

De seneste par måneder har set en hurtig eskalering inden for agentisk kodning: specialiserede modeller, der ikke blot besvarer engangsforespørgsler, men som planlægger, redigerer, tester og itererer på tværs af hele repositories. To af de mest profilerede aktører er Komponere, en specialbygget kodningsmodel med lav latenstid, introduceret af Cursor med Cursor 2.0-udgivelsen, og GPT-5-Kodeks, OpenAIs agentoptimerede variant af GPT-5, der er tunet til vedvarende kodningsworkflows. Sammen illustrerer de de nye fejllinjer i udviklerværktøjer: hastighed vs. dybde, lokal arbejdsområdebevidsthed vs. generalistisk ræsonnement og "vibe-coding"-bekvemmelighed vs. teknisk stringens.
Overblik: direkte forskelle
- Designhensigt: GPT-5-Codex — dybdegående, agentisk ræsonnement og robusthed til lange, komplekse sessioner; Composer — hurtig, arbejdsområdebevidst iteration optimeret til hastighed.
- Primær integrationsoverflade: GPT-5-Codex — Codex-produkt/Responses API, IDE'er, virksomhedsintegrationer; Composer — Cursor-editor og Cursors brugergrænseflade til flere agenter.
- Latens/iteration: Composer lægger vægt på sving på under 30 sekunder og hævder store hastighedsfordele; GPT-5-Codex prioriterer grundighed og autonome kørsel over flere timer, hvor det er nødvendigt.
Jeg testede GPT-5-Codex API model leveret af CometAPI (en tredjeparts API-aggregeringsudbyder, hvis API-priser generelt er billigere end den officielle), opsummerede min erfaring med at bruge Cursor 2.0's Composer-model og sammenlignede de to i forskellige dimensioner af kodegenereringsvurdering.
Hvad er Composer og GPT-5-Codex
Hvad er GPT-5-Codex, og hvilke problemer sigter den mod at løse?
OpenAIs GPT-5-Codex er et specialiseret øjebliksbillede af GPT-5, som OpenAI angiver er optimeret til agentiske kodningsscenarier: kørsel af tests, udførelse af koderedigeringer på repository-skala og autonom iteration, indtil kontrollerne består. Fokus her er bred kapacitet på tværs af mange ingeniøropgaver - dybdegående ræsonnement for komplekse refaktoreringer, "agentisk" drift med længere horisont (hvor modellen kan bruge minutter til timer på at ræsonnere og teste) og stærkere ydeevne på standardiserede benchmarks designet til at afspejle virkelige ingeniørproblemer.
Hvad er Composer, og hvilke problemer sigter det mod at løse?
Composer er Cursors første native kodningsmodel, der blev lanceret med Cursor 2.0. Cursor beskriver Composer som en frontløbende, agentcentreret model bygget til lav latenstid og hurtig iteration i udvikler-workflows: planlægning af differences på flere filer, anvendelse af semantisk søgning på tværs af repository og gennemførelse af de fleste ture på under 30 sekunder. Den blev trænet med værktøjsadgang i løkken (søgning, redigering, test af værktøjer) for at være effektiv i praktiske ingeniøropgaver og for at minimere friktionen fra gentagne prompt-→-svar-cyklusser i den daglige kodning. Cursor positionerer Composer som en model, der er optimeret til udviklerhastighed og feedback-loops i realtid.
Modelomfang og runtime-adfærd
- Komponist: Optimeret til hurtige, editor-centrerede interaktioner og konsistens på tværs af flere filer. Cursors platformsniveauintegration gør det muligt for Composer at se mere af arkivet og deltage i multi-agent-orkestrering (f.eks. to Composer-agenter vs. andre), hvilket Cursor argumenterer for reducerer oversete afhængigheder på tværs af filer.
- GPT-5-kodex: optimeret til dybere ræsonnement med variabel længde. OpenAI reklamerer for modellens evne til at bytte beregning/tid til fordel for dybere ræsonnement, når det er nødvendigt – angiveligt lige fra sekunder til lette opgaver op til timer til omfattende autonome kørsler – hvilket muliggør mere grundige refaktoreringer og teststyret fejlfinding.
Kort version: Composer = Markørens indbyggede, arbejdsområdebevidste kodningsmodel; GPT-5-Codex = OpenAIs specialiserede GPT-5-variant til softwareudvikling, tilgængelig via Responses/Codex.
Hvordan er Composer og GPT-5-Codex sammenlignelige med hinanden i hastighed?
Hvad påstod sælgerne?
Cursor positionerer Composer som en "fast frontier"-koder: offentliggjorte tal fremhæver generationsgennemstrømning målt i tokens per sekund og påstande om 2-4 gange hurtigere interaktive færdiggørelsestider vs. "frontier"-modeller i Cursors interne udstyr. Uafhængig dækning (presse og tidlige testere) rapporterer, at Composer producerer kode med ~200-250 tokens/sek i Cursors miljø og i mange tilfælde gennemfører typiske interaktive kodningstrin på under 30 sekunder.
OpenAIs GPT-5-Codex er ikke positioneret som et latenstidseksperiment; det prioriterer robusthed og dybere ræsonnement, og kan – på sammenlignelige arbejdsbelastninger med høj ræsonnement – være langsommere, når det bruges i højere kontekststørrelser, ifølge fællesskabsrapporter og problemtråde.
Sådan målte vi hastighed (metode)
For at lave en fair hastighedssammenligning skal du kontrollere opgavetypen (korte færdiggørelser vs. lang ræsonnement), miljøet (netværkslatens, lokal vs. cloudintegration) og måle begge dele. tid til første nyttige resultat og vægur fra ende til ende (inklusive eventuelle testudførelses- eller kompileringstrin). Hovedpunkter:
- Valgte opgaver — generering af små kodestykker (implementering af et API-slutpunkt), mellemstor opgave (refaktorering af én fil og import af opdateringer), stor opgave (implementering af funktioner på tværs af tre filer, opdateringstests).
- Metrics — time-to-first-token, time-to-first-useful-diff (tid indtil kandidat-patch udsendes) og samlet tid inklusive testudførelse og verifikation.
- Gentagelser — hver opgave kører 10×, medianen bruges til at reducere netværksstøj.
- Miljø — målinger taget fra en udviklermaskine i Tokyo (for at afspejle den faktiske latenstid) med stabil 100/10 Mbps-forbindelse; resultaterne vil variere regionalt.
Nedenfor er en reproducerbar fartsele for GPT-5-Codex (Responses API) og en beskrivelse af, hvordan man måler Composer (inde i Cursor).
Hastighedsstyring (Node.js) — GPT-5-Codex (Responses API):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
Dette måler end-to-end-forespørgselsforsinkelse for GPT-5-Codex ved hjælp af den offentlige Responses API (OpenAI-dokumentation beskriver Responses API og brugen af gpt-5-codex-modellen).
Sådan måler du Composer-hastighed (markør):
Composer kører inde i Cursor 2.0 (desktop/VS Code fork). Cursor leverer (i skrivende stund) ikke en generel ekstern HTTP API til Composer, der matcher OpenAI's Responses API; Composers styrke er i-IDE, stateful arbejdsområdeintegrationDerfor skal du måle Composer, som en menneskelig udvikler ville gøre:
- Åbn det samme projekt i Cursor 2.0.
- Brug Composer til at køre den samme prompt som en agentopgave (opret rute, refaktorering, ændring af flere filer).
- Start et stopur, når du indsender Composer-planen; stop, når Composer udsender den atomare diff og kører testpakken (markørens brugerflade kan køre tests og vise en konsolideret diff).
- Gentag 10 gange og brug medianen.
Cursors publicerede materialer og praktiske anmeldelser viser, at Composer i praksis udfører mange almindelige opgaver på under ~30 sekunder; dette er et interaktivt latenstidsmål snarere end en rå modelinferenstid.
Tag væk: Composers designmål er hurtige interaktive redigeringer i en editor. Hvis din prioritet er konversationelle kodningsloops med lav latenstid, er Composer bygget til den anvendelse. GPT-5-Codex er optimeret til korrekthed og agentisk ræsonnement på tværs af længere sessioner. Den kan udveksle lidt mere latenstid med dybere planlægning. Leverandørtal understøtter denne positionering.
Hvordan er nøjagtigheden sammenlignet med Composer og GPT-5-Codex?
Hvad præcision betyder i kodning af AI
Nøjagtigheden her er mangesidet: funktionel korrekthed (kompilerer koden og består tests), semantisk korrekthed (opfylder adfærden specifikationen), og robusthed (håndterer edge-sager, sikkerhedsproblemer).
Leverandør- og pressenumre
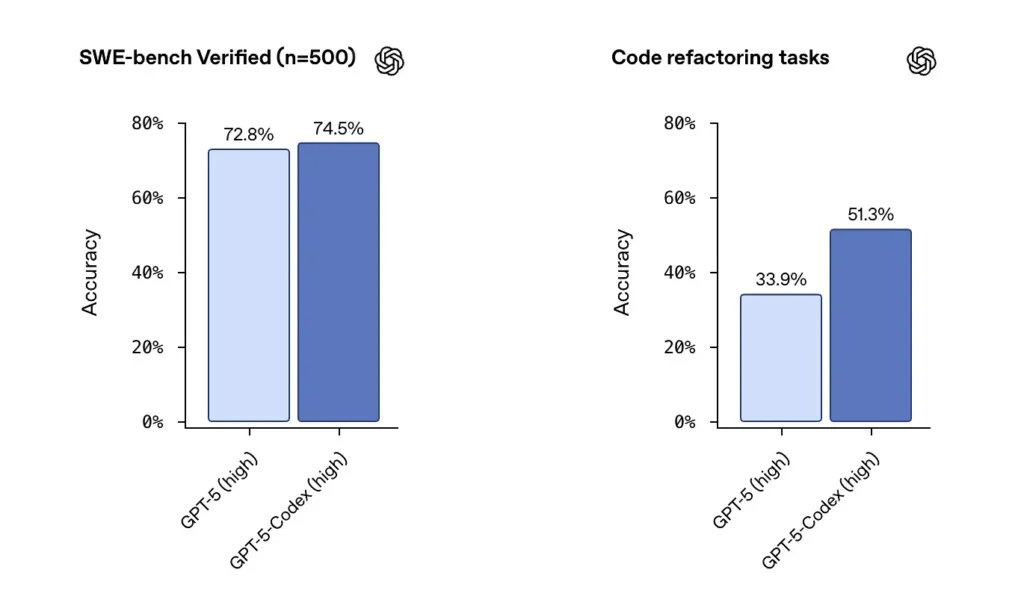
OpenAI rapporterer stærk GPT-5-Codex-ydeevne på SWE-bench-verificerede datasæt og fremhævede en 74.5% succesrate på et kodningsbenchmark i den virkelige verden (rapporteret i presseomtale) og en bemærkelsesværdig stigning i refactoring-succes (51.3 % vs. 33.9 for basis-GPT-5 på deres interne refactoring-test).
Cursors udgivelse indikerer, at Composer ofte udmærker sig ved kontekstfølsomme redigeringer af flere filer, hvor integration af editorer og synlighed af repositorier er vigtig. Efter at mine tests viste, at Composer producerede færre oversete afhængighedsfejl under refaktorering af flere filer og scorede højere på blinde tests for nogle arbejdsbelastninger med flere filer, hjælper Composers latenstid og parallelle agentfunktioner mig også med at forbedre iterationshastigheden.
Uafhængig nøjagtighedstestning (anbefalet metode)
En fair test bruger en blanding af:
- Enhedstest: fodr det samme repo og testsuite til begge modeller; generer kode, kør tests.
- Refaktoreringstests: angiv en bevidst rodet funktion og bed modellen om at refaktorere og tilføje tests.
- SikkerhedstjekKør statisk analyse og SAST-værktøjer på genereret kode (f.eks. Bandit, ESLint, semgrep).
- Menneskelig gennemgangKodegennemgangsscorer foretaget af erfarne ingeniører for vedligeholdelse og bedste praksis.
Eksempel: automatiseret testudstyr (Python) — kør genereret kode og enhedstests
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Brug dette mønster til automatisk at bekræfte, om modeloutputtet er funktionelt korrekt (består test). For refaktoreringsopgaver skal du køre harness'en mod det oprindelige repo plus modellens diff og sammenligne testbeståelsesrater og dækningsændringer.
Tag væk: På rå benchmark-suiter rapporterer GPT-5-Codex fremragende tal og stærk refactoring-evne. I virkelige arbejdsgange med reparation og redigering af flere filer kan Composers kendskab til arbejdsområdet give højere praktisk accept og færre "mekaniske" fejl (manglende import, forkerte filnavne). For maksimal funktionel korrekthed i algoritmiske opgaver med én fil er GPT-5-Codex en stærk kandidat; til konventionsfølsomme ændringer med flere filer i en IDE er Composer ofte fremragende.
Composer vs GPT-5: Hvordan klarer de sig i forhold til kodekvalitet?
Hvad tæller som kvalitet?
Kvalitet omfatter læsbarhed, navngivning, dokumentation, testdækning, brug af idiomatiske mønstre og sikkerhedshygiejne. Det måles både automatisk (linters, kompleksitetsmålinger) og kvalitativt (menneskelig gennemgang).
Observerede forskelle
- GPT-5-KodeksStærk til at producere idiomatiske mønstre, når de bliver bedt om det eksplicit; udmærker sig ved algoritmisk klarhed og kan producere omfattende testpakker, når de bliver bedt om det. OpenAIs Codex-værktøjer inkluderer integrerede test-/rapporterings- og udførelseslogfiler.
- Komponere: optimeret til automatisk at overholde et arkivs stil og konventioner; Composer kan følge eksisterende projektmønstre og koordinere opdateringer til flere filer (omdøbning/refaktorering af udbredelse, import af opdateringer). Det tilbyder fremragende vedligeholdelse efter behov til store projekter.
Eksempler på kodekvalitetstjek, du kan køre
- Linters — ESLint / pylint
- Kompleksitet — radon / flake8-kompleksitet
- Sikkerhed — semgrep / Bandit
- Testdækning — kør coverage.py eller vitest/nyc for JS
Automatiser disse kontroller efter at have anvendt modellens programrettelse for at kvantificere forbedringer eller regressioner. Eksempel på kommandosekvens (JS-repo):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Menneskelig gennemgang og bedste praksis
I praksis kræver modeller instruktioner for at følge bedste praksis: bed om docstrings, typeannotationer, afhængighedsfastgørelse eller specifikke mønstre (f.eks. async/await). GPT-5-Codex er fremragende, når den får eksplicitte direktiver; Composer drager fordel af den implicitte repository-kontekst. Brug en kombineret tilgang: instruer modellen eksplicit, og lad Composer håndhæve projektstil, hvis du er inde i Cursor.
Anbefaling: Til flerfils engineering-arbejde i et IDE foretrækkes Composer; til eksterne pipelines, forskningsopgaver eller værktøjskædeautomatisering, hvor du kan kalde et API og levere omfattende kontekst, er GPT-5-Codex et stærkt valg.
Integrationer og implementeringsmuligheder
Composer leveres som en del af Cursor 2.0, integreret i Cursor-editoren og brugergrænsefladen. Cursors tilgang lægger vægt på et enkelt leverandørkontrolplan, der kører Composer sammen med andre modeller - hvilket giver brugerne mulighed for at køre flere modelinstanser på den samme prompt og sammenligne output i editoren. ()
GPT-5-Codex bliver integreret i OpenAIs Codex-tilbud og ChatGPT-produktfamilie, med tilgængelighed via ChatGPT-betalte niveauer og API'er, som tredjepartsplatforme som CometAPI tilbyder bedre valuta for pengene. OpenAI integrerer også Codex i udviklerværktøjer og cloud-partnerarbejdsgange (f.eks. Visual Studio Code/GitHub Copilot-integrationer).
Hvor kan Composer og GPT-5-Codex skubbe branchen næste gang?
Kortsigtede effekter
- Hurtigere iterationscyklusser: Editor-embedded modeller som Composer reducerer friktion ved små rettelser og PR-generering.
- Stigende forventninger til verifikation: Codex' fokus på test, logs og autonom kapacitet vil presse leverandører til at levere stærkere verifikation fra starten af for modelproduceret kode.
Mellemlang til lang sigt
- Multimodelorkestrering bliver normal: Cursors multi-agent GUI er et tidligt hint om, at ingeniører snart vil forvente at køre flere specialiserede agenter parallelt (linting, sikkerhed, refactoring, ydeevneoptimering) og acceptere de bedste output.
- Strammere CI/AI-feedbackloops: Efterhånden som modellerne forbedres, vil CI-pipelines i stigende grad inkorporere modeldrevet testgenerering og automatiserede reparationsforslag – men menneskelig gennemgang og trinvis udrulning er fortsat afgørende.
Konklusion
Composer og GPT-5-Codex er ikke identiske våben i det samme våbenkapløb; de er komplementære værktøjer, der er optimeret til forskellige dele af softwarens livscyklus. Composers værdiforslag er hastighed: hurtig, arbejdsområdebaseret iteration, der holder udviklerne i flow. GPT-5-Codex' værdi er dybde: agentisk vedholdenhed, testdrevet korrekthed og auditerbarhed til tunge transformationer. Den pragmatiske ingeniørhåndbog er at... orkestrere begge: Composer-lignende agenter med korte loops til daglige flow og GPT-5-Codex-lignende agenter til gated-operationer med høj sikkerhed. Tidlige benchmarks tyder på, at begge vil være en del af udviklerværktøjssættet på kort sigt snarere end at den ene erstatter den anden.
Der er ingen enkelt objektiv vinder på tværs af alle dimensioner. Modellerne udveksler styrker:
- GPT-5-kodex: stærkere på dybdegående korrekthedsbenchmarks, omfattende ræsonnement og autonome arbejdsgange over flere timer. Den er fremragende, når opgavekompleksitet kræver lang ræsonnement eller omfattende verifikation.
- Komponist: stærkere i tætte editor-integrerede use cases, konsistens i flere filers kontekst og hurtig iterationshastighed i Cursors miljø. Det kan være bedre for udviklernes daglige produktivitet, hvor der er behov for øjeblikkelige, præcise kontekstbevidste redigeringer.
Se også Cursor 2.0 og Composer: hvordan en multiagent gentænker overrasket AI-kodning
Kom godt i gang
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere – såsom OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i en enkelt, udviklervenlig grænseflade. Ved at tilbyde ensartet godkendelse, formatering af anmodninger og svarhåndtering forenkler CometAPI dramatisk integrationen af AI-funktioner i dine applikationer. Uanset om du bygger chatbots, billedgeneratorer, musikkomponister eller datadrevne analysepipelines, giver CometAPI dig mulighed for at iterere hurtigere, kontrollere omkostninger og forblive leverandøruafhængig – alt imens du udnytter de seneste gennembrud på tværs af AI-økosystemet.
Udviklere kan få adgang GPT-5-Codex APIgennem Comet API, den nyeste modelversion opdateres altid med den officielle hjemmeside. For at begynde, udforsk modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!