

Anthropics Claude-serie er blevet en hjørnesten i det hastigt udviklende landskab af store sprogmodeller, især for virksomheder og udviklere, der søger banebrydende AI-funktioner. Med udgivelsen af Claude Opus 4.1 den 5. august 2025 leverer Anthropic en trinvis, men effektiv opgradering i forhold til sin forgænger, Claude Opus 4 (udgivet 22. maj 2025). Denne artikel undersøger de vigtigste forskelle mellem Opus 4.1 og Opus 4.0 på tværs af ydeevne, arkitektur, sikkerhed og anvendelighed i den virkelige verden, baseret på officielle annonceringer, uafhængige benchmarks og feedback fra branchen.
Claude Opus 4.1 er nu tilgængelig via API'en (model-ID claude-opus-4-1-20250805), Amazon Bedrock, Google Clouds Vertex AI og i betalte Claude-grænseflader. Som en trinvis opdatering bevarer den fuld bagudkompatibilitet med Opus 4 – samme priser, endpoints og alle eksisterende integrationer fortsætter med at fungere uændret.
Hvad er Claude Opus 4.0, og hvorfor var det vigtigt?
Claude Opus 4.0 markerede et betydeligt spring i Anthropics stræben efter "frontier intelligence" ved at kombinere robust ræsonnement, udvidet konteksthåndtering og stærke kodningsfærdigheder i én model. Den opnåede:
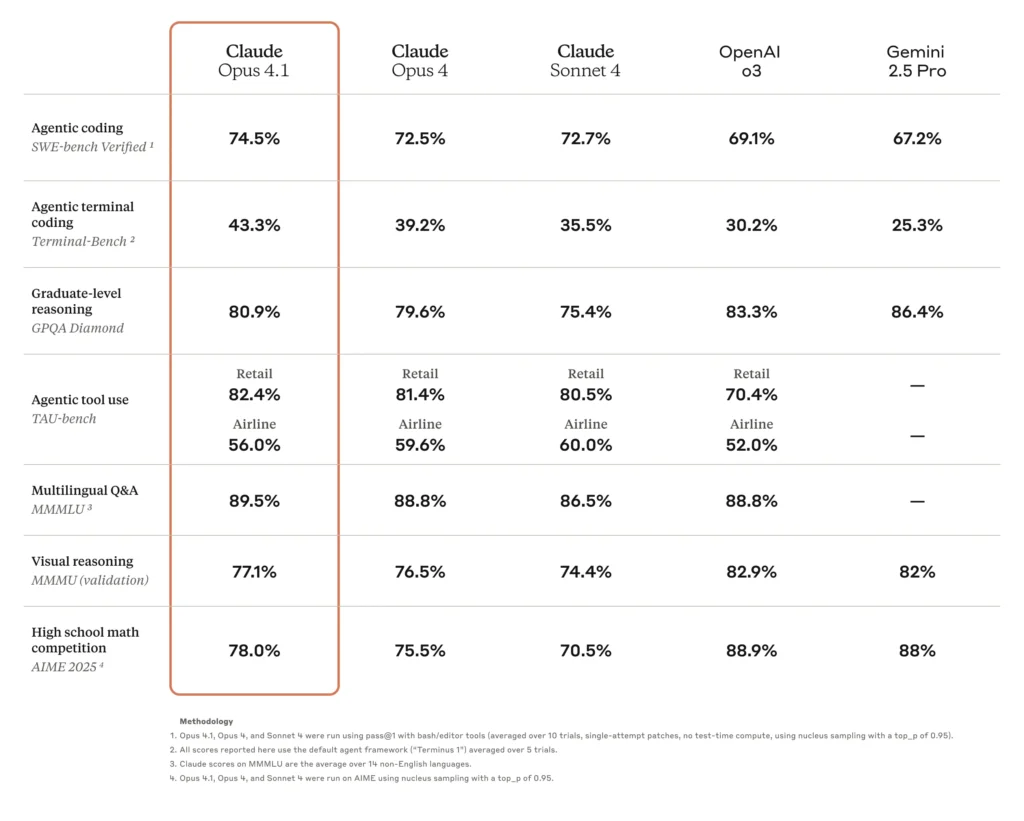
- Høj kodningsnøjagtighedOpus 4.0 scorede 72.5% på SWE-bench Verified, en benchmark for virkelige kodningsudfordringer, hvilket demonstrerer betydelig anvendelighed i den virkelige verden til softwareudviklingsopgaver.
- Avancerede agentfunktionerModellen udmærkede sig ved autonom opgaveudførelse i flere trin, hvilket gjorde det muligt for sofistikerede AI-agenter at styre arbejdsgange, lige fra marketingorkestrering til researchassistance.
- Kreativ og analytisk evneUd over kodning leverede Opus 4.0 state-of-the-art ydeevne inden for kreativ skrivning, dataanalyse og kompleks ræsonnement, hvilket gjorde den til en alsidig samarbejdspartner inden for både forretningsmæssige og tekniske domæner.
Opus 4.0's kombination af bredde og dybde satte en ny standard for virksomheds-AI, hvilket førte til hurtig implementering i Claude Pro-, Max-, Team- og Enterprise-abonnementer samt integration i Amazon Bedrock og Google Clouds Vertex AI.
Hvad er nyt i Claude Opus 4.1?
Benchmark forbedringer i kodningsopgaver
En af de vigtigste opgraderinger i Opus 4.1 er dens forbedrede kodningsnøjagtighed. På SWE-bench verificeret scorer Opus 4.1 74.5%, en stigning fra Opus 4.0's 72.5%. Denne stigning på 2 point, omend tilsyneladende beskeden, svarer til betydelige reduktioner i fejlfindingscyklusser og forbedret præcision i kodesyntese og refactoring.
På hvilke måder er agentopgaver mere pålidelige?
Opus 4.1 bringer stærkere langsigtede ræsonnementsevner, der giver AI-agenter mulighed for at opretholde komplekse, flertrinsprocesser med større konsistens. Ifølge AWS fungerer modellen nu som en "ideel virtuel samarbejdspartner" til opgaver, der kræver udvidede tankekæder, såsom autonom kampagnestyring og tværfunktionel workfloworkestrering.
Præcision i refaktorering af flere filer
En fremragende funktion ved Opus 4.1 er dens konservative tilgang til store kodeændringer. Hvor Opus 4.0 nogle gange introducerede unødvendige redigeringer på tværs af sammenkoblede filer, udmærker Opus 4.1 sig ved at isolere de minimalt nødvendige justeringer – og dermed præcist identificere korrektioner uden sideordnede ændringer.
Hvordan klarer de sig i forhold til vigtige benchmarks?
Kodningsbenchmarks
| Model | SWE-bænk verificeret (%) | Score for refaktorering af flere filer |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 σ forstærkning |
Kilde: Antropisk systemkort og uafhængige benchmarks
Agentsøgning og -research
Opus 4.1 viser en 15% forbedring af TAU-bench agentiske evalueringer, hvilket afspejler bedre kontekstfastholdelse og initiativ i forskningsopgaver. Brugere rapporterer hurtigere konvergens af relevante oplysninger og mere sammenhængende resuméer af flere dokumenter.
Benchmark-sammenligninger af "agentisk søgning"-opgaver viser, at Opus 4.1 opnår højere scorer inden for planlægning, værktøjsbrug og dynamisk problemløsning. Anthropics interne evaluering af agentisk forskning indikerer en forbedring på 5-7% i nøjagtigheden af flertrinsræsonnement sammenlignet med Opus 4.0, hvilket muliggør mere pålidelig udførelse af arbejdsgange såsom automatiserede dataanalysepipelines og generering af forskningsrapporter. Disse fremskridt stammer delvist fra forbedret sporbarhed af mellemliggende ræsonnement, en funktion, der giver slutbrugerne bedre indsigt i modellens beslutningsveje.
Hvilke specifikke kodningsopgaver oplever de største gevinster?
- Refaktorering af flere filerOpus 4.1 udviser forbedret konsistens ved gennemgang af indbyrdes afhængige moduler og reducerer fejl på tværs af filer med over 15 % i interne tests.
- Fejllokalisering og reparationModellen identificerer mere pålideligt den grundlæggende årsag til fejlende testsager og reducerer den gennemsnitlige tid til løsning med 25 %.
- Generering af dokumentationForbedret flydende naturligt sprog understøtter mere omfattende og kontekstbevidste API-dokumentstrenge og indlejrede kommentarer.
Hvordan håndterer Opus 4.1 opgaver med flere trin?
- Forbedret planlægningsheuristik, hvilket reducerer planlægningsfejl i 10-trins opgavekæder med 8 %.
- Forbedret integration af værktøjsbrug, hvilket muliggør mere præcise API-kald med færre formatfejl.
- Midlertidige ræsonnementsspørgsmål, hvilket giver udviklere mulighed for at verificere og justere modellens interne ræsonnement ved justerbare "tjekpunkter".
Målinger af overholdelse af instruktioner
Evalueringer af én tur viser, at Opus 4.1 opnåede en harmløs responsrate på 98.76 % på overtrædende anmodninger – en stigning fra 97.27 % i Opus 4.0 – hvilket indikerer en stærkere afvisning af forbudt indhold (). Overafvisningsrater på godartede forespørgsler forbliver forholdsvis lave (0.08 % vs. 0.05 %), hvilket sikrer, at modellen opretholder responsiviteten, når det er relevant.
Hvilke sikkerheds- og justeringsforbedringer er der til stede?
Forbedringer af enkelt-turn evaluering
Anthropics forkortede sikkerhedsrevisioner for Opus 4.1 bekræftede ensartet eller forbedret præstation på tværs af benchmarks for børns sikkerhed, bias og tilpasning. For eksempel steg harmløse responsrater under udvidet tænkning fra 97.67% til 99.06%.
Bias og robusthed
På BBQ bias-benchmarken ligger Opus 4.1's flertydige bias-score på –0.51 vs. –0.60 for Opus 4.0, med en nøjagtighed på over 90 % for flertydige forespørgsler og næsten perfekt for flertydige. Disse marginale forskydninger indikerer vedvarende neutralitet og høj kvalitet i følsomme kontekster.
Hvad ligger til grund for de arkitektoniske forbedringer?
Modeljustering og dataopdateringer
Anthropics team implementerede raffinerede finjusteringsprotokoller med fokus på:
- Udvidet kodekorpus: Inkorporerer flere annoterede multifillagre.
- Scenarier for udvidede agenterUdvikling af længere opgavekæder under træning for at fremme langsigtet ræsonnement.
- Forbedrede menneskelige feedback-loopsUdnyttelse af målrettet forstærkningslæring fra menneskelig feedback (RLHF) på edge-case-prompts for at afbøde hallucinationer.
Disse justeringer giver målbare gevinster uden at ændre den centrale Transformer-arkitektur, hvilket sikrer drop-in-kompatibilitet med eksisterende Anthropic API'er.
Infrastruktur og latenstid
Selvom den rå inferensforsinkelse forbliver sammenlignelig med Opus 4.0, optimerede Anthropic sin serveringinfrastruktur for at reducere koldstarttider med 12%, forbedrer responsiviteten for interaktive applikationer såsom Claude Chat og Copilot-integrationer.
Hvad er konsekvenserne for udviklere og virksomheder?
Pris og tilgængelighed
Claude Opus 4.1 tilbydes hos samme pris som Opus 4.0 på tværs af alle kanaler (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Der kræves ingen kodeændringer for at opgradere – brugerne skal blot vælge "Opus 4.1" i modelvælgeren.
Udvidelse af brugsscenarier
- Software EngineeringHurtigere fejlfinding, mere præcis testgenerering, forbedret CI/CD-pipelineintegration.
- AI agenterMere pålidelige autonome arbejdsgange inden for marketing, finans og forskning.
- VirksomhedsintelligensForbedret opsummering, rapportgenerering og dybdegående analyser til datadrevet beslutningstagning.
Disse opgraderinger resulterer i reducerede udviklingsomkostninger og højere investeringsafkast for AI-drevne initiativer.
Hvad er det næste for Claude Opus?
Anthropic signalerer, at Opus 4.1 blot er ét skridt på en bredere køreplan. Holdet antyder "væsentligt større forbedringer" i kommende udgivelser, sandsynligvis med fokus på:
- Endnu længere kontekstvinduer (ud over 200 tokens).
- Multimodale muligheder til integreret forståelse af billede, lyd og kode.
- Stærkere fortolkningsevne Værktøjer til at spore beslutningsforløb under agenthandlinger.
Virksomheder og udviklere bør overvåge Anthropics kanaler for opdateringer, da hver trinvise opgradering styrker Claudes position blandt de mest dygtige og sikre AI-assistenter, der findes.
Kom godt i gang
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere.Claude Opus 4.1 er faktisk tilgængelig via CometAPI. CometAPI-lister anthropic/claude-opus-4.1 blandt dens understøttede modeller, så du kan dirigere anmodninger til den via CometAPI's API, er modellerne specifikt til markørkode også tilgængelige.
Til at begynde med, udforsk modellens muligheder i Legeplads og konsulter Claude Opus 4.1 for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen.
Basis URL: https://api.cometapi.com/v1/chat/completions
Modelparameter:
"claude-opus-4-1-20250805"→ standard Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 med udvidet ræsonnement aktiveretcometapi-opus-4-1-20250805→CometAPI eksklusivt. Standardversion specielt designet til markøren integrationcometapi-opus-4-1-20250805-thinking→ Eksklusivt til CometAPI. Udvidet ræsonnementversion specifikt til markøren integration
SammenfattendeClaude Opus 4.1 bygger videre på Opus 4.0's styrker ved at levere målrettede forbedringer inden for kodningsnøjagtighed, agentisk ræsonnement og infrastrukturydelse – uden at øge omkostningerne eller ændre integrationsveje. Uanset om du forfiner komplekse kodebaser, orkestrerer autonome agent-arbejdsgange eller genererer forretningsindsigt af høj kvalitet, tilbyder Opus 4.1 en overbevisende opgradering, der balancerer præcision og alsidighed. I takt med at AI-landskabet fortsætter med at accelerere, positionerer Anthropics stabile tempo af forbedringer Claude Opus som et oplagt valg for organisationer, der sigter mod at udnytte de førende sprogmodelfunktioner.