeladfærd.
Hvordan får man adgang til den nyeste GPT-5 API?
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere – såsom OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i en enkelt, udviklervenlig grænseflade. Ved at tilbyde ensartet godkendelse, formatering af anmodninger og svarhåndtering forenkler CometAPI dramatisk integrationen af AI-funktioner i dine applikationer. Uanset om du bygger chatbots, billedgeneratorer, musikkomponister eller datadrevne analysepipelines, giver CometAPI dig mulighed for at iterere hurtigere, kontrollere omkostninger og forblive leverandøruafhængig – alt imens du udnytter de seneste gennembrud på tværs af AI-økosystemet.
Udviklere kan få adgang GPT-5 API gennem Comet API, den nyeste modelversion opdateres altid med den officielle hjemmeside. For at begynde, udforsk modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!