
Gemini 2.5 Flash API er Googles nyeste multimodale AI-model, designet til hurtige, omkostningseffektive opgaver med kontrollerbare ræsonnementfunktioner, der giver udviklere mulighed for at slå avancerede "tænkningsfunktioner" til eller fra via Gemini API'en. Seneste modeller er gemini-2.5-flash.
Oversigt over Gemini 2.5 Flash
Gemini 2.5 Flash er udviklet til at levere hurtige svar uden at gå på kompromis med kvaliteten af output. Den understøtter multimodale input, herunder tekst, billeder, lyd og video, hvilket gør den velegnet til forskellige applikationer. Modellen er tilgængelig via platforme som Google AI Studio og Vertex AI, der giver udviklere de nødvendige værktøjer til problemfri integration i forskellige systemer.
Grundlæggende oplysninger (funktioner)
Gemini 2.5 Flash introducerer flere fremragende funktioner funktioner der adskiller den inden for Gemini 2.5-familien:
- Hybrid ræsonnementUdviklere kan indstille en tænker_budget parameter til at finjustere, hvor mange tokens modellen dedikerer til intern ræsonnement før output.
- Pareto-grænsenPlaceret ved optimalt omkostnings-ydelsespunktFlash tilbyder det bedste forhold mellem pris og intelligens blandt 2.5-modeller.
- Multimodal support: Processer tekst, billeder, videoog lyd native, hvilket muliggør rigere samtale- og analytiske evner.
- Kontekst med 1 million tokensUovertruffen kontekstlængde muliggør dybdegående analyse og forståelse af lange dokumenter i en enkelt anmodning.
Modelversionering
Gemini 2.5 Flash har gennemgået følgende nøgle versioner:
- gemini-2.5-flash-lite-preview-09-2025: Forbedret værktøjsbrugervenlighed: Forbedret ydeevne på komplekse opgaver med flere trin med en stigning på 5 % i SWE-Bench Verified-scorer (fra 48.9 % til 54 %). Forbedret effektivitet: Når ræsonnement aktiveres, opnås output af højere kvalitet med færre tokens, hvilket reducerer latenstid og omkostninger.
- Forhåndsvisning 04-17Tidlig adgangsudgivelse med "tænkefunktion", tilgængelig via gemini-2.5-flash-preview-04-17.
- **Stabil generel tilgængelighed (GA)**Fra den 17. juni 2025, det stabile slutpunkt gemini-2.5-flash erstatter forhåndsvisningen og sikrer pålidelighed i produktionsklassen uden API-ændringer fra forhåndsvisningen den 20. maj.
- Udfasning af forhåndsvisningForhåndsvisningsslutpunkterne var planlagt til nedlukning den 15. juli 2025; brugere skal migrere til GA-slutpunktet inden denne dato.
Fra juli 2025 er Gemini 2.5 Flash nu offentligt tilgængelig og stabil (ingen ændringer fra gemini-2.5-flash-preview-05-20 Hvis du bruger gemini-2.5-flash-preview-04-17, vil den eksisterende forhåndsvisningspris fortsætte indtil den planlagte udfasning af modelslutpunktet den 15. juli 2025, hvor det lukkes ned. Du kan migrere til den generelt tilgængelige model "gemini-2.5-flash".
Hurtigere, billigere, smartere:
- Designmål: lav latenstid + høj gennemløbshastighed + lave omkostninger;
- Samlet hastighedsforøgelse i ræsonnement, multimodal behandling og opgaver med lange tekster;
- Brugen af tokens reduceres med 20-30%, hvilket reducerer omkostningerne til ræsonnement betydeligt.
Tekniske specifikationer
Inputkontekstvindue: Op til 1 million tokens, hvilket giver mulighed for omfattende kontekstbevaring.
Output-tokens: Kan generere op til 8,192 tokens pr. svar.
Understøttede modaliteter: Tekst, billeder, lyd og video.
Integrationsplatforme: Tilgængelig via Google AI Studio og Vertex AI.
Prissætning: Konkurrencedygtig tokenbaseret prismodel, der letter omkostningseffektiv implementering.
Tekniske detaljer
Under motorhjelmen er Gemini 2.5 Flash en transformer-baseret Stor sprogmodel trænet på en blanding af web-, kode-, billed- og videodata. Nøgle teknisk specifikationerne omfatter:
Multimodal træningFlash er trænet til at justere flere modaliteter og kan problemfrit blande tekst med billeder, video eller lyd, nyttigt til opgaver som videoopsummeringer eller lydtekster.
Dynamisk tænkningsprocesImplementerer en intern ræsonnementsløjfe, hvor modellen planer og opdeler komplekse prompts før det endelige output.
Konfigurerbare tænkningsbudgetter: The tænker_budget kan indstilles fra 0 (ingen begrundelse) op til 24,576-symboler, hvilket muliggør afvejninger mellem latenstid og svarkvalitet.
Værktøjsintegration: Bakker op Jordforbindelse med Google-søgning, Kodeudførelse, URL-kontekstog Funktionsopkald, hvilket muliggør handlinger i den virkelige verden direkte fra naturlige sprogprompter.
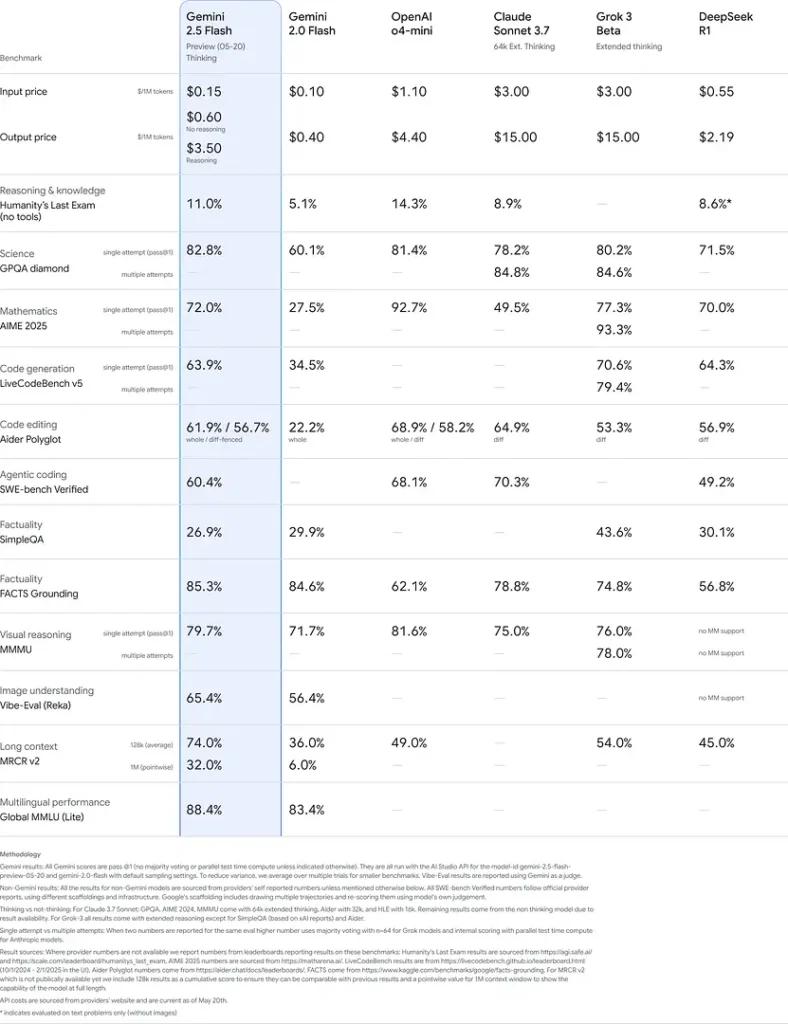
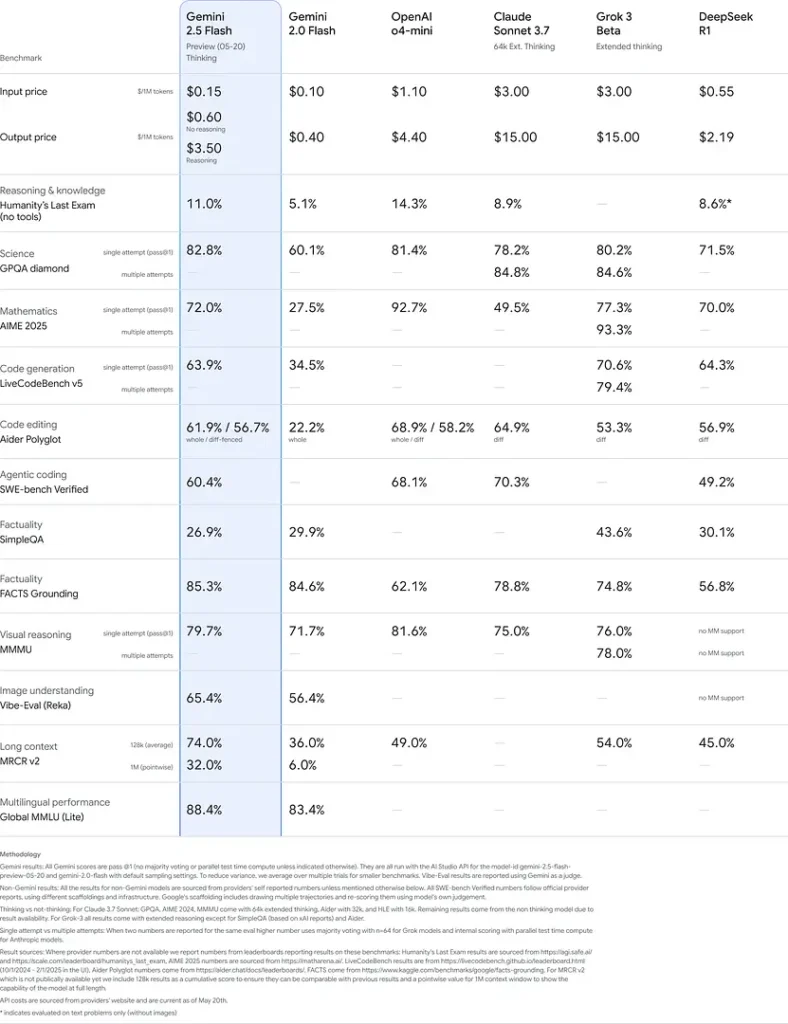
Benchmark ydeevne
I grundige evalueringer demonstrerer Gemini 2.5 Flash brancheførende ydeevne:
- LMArena hårde prompts: Scoret kun overgået af 2.5 Pro på den udfordrende Hard Prompts-benchmark, der viser stærke evner til ræsonnement i flere trin.
- MMLU-score på 0.809Overgår den gennemsnitlige modelydelse med en 0.809 MMLU-nøjagtighed, som afspejler dens brede domæneviden og ræsonnementsevne.
- Latency og Gennemløb: Opnår 271.4 tokens/sek. afkodningshastighed med en 0.29 s Tid til første token, hvilket gør den ideel til latenstidsfølsomme arbejdsbelastninger.
- Førende inden for pris-til-ydelse: Kl $0.26/1 mio. tokensFlash underbyder mange konkurrenter, mens den matcher eller overgår dem på vigtige benchmarks.
Disse resultater viser Gemini 2.5 Flashs konkurrencefordel inden for ræsonnement, videnskabelig forståelse, matematisk problemløsning, kodning, visuel fortolkning og flersprogede evner:
Begrænsninger
Selvom den er kraftfuld, bærer Gemini 2.5 Flash visse begrænsninger:
- SikkerhedsrisiciModellen kan udvise en "prædikende" tone og kan producere plausible, men ukorrekte eller forudindtagede resultater (hallucinationer), især ved edge-case-forespørgsler. Strenge menneskeligt tilsyn er fortsat afgørende.
- SatsgrænserAPI-brug er begrænset af hastighedsgrænser (10 RPM, 250,000 TPM, 250 RPD på standardniveauer), hvilket kan påvirke batchbehandling eller applikationer med stor volumen.
- Intelligence FloorSelvom den er exceptionelt kapabel til en blitz model, forbliver den mindre nøjagtig end 2.5 Pro på de mest krævende agentopgaver som avanceret kodning eller koordinering mellem flere agenter.
- OmkostningsafvejningerSelvom de tilbyder det bedste pris-ydelse, udstrakt brug af tænker Tilstanden øger det samlede tokenforbrug, hvilket øger omkostningerne ved dybtgående ræsonnementsopgaver.
Se også Gemini 2.5 Pro API
Konklusion
Gemini 2.5 Flash står som et vidnesbyrd om Googles forpligtelse til at fremme AI-teknologier. Med sin robuste ydeevne, multimodale muligheder og effektive ressourcestyring tilbyder den en omfattende løsning til udviklere og organisationer, der søger at udnytte kraften fra kunstig intelligens i deres operationer.
Sådan ringer du Gemini 2.5 Flash API fra CometAPI
Gemini 2.5 Flash API-priser i CometAPI, 20 % rabat på den officielle pris:
- Input-tokens: $0.24 / M-tokens
- Output-tokens: $0.96/M-tokens
Påkrævede trin
- Log ind på cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først
- Få adgangslegitimations-API-nøglen til grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.
- Hent url'en til dette websted: https://api.cometapi.com/
Brugsmetoder
- Vælg "
gemini-2.5-flash” endepunkt for at sende API-anmodningen og indstille anmodningsteksten. Forespørgselsmetoden og anmodningsteksten er hentet fra vores websteds API-dokument. Vores websted tilbyder også Apifox-test for din bekvemmelighed. - Erstatte med din egentlige CometAPI-nøgle fra din konto.
- Indsæt dit spørgsmål eller din anmodning i indholdsfeltet – det er det, modellen vil reagere på.
- . Behandle API-svaret for at få det genererede svar.
For model frokost information i Comet API, se venligst https://api.cometapi.com/new-model.
For modelprisoplysninger i Comet API, se venligst https://api.cometapi.com/pricing.
Eksempel på API-brug
Udviklere kan interagere med gemini-2.5-flash gennem CometAPI's API, hvilket muliggør integration i forskellige applikationer. Nedenfor er et Python-eksempel:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Dette script sender en prompt til Gemini 2.5 Flash model og udskriver det genererede svar, og demonstrerer, hvordan man bruger det Gemini 2.5 Flash til komplekse forklaringer.