

Google og deres forskningsarm DeepMind har stille (og senere ikke så stille) skubbet endnu et stort skridt i Gemini-roadmappen: Gemini 3.1 Pro. Udgivelsen, udrullet på forbrugerrettede flader, CometAPI, er positioneret som en opgradering af ydeevne og ræsonnering til Gemini 3-familien — med løfter om markant stærkere langformet ræsonnering, forbedret multimodal forståelse og bedre skalerbarhed til virkelige anvendelser.
Googles nyeste model — hvad er Gemini 3.1 Pro?
Gemini 3.1 Pro er den første inkrementelle opdatering i Gemini 3-familien, positioneret som en “mest kapabel” ræsonneringsmodel optimeret til flertrins-, multimodale og agentiske opgaver. Modellen blev frigivet i offentlig preview i midten af februar 2026 (preview annonceret 19.–20. feb. 2026) og er eksplicit målrettet scenarier, der kræver vedvarende tankekæder, værktøjsanvendelse og forståelse af lange kontekster — for eksempel: storskala researchsyntese, ingeniøragenter der koordinerer værktøjer og systemer, samt multimodal analyse af dokumenter, der blander tekst, billeder, lyd og video.
På et overordnet niveau beskrives Gemini 3.1 Pro af udviklerne som:
- Nativt multimodal — i stand til at modtage og ræsonnere over tekst, billeder, lyd og video.
- Bygget til lang kontekst — understøtter meget store kontekstvinduer, velegnet til hele kodebaser, multi-dokument-dossierer eller lange transskripter.
- Optimeret til pålidelig ræsonnering og agentiske arbejdsgange, hvilket betyder, at den er tunet til at planlægge, kalde værktøjer og verificere output på tværs af flertrinsopgaver.
Hvorfor det er vigtigt nu: Organisationer og udviklere bevæger sig fra “gode samtaleassistenter” til “højrisiko beslutningsstøtte- og forskningsagenter” (juridisk udarbejdelse, R&D-syntese, multimodal dokumentforståelse). Gemini 3.1 Pro er eksplicit designet til dette felt — for at reducere hallucinationer, producere sporbar ræsonnering og integrere med CometAPI til både prototyper og produktion.
Hvad er de tekniske højdepunkter og funktioner i Gemini 3.1 Pro?
Nativ multimodalitet og ekstreme kontekstvinduer
Gemini 3.1 Pro fortsætter Gemini-arvens fokus på multimodalitet. Ifølge modelkortet og produktnoterne accepterer modellen og ræsonnerer over tekst, billeder, lyd og video i den samme pipeline — en evne, der forenkler arbejdsgange, hvor datatyper blandes (f.eks. juridiske afhøringer med lyd + transskript + scanninger). Bemærkelsesværdigt er, at modellen understøtter et 1,000,000-token kontekstvindue og kan producere lange output (offentliggjorte noter angiver outputgrænser i meget store størrelser, passende til langformede opgaver). Denne skala gør den velegnet til brugsscenarier som at analysere hele koderepositorier, multikapitel-dokumenter eller lange transskripter uden chunking.
“Dynamisk tænkning”: forbedret ræsonnering og trinvis planlægning
Google beskriver 3.1 Pro som havende forbedret “tænkning” — dvs. bedre intern håndtering af tankekæder og dynamisk valg af ræsonneringsstrategier afhængigt af opgavens kompleksitet. Modellen er tunet til at engagere sig i eksplicit flertrinsplanlægning, når det er nødvendigt, og være token-effektiv imens. I praksis betyder det færre hallucinationer for komplekse, trinvise problemer og forbedret faktuel konsistens på flertrins-ræsonneringsbenchmarks.
Agentiske arbejdsgange og værktøjsbrug
Et stort designfokus for 3.1 Pro er agentisk performance: koordinere værktøjer, anvende web-grounding eller søgning, skrive og køre kodeuddrag samt verificere output gennem sekundære gennemløb. Google har integreret 3.1 Pro i agent-first-produkter (f.eks. udviklingsmiljøet Antigravity) for at lade modeller udføre opgaver, der involverer en editor, terminal og browser — og registrere artefakter som skærmbilleder og browseroptagelser for at verificere fremdrift. Disse funktioner sigter mod at mindske kløften mellem “rådgivende” modeller og modeller, der faktisk udfører multi-værktøjs-arbejdsgange pålideligt.
Specialiserede undermodes (Deep Research, Deep Think)
Google parrer 3.1 Pro med “Deep Research” og henviser til en kommende “Deep Think”-variant. Disse undermodes er målrettet henholdsvis researchopgaver med høj recall og maksimal ræsonneringsdybde (mod ekstra beregningsomkostning og latenstid). De er tænkt til analytikere, forskere og udviklere, der har brug for mere gennemarbejdede output af højere kvalitet frem for de hurtigste, billigste svar.
Hvordan performer Gemini 3.1 Pro på benchmarks?
Gemini 3.1 Pro opnår markante forbedringer over tidligere Gemini 3 Pro-resultater og tager ofte føringen på et bredt sæt flertrins-ræsonnerings- og multimodale målinger — men halter efter nogle konkurrenter på specifikke specialiserede opgaver (især visse avancerede kodnings- eller ekspertspørgsmålssuiter). Kort sagt: brede forbedringer med smalle forspring for konkurrenter i specialbenchmarks.
Vigtige benchmark-påstande og hovedtal
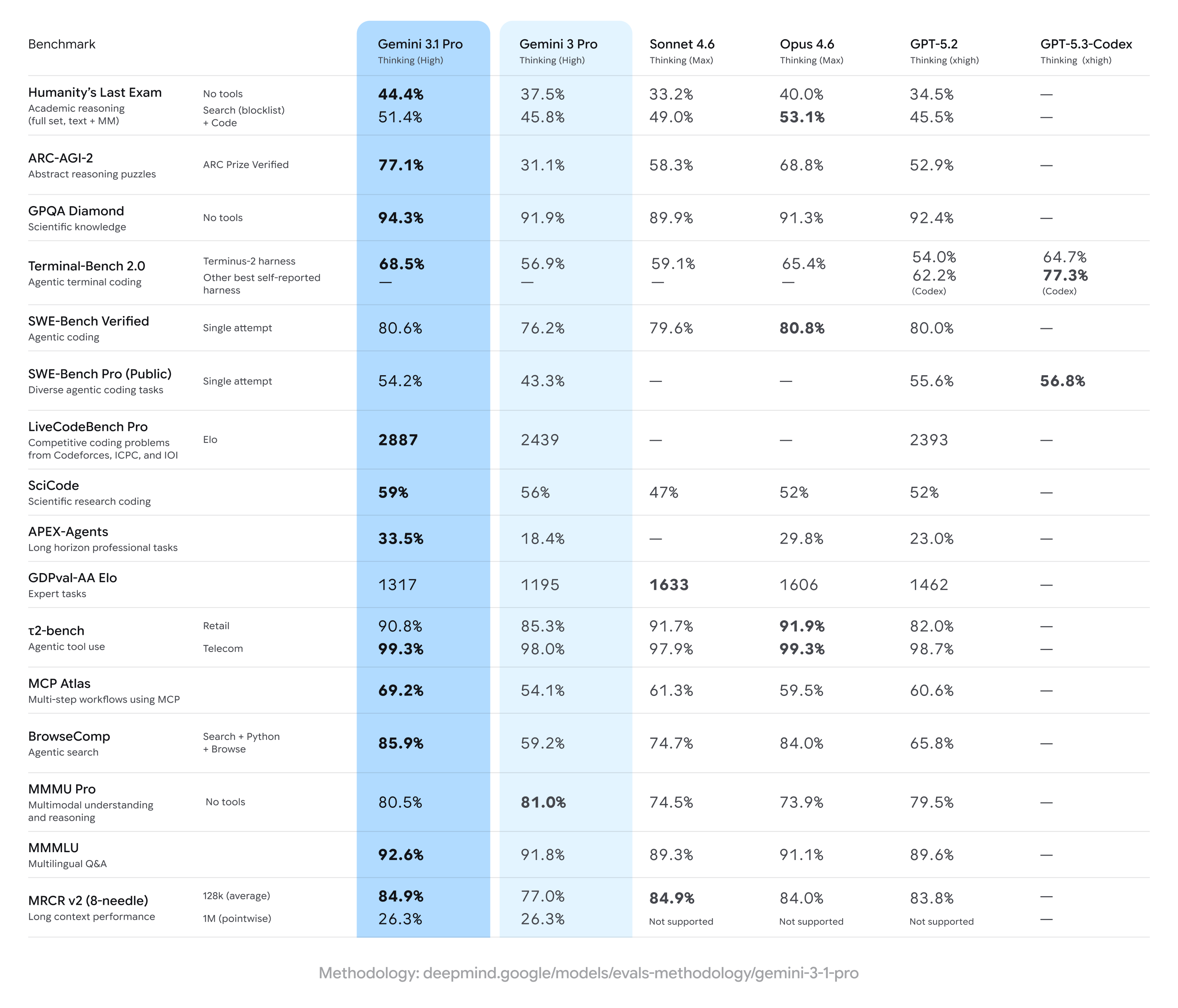
- ARC-AGI-2 (abstrakt ræsonnering / flertrins videnskabelige gåder): Rapporterede stigninger for Gemini 3.1 Pro viser en substantiel forbedring fra tidligere Gemini 3 Pro-versioner; ét community-testsæt indikerede mere end en fordobling på ARC-AGI-2 vs. den tidligere Gemini 3 Pro-baseline i korte, fokuserede tests. Specifikke rapporterede scorer (community-tests) placerer Gemini 3.1 Pro omkring ~77.1% på nogle ARC-stil-aggregeringer (offentlig rapportering).
- GPQA Diamond og benchmarks på kandidatniveau i naturvidenskab: Data rapporterer, at Gemini 3.1 Pro nåede rekordhøje niveauer på GPQA Diamond (et kandidatniveau-videnskabs-QA-benchmark), overgik tidligere Gemini-modeller og satte en ny høj vandmærke for familien i uafhængige kørsler. Disse gevinster afspejler modellens forbedrede chain-of-thought og tuning til trinvis ræsonnering.
- “Humanity’s Last Exam” med værktøjer aktiveret (multi-tool, forankret ræsonnering): I direkte sammenligninger med Anthropics Claude Opus 4.6 opnåede Claude 53.1% på dette komplekse værktøjsaktiverede benchmark, mens Gemini 3.1 Pro nåede 51.4% i samme testrunde — hvilket viser Gemini lige efter, men ikke helt på toppen på netop denne multi-tool-eksamen.
- Kodnings- og terminalbenchmarks (Terminal-Bench 2.0, SWE-Bench Pro): Specialiserede kodningsbenchmarks viste større divergens. På Terminal-Bench 2.0 med specifikke testrammer scorede GPT-5.3-Codex-varianter omkring 77.3% mod Gemini 3.1 Pros ~68.5% i de samme sammenligninger. På SWE-Bench Pro, offentligt rapporterede resultater, scorede Gemini 3.1 Pro ~54.2% mod GPT-5.3-Codex’ 56.8% — tættere, men med OpenAIs Codex-familie, der holder en fordel på specialiserede programmeringsopgaver i de pågældende kørsler.
- GDPval-AA Elo (ekspertopgave-rating): I en Elo-stil aggregeret rangering for ekspertopgaver scorede Claude Sonnet/Opus-varianter højere (f.eks. ~1606–1633 point), mens én offentlig rapport placerede Gemini 3.1 Pro på ~1317 point i det samme datasæt — hvilket indikerer plads til forbedring på visse snævre ekspertdomæner.
Resultater fra virkelige forsøg og hands-on-tests
Hands-on-analytikerrapporter viser, at Gemini 3.1 Pro især excellerer i:
- Sammenfatning med lang kontekst og multi-dokument-syntese, hvor 1M-token-vinduet undgår artefaktpræget chunking.
- Multimodale forståelsesopgaver, hvor billede + tekst-grounding forbedrer faktuel udtrækning.
- Agentisk automatisering (f.eks. koordinering af simple værktøjskæder) — med Antigravity-forsøg, der demonstrerer, at multi-agent-opgaveorkestrering er mulig med artefakter, der registrerer hvert trin.
Hvor Gemini 3.1 Pro stadig halter (hvad tallene siger)
Ingen model er ensartet bedst. Uafhængige kommentarer og community-tests fremhæver specifikke huller:
- Software engineering- og kodevedligeholdelses-benchmarks (SWE-Bench Pro og lignende) — Gemini 3.1 Pro ligger efter en konkurrent (Anthropics Claude Opus 4.6) på opgaver, der tester praktiske software engineering-evner: storskala refaktoreringer, bug-triage i rodede kodebaser og nogle typer automatiseret programreparation. Med andre ord, til daglig vedligeholdelse i engineering fastholder specialiserede modeller stadig en fordel i visse testmiljøer.
- Latenstfølsomme mikroopgaver — fordi Gemini 3.1 Pro er tunet til dybde, kan opgaver, der kræver ultralav latenstid og høj gennemstrømning (f.eks. mikroinference til letvægts-samtale-UI’er), være bedre tjent med “Flash” eller andre optimerede varianter i Gemini-familien.
Hvad er prisen for Gemini 3.1 Pro?
du kan få adgang til Gemini 3.1 Pro på to måder — forbrugerabonnement eller udvikler-API — og prisen er forskellig for hver.
- Forbruger (Gemini-app / Google AI Pro): Adgang til Gemini 3.1 Pro er inkluderet i Google AI Pro-abonnementet, som i USA er $19.99 / month (Google tilbyder også det lavere “AI Plus” og et højere “AI Ultra”-niveau). Google.
- Udvikler / API (token-baseret): Hvis du kalder Gemini-modellerne via Gemini/AI-udvikler-API’et, afregnes prisen pr. token. For Gemini 3.x Pro-preview er de offentliggjorte udviklerpriser omtrent: $2.00 per 1M input tokens og $12.00 per 1M output tokens for standardbåndet (≤200k prompts) — med højere niveauer (f.eks. $4/$18 per 1M) for meget store kontekster. (Se Gemini API-pristabellen for alle detaljer og batchpriser.)
- Hvis du bruger Gemini 3.1 Pro via CometAPI:
| Comet-pris (USD / M tokens) | Officiel pris (USD / M tokens) |
|---|---|
| Inddata:$1.6/M; Uddata:$9.6/M | Inddata:$2/M; Uddata:$12/M |
Forbrugerabonnementspriser (Gemini-app)
For slutbrugerplaner i Gemini-appen strukturerer Google niveauer, der giver adgang til modelvarianter og ekstra funktioner: Google AI Pro og Google AI Ultra. Priser varierer efter marked og valuta; offentliggjorte eksempler viser Google AI Pro til $19.99/month (med kampagneprøver tilgængelige), og niveaubestemt valuta-prissætning vises på produktsiden (inklusive prøveperioder og kortvarigt reducerede satser). AI Ultra samler højere adgang (f.eks. prioriteret adgang til nye innovationer, højere kreditter til videogenerering) til en højere månedlig pris. Disse forbrugerplanpriser er konkurrencedygtige med andre high-end forbruger-AI-abonnementer og er positioneret til at give individuelle power users eller små teams adgang til 3.1 Pro-funktioner uden API-integration.
Praktiske prompt- og brugstips (hvad jeg ville gøre)
Brug disse for at få pålidelige, reproducerbare resultater:
- Eksplicit trinplanlægger
Prompt pattern:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Dette udnytter 3.1 Pros stærkere trinvise eksekvering og giver dig kontrolpunkter. - Struktureret output med skemaer
Bed om JSON med et skema ogstrict: true. Fordi 3.1 Pro producerer lange, skema-efterlevende output mere pålideligt, får du større enkeltresponser, som du kan parse nedstrøms. - Værktøjstjek-sandwich
Når du kalder eksterne værktøjer (API’er, koderunnere), lad modellen producere: plan → præcist værktøjskald (copy/paste-venlig) → valideringstrin. Bekræft derefter valideringstrinene uden for modellen, før du fortsætter. - Pas på tillid til enkelttrin
Selv hvis modellen skriver perfekt udseende kode eller kommandoer, skal du køre uafhængig validering (tests, linters, sandkassekørsel) — især for agentiske/autonome handlinger.
Hands-on med Gemini 3.1 Pro
Prøvecase 1: Langkontekst-forskningsassistent (NotebookLM / Deep Research)
Mål: Evaluér modellens evne til at syntetisere 10–50 lange dokumenter (f.eks. rapporter, whitepapers) til et flersidet lederresumé med citater og handlingspunkter.
Opsætning: Giv et korpus på i alt 200k–800k tokens; bed modellen producere et 2–4 siders resumé med eksplicitte citater og “næste skridt”-anbefalinger. Brug en gentagelig promptskabelon, og mål tid, tokenforbrug (omkostning) og faktuel nøjagtighed.
Resultater: Hurtigere end-to-end-sammenfatning med færre chunking-artefakter i forhold til ældre modeller, højere citationsfidelitet i resuméet og forbedret sammenhæng i stor skala — med den omkostning, at tokenforbruget er betydeligt (så planlæg budgettet). Benchmarks og hands-on-tests viser, at Gemini 3.1 Pro excellerer i multi-dokument-syntese på grund af 1M-token-vinduet.
Prøvecase 2: Agentisk kodeassistent (Antigravity + GitHub Copilot)
Mål: Mål reduktion i tid-til-færdig for flertrins udvikleropgaver (f.eks. implementer en funktion på tværs af flere filer, kør tests, ret fejlede tests).
Opsætning: Brug Antigravity eller GitHub Copilot i preview med Gemini 3.1 Pro valgt. Definér reproducerbare opgaver (issue-oprettelse → implementering → kør tests), log trin og agentartefakter, og sammenlign med en menneske-only baseline.
Resultater: Forbedret orkestrering af flertrinsopgaver (artefaktregistrering, automatisk forslag til patch-kandidater), bedre flerfil-ræsonnering end tidligere Gemini 3 Pro og målbare tidsbesparelser på rutinepræget funktionsarbejde. Specialiserede low-level systemfejlsøgningsopgaver kan stadig favorisere specialiserede code-first-modeller (community-resultater viser et gab i forhold til nogle GPT-Codex-varianter på visse terminalbenchmarks).
Prøvecase 3: Multimodal juridisk/medicinsk dokumentgennemgang
Mål: Brug modellen til at indlæse et blandet korpus (scannede PDF’er, billeder, lydtransskripter), udtrække nøgelfakta og producere en risikomatrix og prioriterede handlinger.
Opsætning: Lever et datasæt med scannede billeder og OCR-tekst samt understøttende lyd. Mål præcision i udtræk af navngivne entiteter, falsk-positiv-rate og modellens evne til at referere kildeartefakter.
resultater: Stærkere integreret ræsonnering på tværs af modaliteter og mere sporbare output (evne til at pege på det billede/den side/det lydtidsstempel, der understøtter en påstand). Det lange kontekstvindue reducerer behovet for manuel chunking og krydsreferencer. I regulerede domæner bør output dog valideres af domæneeksperter, og en grounding-/verifikationspipeline bør anvendes.
Første indtryk (hvad føles anderledes)
- Dybere trinvis ræsonnering. Opgaver, der tidligere krævede flere frem-og-tilbage — f.eks. multi-dokument-syntese, flertrins matematik/logik — tenderer til at blive fuldført i færre omgange og med tydeligere chain-of-thought-stil-output (uden at afsløre intern instruktionstekst). Dette er det hovedbudskab, Google fremhævede.
- Længere, strukturerede output af højere kvalitet. JSON og langform-automatiseringer er mere konsistente og ofte meget længere (nogle brugere rapporterede outputstørrelser langt større end 3.0). Det gør den stærk til generatorjobs, hvor du ønsker en enkelt, stor payload. Forvent at håndtere større output og streaming.
- Mere effektiv token-/kontekst-håndtering. Forbedret tokeneffektivitet og en mere “forankret, faktuelt konsistent” adfærd i værktøjsbrugsscenarier. Det ses i færre hallucinationer ved korte faktuelle opslag.
Endelig analyse: Er Gemini 3.1 Pro værd at adoptere nu?
Gemini 3.1 Pro repræsenterer et meningsfuldt fremskridt i Gemini-familien med demonstrerbare forbedringer på ræsonnerings-, kodnings- og agentiske benchmarks — understøttet af Googles offentliggjorte modelkort og uafhængige trackere, der citerer store spring på udvalgte ranglister. For teams, der har brug for avanceret ræsonnering, agentisk værktøjskoordination eller langkontekst-multimodale kapaciteter, er 3.1 Pro en overbevisende kandidat.
Udviklere kan få adgang til Gemini 3.1 Pro via CometAPI nu. For at komme i gang skal du udforske modellens kapaciteter i Playground og konsultere API-vejledningen for detaljerede instruktioner. Før adgang, skal du sikre dig, at du er logget ind på CometAPI og har fået en API-nøgle. CometAPI tilbyder en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at komme i gang?→ Tilmeld dig Gemini 3.1 Pro i dag !
Hvis du vil have flere tips, vejledninger og nyheder om AI, så følg os på VK, X og Discord!