

Begge Gemini 3 Pro (Google/DeepMind) og Claude Sonnet 4.5 (Anthropic) er 2025-æraens flagskibsmodeller optimeret til agentiske, langhorisontede, værktøjsbrugende arbejdsgange — og begge lægger stor vægt på kodning. De påståede styrker divergerer: Google præsenterer Gemini 3 Pro som en generel multimodal ræsonnør, der også excellerer i agentisk kodning, mens Anthropic positionerer Sonnet 4.5 som verdens bedste coding/agent-model med særligt stærk succes for redigering/værktøjsbrug og langtidsholdbare agenter.
Kort svar først: begge modeller er i absolut topklasse til softwareengineering-opgaver i slutningen af 2025. Claude Sonnet 4.5 ligger et mulehår foran på nogle rene softwareengineering-benchmarks, mens Google’s Gemini 3 Pro (Preview) er den bredere, multimodale, agentiske kraftpakke — især når du har brug for visuel kontekst, værktøjsbrug, lang kontekst og dybe agent-workflows.
Jeg bruger i øjeblikket begge modeller, og de har hver deres fordele i udviklingsmiljøet. Jeg vil nu sammenligne dem i denne artikel.
Gemini 3 Pro er kun tilgængelig for Google AI Ultra-abonnenter og betalende Gemini API-brugere. Den gode nyhed er dog, at CometAPI som en alt-i-én AI-platform har integreret Gemini 3 Pro, og du kan prøve den gratis.
Hvad er Gemini 3 Pro Preview, og hvad er dens vigtigste funktioner?
Overblik
Gemini 3 Pro (tilgængelig indledningsvis som gemini-3-pro-preview) er Google/DeepMind’s seneste “frontier”-LLM i Gemini 3-familien. Den er positioneret som en høj-ræsonnerende, multimodal model optimeret til agentiske workflows (altså modeller, der kan bruge værktøjer, orkestrere underagenter og interagere med eksterne ressourcer). Den lægger vægt på stærkere ræsonnement, multimodalitet (billeder, videoframes, PDF’er) og eksplicitte API-kontroller for intern “tænknings”-dybde.
Vigtige punkter (udviklerfokus)
- Agentisk værktøjsbrug: indbygget function calling og værktøjer (kodekørsel, web-grounding, fil- & URL-kontekst, terminal-/værktøjsbrug).
- Thinking / Chain-of-Thought-understøttelse: “thinking”-primitiver til flertrinsplanlægning og interne “tanke”-signaturer for at gøre flertrinsræsonnement mere eksplicit.
- Multimodal input/output: tekst, billeder, lyd, video og strukturerede outputs med håndtering af lang kontekst.
- Kodekørselsværktøj & IDE-integrationer: et hostet kodekørselsværktøj og integrationer i IDE’er og den nye Google Antigravity agentiske IDE til kollaborativ autonom kodning. Antigravity er i øjeblikket offentlig preview.
- High/extended thinking-kontroller (
thinking_level-parameter), så du kan bytte latenstid for dybere intern ræsonnering.higher standard for Gemini 3 Pro. - Granulære multimodale kontroller (
media_resolution) til at afstemme billed-/video-fidelitet mod omkostning — nyttigt når modellen skal læse lille tekst i screenshots eller analysere frames.
Hvor Gemini 3 Pro brillierer til kodning
- Agentisk udvikling: orkestrering af flertrinsopgaver på tværs af editor/terminal/browser. Antigravitys artifact-system + Geminis værktøjer gør den fremragende til større feature-arbejde og automatisering.
- Visuelle + kode-kombinationer: at rette UI-fejl ud fra screenshots, generere UI-test-harnesses eller konvertere designbilleder til kode takket være stærk image-to-code-forståelse.
Hvad er Claude Sonnet 4.5, og hvad er dens vigtigste funktioner?
Claude Sonnet 4.5 er Anthropics 2025-udgivelse, som Anthropic markedsfører som deres stærkeste model til kodning, agentiske workflows og “brug af computere” (kontrollere værktøjer, browsere, terminaler, regneark osv.). Den lægger vægt på forbedret redigeringskapabilitet, værktøjssucces, udvidet tænkning, langvarig agent-koherens (30+ timers autonom opgaveløsning i demonstrationer) og lavere kode-redigeringsfejlrate end tidligere generationer. Anthropic kalder Sonnet 4.5 deres “bedste coding-model” med store fremskridt i redigeringspålidelighed og langhorisontet opgavekoherens.
Nøglefunktioner (udviklerfokus)
- Høj kodepræcision på virkelige engineering-benchmarks: Anthropic rapporterer state-of-the-art SWE-bench Verified-scorer og hævder store forbedringer i redigeringsfejlrater og værktøjsbaseret agent-succes.
- Agentiske og computerbrugsforbedringer: Sonnet 4.5 er designet til at køre flere værktøjer (bash, filredigering, browser-automation) og til at orkestrere underagenter via Claude Agent SDK. Anthropic fremhæver “30+ timer” kontinuerligt flertrinsarbejde i deres interne evalueringer.
- Store kontekstvinduer: som standard 200k tokens for de fleste kunder, med et 1M-token-kontekstvindue i beta for højere tier-organisationer (samme 1M-kapabilitet som Gemini tilbyder i preview).
- Kodekørselsværktøj & fil-API’er: i produktet og API-værktøjer muliggør sikker kodekørsel, filoprettelse/-redigering og test-run-sløjfer.
Hvor Sonnet 4.5 brillierer til kodning
- Rette softwareengineering-benchmarks og strukturerede kodeopgaver (unittest-generering, refaktorering af hele repositories), hvor modellens algoritmiske stringens og langhorisontede stabilitet betyder meget.
- Code-first CLI’er og “kodeassistent”-flows såsom Claude Code, hvor tæt terminalintegration og repository-scanning leveres out-of-the-box.
Hurtig sammenligningstabel
| Aspekt | Gemini 3 Pro (Preview) | Claude Sonnet 4.5 |
|---|---|---|
| Model / udgivelsesstatus | gemini-3-pro-preview — Google / DeepMind frontier-model (preview). Udgivet nov. 2025 (preview). | claude-sonnet-4-5 — Anthropic Sonnet-klasse frontier-model (GA / annonceret 29. sep. 2025). |
| Målretning (kodning & agenter) | Generel frontier-model med vægt på ræsonnement + multimodalitet + agentiske workflows; positioneret som Google’s topmodel til kodning/agenter. | Specialiseret til kodning, langhorisontet agenting og computerbrug (Anthropic’s “bedst til kodning & komplekse agenter”). |
| Vigtige udviklerfunktioner | thinking_level-kontrol til dybere intern ræsonnering; indbyggede Google-værktøjsintegrationer (Search grounding, kodekørsel, fil/URL-kontekst); dedikeret billedevariant til tekst+image-workflows. | Agent SDK’er, VS Code-integration (Claude Code), fil- & kodekørselsværktøjer, forbedringer til langhorisontet agenter (eksplicit testet til fler-timers kørsel). Fokus på iterative edit/run/test-workflows og checkpointing. |
| Kontekstvindue (input / output) | 1.000.000 tokens input / 64k tokens output for gemini-3-pro-preview | 1.000.000 tokens input / 64k tokens output |
| Priser (offentlig grundpris) | $2 / $12 per 1M tokens (input / output) for <200k-tier; højere satser for >200k (viser $4 / $18 for >200k). | Anthropic offentlig grundpris: $3 / $15 per 1M tokens (input / output) for Sonnet 4.5; |
| Multimodal kapabilitet (vision/video/lyd) | Fuld multimodal understøttelse: tekst, billeder, lyd, videoframes med konfigurerbare billed-/video-opløsningsparametre; dedikeret gemini-3-pro-image-preview. Stærk vægt på billede-OCR/visuel ekstraktion til kodnings-UI’er/screenshots. | Understøtter vision (tekst+image)-input og bruger vision til at understøtte kodningsworkflows; primært fokus er agentisk integration (brug af visuel kontekst i agent-flows fremfor paritet i billedgenerering). |
| Langhorisontet agentisk ydeevne & persistens | “Thinking”-primitiver til eksplicit flertrins intern ræsonnering; stærk matematik/ræsonnement & multimodal dybræsonnering. God til at dekomponere komplekse algoritmiske opgaver. Bedst til tung enkelt-svar-ræsonnering + multimodal analyse. | Anthropic fremhæver langhorisontet agentisk koherens — Anthropic rapporterer interne tests hvor Sonnet 4.5 opretholdt sammenhængende flertrins værktøjsbrug i 30+ timer og forbedrer kontinuerlig agentstabilitet vs. tidligere modeller. Godt match til vedvarende automatisering og CI-lignende agent-workflows. |
| Outputkvalitet til kodning (redigeringer, tests, pålidelighed) | Meget stærk single-shot-ræsonnering + kodegenerering; indbyggede værktøjer til at køre kode via Google’s tooling; høje resultater på algoritmiske benchmarks ifølge leverandør. Praktisk fordel når workflowet blander visuelle specifikationer + kode. | Designet til iterative edit→run→test-sløjfer; Sonnet 4.5 fremhæver forbedret “patching”-pålidelighed (rejection sampling / scoring-teknikker til at vælge robuste patches) og tooling, der understøtter iterative udviklerworkflows (checkpoints, tests). |
Hvordan sammenlignes deres arkitekturer og kernekapabiliteter?
Arkitektur og designintention (høj niveau)
Gemini 3 Pro: præsenteret som en multimodal, generel fundamentmodel med eksplicit engineering for “tænkning” og værktøjsbrug: designet lægger vægt på dybt ræsonnement, video/lyd-forståelse og agentisk orkestrering via indbygget function calling og kodekøringsmiljøer. Google fremstiller Gemini 3 Pro som den “mest intelligente” i familien, optimeret til brede opgaver ud over kode (selvom agentisk kodning er en prioritet).
Claude Sonnet 4.5: specifikt optimeret til agentiske workflows og kode: Anthropic lægger vægt på instruktionsfølgning, værktøjspålidelighed, redigerings-/korrektionsdygtighed og langhorisontet tilstandsadministration. Engineering-fokus er at minimere destruktive eller hallucinerede redigeringer og at muliggøre robuste interaktioner med virkelige computere.
Konklusion: Gemini 3 Pro præsenteres som en top-generelist, der er presset hårdt på multimodal ræsonnering og agentisk integration; Sonnet 4.5 præsenteres som specialist i kodning og agentisk værktøjsbrug med forbedrede garantier for redigering/korrektion.
Værktøjer og integrationer
- Gemini: indbygget Google-værktøjssuite inkl. Search grounding, filsøgning, kodekørsel og førsteklasses billede-/videoparametre;
thinking_level-parameter til at styre tradeoff mellem intern compute/latenstid. Dyb integration i Google-infrastruktur gør den bekvem for teams, der allerede er på Google Cloud. - Claude: robust agent-SDK og fokus på stabil langkørende beregning (Sonnet’s rapporterede 30+ timers koherens). Anthropic eksponerer også kodekørsel, fil-API’er og en ny “checkpoints”-redigerings-UX i Claude Code og VS Code-udvidelsen — funktioner der materielt forbedrer iterative kodningsworkflows.
Hvad siger tekniske specifikationer og benchmarks?
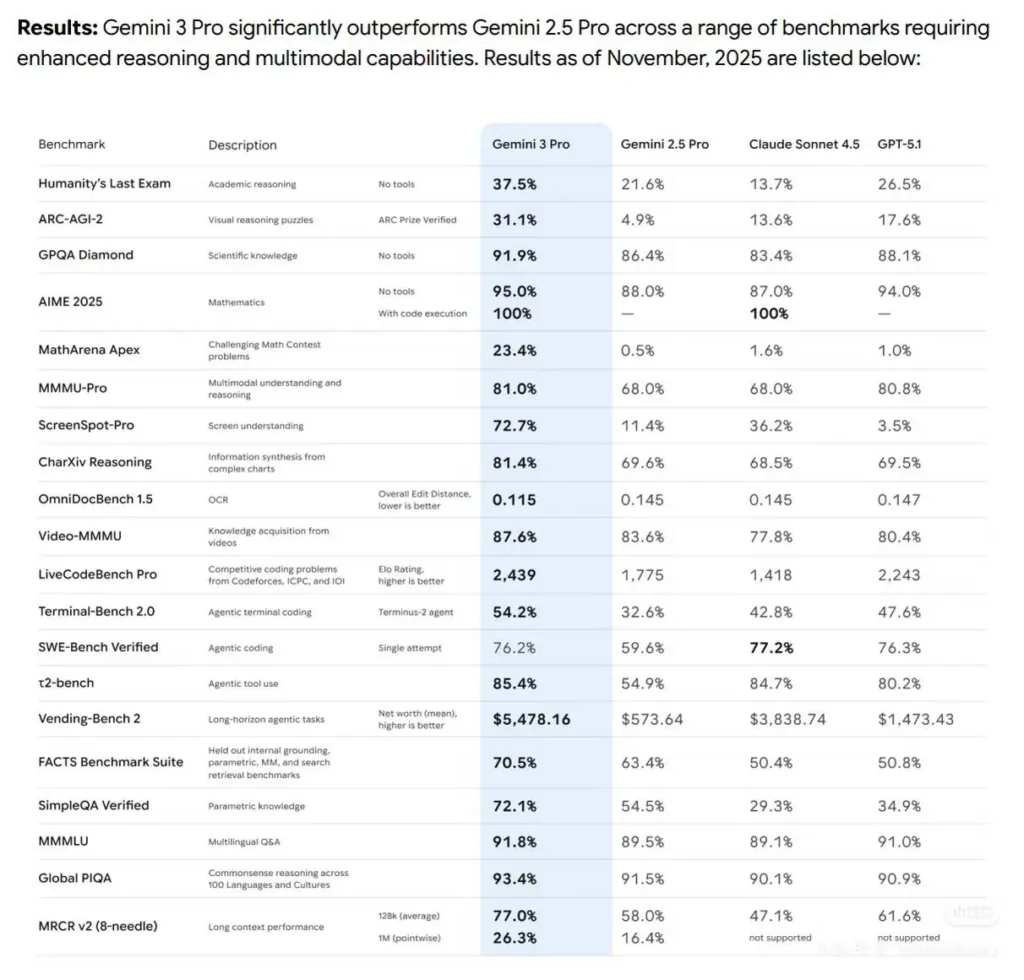
Benchmarks varierer en smule afhængigt af evaluator og konfiguration (enkeltforsøg vs. flere forsøg, værktøjsadgang, udvidet tænkning). Nedenfor er benchmark-dataanalyse af kodeevne:
SWE-bench Verified (virkelige softwareengineering-tests)
Claude Sonnet 4.5 (Anthropic rapporteret): 77,2% (200k tænkningsbudget; 78,2% i 1M-konfiguration). Anthropic rapporterer også en 82,0% high-compute-score ved brug af parallelle forsøg/rejection sampling.
Gemini 3 Pro (DeepMind rapportering / relaterede ranglister): ~76,2% enkeltforsøg på SWE-bench (leverandørtabel). Offentlige ranglister varierer (Gemini og Sonnet bytter snævre marginaler).
Terminal-Bench & agentiske opgaver
Gemini 3 Pro: Terminal-/agentic-bench-tal (leverandørtabel) viser stærk performance (fx Terminal-Bench 54,2% i leverandørtabel), konkurrencedygtig med Sonnets agentiske styrker.
Sonnet 4.5: excellerer i agentisk værktøjsorkestrering (Anthropic rapporterer betydelige gevinster på OSWorld og terminal-lignende benchmarks og fremhæver længere kontinuerlig opgaveudførelse).
Konklusion: de to modeller ligger meget tæt på moderne forståelses-/genereringsbenchmarks for kode; Sonnet 4.5 har en lille fordel på nogle softwareengineering-verifikationssuiter (Anthropics offentliggjorte tal), mens Gemini 3 Pro er ekstremt konkurrencedygtig og fører ofte på multimodale og nogle kodekonkurrence-lignende ranglister. Validér altid med den præcise evalueringskonfiguration (værktøjsadgang, kontekststørrelse, tænkningsbudgetter), fordi disse knapper ændrer scorerne væsentligt.
Hvordan sammenlignes deres multimodale kapabiliteter?
Vision & billedehåndtering
- Gemini 3 Pro: finkornede multimodale kontroller med billed-/video-
media_resolution(lave/mellem/høje tokenbudgetter per billede/frame), billedgenerering/redigering (separat billede-preview-model) og eksplicit vejledning til OCR/visuelle detaljer. Dette gør Gemini særligt stærk når kodningsopgaver kræver at læse screenshots, UI-mockups eller videoframes. - Claude Sonnet 4.5: understøtter tekst+image-multimodalitet og Anthropics produktintegrationer (Claude-apps) eksponerer visuelle workflows; fokus i Sonnet 4.5 er at integrere visuel kontekst i agentiske workflows fremfor rå paritet i billedsyntese.
Når multimodalitet betyder noget for kodning
Hvis din workflow i høj grad bygger på UI-screenshots, design-specs i billeder eller video-gennemgange, som modellen skal analysere for at producere eller ændre kode, kan Geminis dedikerede billedopløsningskontroller og billedgenereringsvariant være en praktisk fordel. Hvis din pipeline er agent-drevet automatisering (klikke rundt, køre kommandoer, redigere filer på tværs af værktøjer), er Claude’s agent-SDK og kodekøringsværktøjer førsteklasses.
Avanceret ræsonnement & langhorisontet planlægning — hvilken er bedst?
Sonnet 4.5: udholdenhed og alignment
Sonnet 4.5 kan opretholde sammenhængende arbejde i over 30 timer på tværs af komplekse flertrinsopgaver (planlægning, research, juridisk udarbejdelse, langvarige kodeopgaver). Denne udholdenhed plus Anthropics alignment-fokus gør Sonnet attraktiv til end-to-end-automatisering, hvor modellen skal holde styr på mål og bevare sikker adfærd.
Gemini 3 Pro: dybræsonnement + agentisk orkestrering
Gemini 3 Pro introducerer en “Deep Think”-variant og rigere interne thinking-API’er til flertrinsplanlægning, kombineret med Google’s agentiske IDE. I praksis betyder det, at Gemini både kan planlægge og udføre agentiske skridt på tværs af værktøjer (editor, shell, web). Hvis din automatisering kræver ekstern værktøjsadgang med artifact-oprettelse, er Geminis integrerede agentiske tooling (Antigravity) et stærkt plus. Bemærk: Deep Think bytter latenstid for dybde.
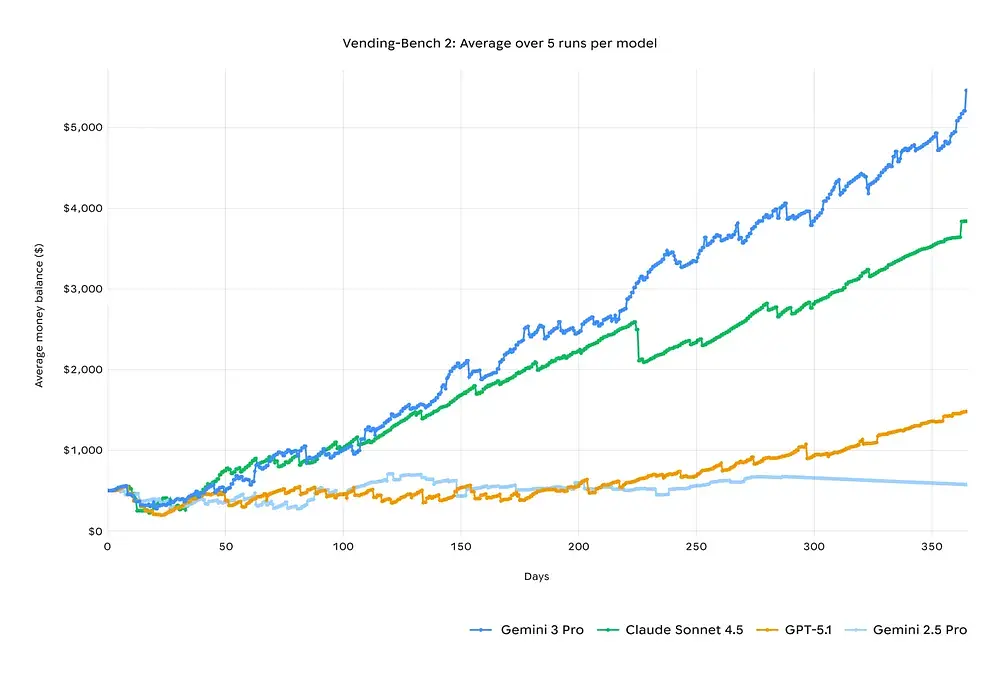
Langhorisontet planlægning: Vending-Bench 2
I simulationstesten “Vending-Bench 2” overgik Gemini 3 Claude 4.5 ved at drive en virtuel virksomhed i et helt år og forblive profitabel. I kortere tests var Gemini 3 Pro- og Claude 4 Sonnet-dataene ens, men forskellen blev tydeligere over længere testperioder.
Praktisk forskel
- Til single-shot-opgaver med høj grad af ræsonnement (kompleks algoritmisk debugging, dybe logiske beviser indlejret i kode) lover Geminis
thinking_levelog Deep Think større dybde i enkelt-svar. - Til langvarig, værktøjsdrevet automatisering (vedvarende agenter der kører mange kommandoer, skriver tests, itererer og håndterer tilstand), er Claude Sonnet 4.5’s langhorisontede fokus og agent-SDK markante differentiatore.
Hvordan sammenlignes API-adgang og priser for udviklere?
Gemini 3 Pro (Google) — adgang og priser
- Adgang: Gemini 3 Pro preview er tilgængelig via Google AI Studio og Vertex AI (model garden). SDK’er inkluderer google-genai til Python/JS/Go osv., plus OpenAI-compat-lag for lettere migration, med REST-endpoints og function calling / kodekørselsværktøjer. Antigravity leverer en IDE-overflade, der bruger Gemini 3 Pro i preview.
- Pris: Preview-priser listet i Google-dokumenter: $2 / $12 per 1M tokens (input / output) for <200k-tier; højere satser for >200k (eksempler i docs viser $4 / $18 for >200k).
Claude Sonnet 4.5 — adgang og priser
- API’er & SDK’er: Anthropic leverer Claude API, Claude Agent SDK til opbygning af agentiske workflows, fil-API’er og kodekørselsværktøjer (native VS Code-udvidelse, forbedringer i Claude Code og en “checkpoint”-funktion).
- Pris: 200k-token standardkontekstvindue, 1M-token-kontekst i beta for enterprise; pris $3 / $15 per 1M tokens (hhv. input/output)
Som udvikler bør du vælge model baseret på dine behov og dens karakteristika, ikke kun den billigste. Hvis opgaven kan løses af to modeller, så afgør det ud fra konteksten.
Hvis du vil bruge to modeller samtidig, anbefaler jeg CometAPI, som både tilbyder Gemini 3 Pro Preview API og Claude Sonnet 4.5 API, og er prissat til 20% af officiel pris.
| Gemini 3 Pro Preview | GPT-5.1 | |
| Input Tokens | $1.60 | $2.4.00 |
| Output Tokens | $9.60 | $12.00 |
Afsluttende tanker
Gemini 3 Pro (Preview) og Claude Sonnet 4.5 er begge state-of-the-art valg til kodeassistenter i slutningen af 2025. Sonnet 4.5 trækker fra Gemini i specifikke softwareengineering-verifikationsbenchmarks og udholdenhed på langhorisontede opgaver, mens Gemini 3 Pro leverer stærkere multimodal forståelse og dyb agentisk tooling, der kan eksekvere i editor/terminal/browser-miljøer. Det rigtige valg afhænger af, om dit primære behov er ren koderæsonnering og verifikation (Sonnet), eller multimodal, agentisk, værktøjsforstærket udvikling (Gemini). Til enterprise-implementering vil mange teams fornuftigt vælge en hybrid tilgang, hvor man bruger den model, der er stærkest til et givent trin i udviklingsworkflowet.
Udviklere kan få adgang til Gemini 3 Pro Preview API og Claude Sonnet 4.5 API via CometAPI. For at komme i gang kan du udforske modelkapabiliteterne i CometAPI i Playground og konsultere API-guiden for detaljerede instruktioner. Før adgang skal du sørge for, at du er logget ind på CometAPI og har indhentet API-nøglen. CometAPI tilbyder en pris langt under den officielle pris for at hjælpe dig med at integrere.
Klar til at gå i gang?→ Gratis prøve af Gemini 3 pro- og GPT-5.1-modeller !
Hvis du vil have flere tips, guider og nyheder om AI, så følg os på VK, X og Discord!