

GLM-4.6 er den seneste større udgivelse i Z.ais (tidligere Zhipu AI) GLM-familie: en 4. generations, storsproglig MoE-modellen (blanding af eksperter) indstillet til Agentworkflows, lang kontekstræsonnement og kodning i den virkelige verdenUdgivelsen lægger vægt på praktisk agent/værktøjsintegration, en meget stor kontekstvindueog tilgængelighed i åben vægt til lokal implementering.
Nøglefunktioner
- Lang kontekst — indfødt 200K token kontekstvindue (udvidet fra 128K). ()
- Kodning og agentfunktionalitet — markedsførte forbedringer af kodningsopgaver i den virkelige verden og bedre værktøjsaktivering for agenter.
- Effektivitet — rapporteret ~30% lavere tokenforbrug vs. GLM-4.5 på Z.ais tests.
- Implementering og kvantisering — først annonceret FP8- og Int4-integration til Cambricon-chips; native FP8-understøttelse på Moore Threads via vLLM.
- Modelstørrelse og tensortype — offentliggjorte artefakter indikerer en ~357B-parameter model (BF16 / F32 tensorer) på Krammeansigt.
Tekniske detaljer
Modaliteter og formater. GLM-4.6 er en kun tekst LLM (input- og outputmodaliteter: tekst). Kontekstlængde = 200K tokens; Maks. output = 128K tokens.
Kvantisering og hardwaresupport. Holdet rapporterer FP8/Int4 kvantisering på Cambricon-chips og native FP8 udførelse på Moore Threads GPU'er ved hjælp af vLLM til inferens — vigtigt for at sænke inferensomkostninger og muliggøre lokale og indenlandske cloud-implementeringer.
Værktøjer og integrationer. GLM-4.6 distribueres via Z.ais API, tredjepartsudbydernetværk (f.eks. CometAPI) og integreres i kodningsagenter (Claude Code, Cline, Roo Code, Kilo Code).
Tekniske detaljer
Modaliteter og formater. GLM-4.6 er en kun tekst LLM (input- og outputmodaliteter: tekst). Kontekstlængde = 200K tokens; Maks. output = 128K tokens.
Kvantisering og hardwaresupport. Holdet rapporterer FP8/Int4 kvantisering på Cambricon-chips og native FP8 udførelse på Moore Threads GPU'er ved hjælp af vLLM til inferens — vigtigt for at sænke inferensomkostninger og muliggøre lokale og indenlandske cloud-implementeringer.
Værktøjer og integrationer. GLM-4.6 distribueres via Z.ais API, tredjepartsudbydernetværk (f.eks. CometAPI) og integreres i kodningsagenter (Claude Code, Cline, Roo Code, Kilo Code).
Benchmark ydeevne
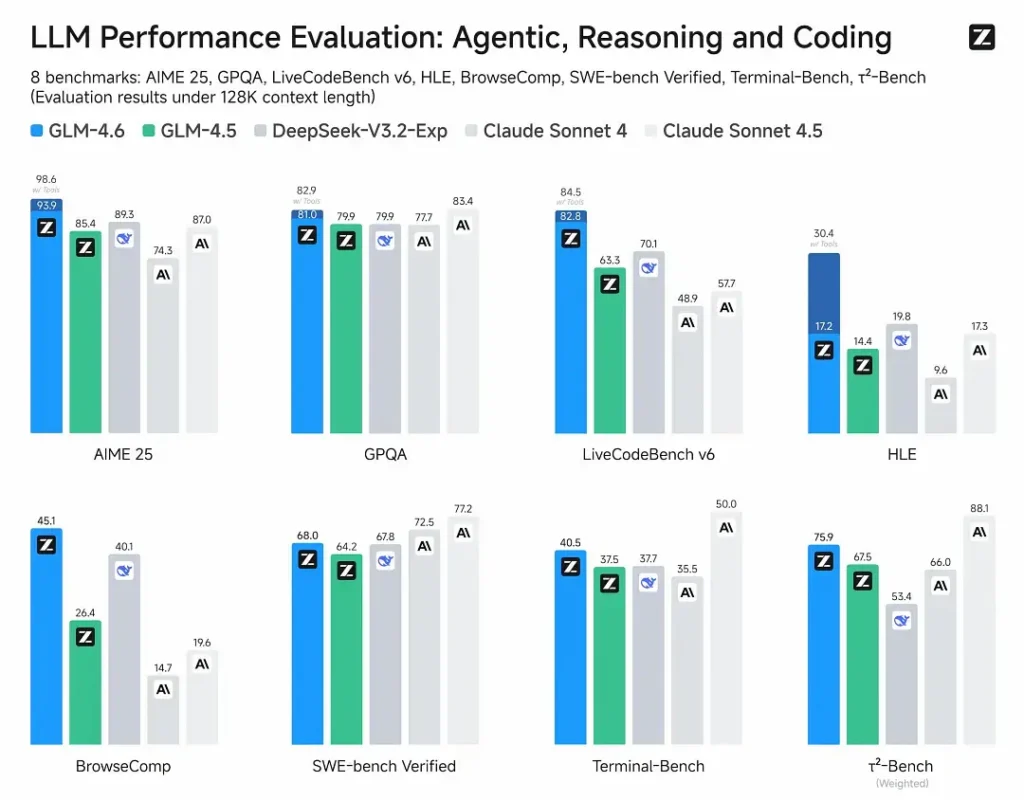
- Offentliggjorte evalueringer: GLM-4.6 blev testet på otte offentlige benchmarks, der dækker agenter, ræsonnement og kodning, og viser klare gevinster i forhold til GLM-4.5På menneskeligt evaluerede, virkelige kodningstests (udvidet CC-Bench) bruger GLM-4.6 ~15% færre tokens vs GLM-4.5 og poster en ~48.6% sejrsrate vs. Antropisk Claude Sonnet 4 (næsten paritet på mange ranglister).
- Positionering: Resultaterne hævder, at GLM-4.6 er konkurrencedygtig med førende indenlandske og internationale modeller (eksempler som DeepSeek-V3.1 og Claude Sonnet 4).
Begrænsninger og risici
- Hallucinationer og fejltagelser: Ligesom alle nuværende LLM'er kan GLM-4.6 indeholde faktuelle fejl – Z.ais dokumentation advarer eksplicit om, at output kan indeholde fejl. Brugere bør anvende verificering og hentning/RAG til kritisk indhold.
- Modelkompleksitet og visningsomkostning: 200K kontekst og meget store output øger dramatisk hukommelses- og latenskravene og kan øge inferensomkostningerne; kvantiseret/inferensteknik er nødvendig for at køre i stor skala.
- Domænehuller: Mens GLM-4.6 rapporterer stærk agent/kodningspræstation, bemærker nogle offentlige rapporter, at den stadig halter i visse versioner af konkurrerende modeller i specifikke mikrobenchmarks (f.eks. nogle kodningsmålinger vs. Sonnet 4.5). Vurder hver opgave, før produktionsmodeller udskiftes.
- Sikkerhed og politik: Åbne vægte øger tilgængeligheden, men rejser også spørgsmål om forvaltning (afbødende foranstaltninger, autoværn og røde teaming-foranstaltninger forbliver brugerens ansvar).
Brug sager
- Agentiske systemer og værktøjsorkestrering: lange agentspor, planlægning af flere værktøjer, dynamisk værktøjsaktivering; modellens agentiske tuning er et vigtigt salgsargument.
- Kodningsassistenter fra den virkelige verden: multi-turn kodegenerering, kodegennemgang og interaktive IDE-assistenter (integreret i Claude Code, Cline, Roo Code - i henhold til Z.ai). Forbedringer af tokeneffektivitet gøre det attraktivt for udviklerplaner med stor brug.
- Arbejdsgange med lange dokumenter: opsummering, syntese af flere dokumenter, lange juridiske/tekniske gennemgange på grund af 200K-vinduet.
- Indholdsskabelse og virtuelle karakterer: udvidede dialoger, konsekvent persona-vedligeholdelse i scenarier med flere turneer.
Hvordan GLM-4.6 er i sammenligning med andre modeller
- GLM-4.5 → GLM-4.6: trinvis ændring i kontekststørrelse (128K → 200K) og **token-effektivitet (~15% færre tokens på CC-Bench)**forbedret brug af agenter/værktøjer.
- GLM-4.6 vs. Claude Sonnet 4 / Sonnet 4.5: Z.ai rapporterer næsten ligestilling på flere ranglister og en succesrate på ~48.6% på CC-Bench-kodningsopgaver i den virkelige verden (dvs. tæt konkurrence med nogle mikrobenchmarks, hvor Sonnet stadig fører). For mange ingeniørteams er GLM-4.6 positioneret som et omkostningseffektivt alternativ.
- GLM-4.6 vs. andre modeller med lang kontekst (DeepSeek, Gemini-varianter, GPT-4-familien): GLM-4.6 lægger vægt på store kontekst- og agentkodningsworkflows; relative styrker afhænger af metrikker (tokeneffektivitet/agentintegration vs. nøjagtighed af råkodesyntese eller sikkerhedspipelines). Empirisk udvælgelse bør være opgavedrevet.
Zhipu AI's seneste flagskibsmodel GLM-4.6 udgivet: 355 mia. parametre i alt, 32 mia. aktive. Overgår GLM-4.5 i alle kernefunktioner.
- Kodning: Stemmer overens med Claude Sonnet 4, bedst i Kina.
- Kontekst: Udvidet til 200K (fra 128K).
- Ræsonnement: Forbedret, understøtter værktøjskald under inferens.
- Søgning: Forbedret værktøjsopkald og agentydeevne.
- Skrivning: Bedre overensstemmelse med menneskelige præferencer med hensyn til stil, læsbarhed og rollespil.
- Flersproget: Forbedret oversættelse på tværs af sprog.
Sådan ringer du GLM-**4.**6 API fra CometAPI
GLM‑4.6 API-priser i CometAPI, 20 % rabat på den officielle pris:
- Input-tokens: $0.64 millioner tokens
- Output-tokens: $2.56/M-tokens
Påkrævede trin
- Log ind på cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først.
- Log ind på din CometAPI-konsol.
- Få adgangslegitimations-API-nøglen til grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.

Brug metoden
- Vælg "
glm-4.6” endepunkt for at sende API-anmodningen og indstille anmodningsteksten. Forespørgselsmetoden og anmodningsteksten er hentet fra vores websteds API-dokument. Vores websted tilbyder også Apifox-test for din bekvemmelighed. - Erstatte med din faktiske CometAPI-nøgle fra din konto.
- Indsæt dit spørgsmål eller din anmodning i indholdsfeltet – det er det, modellen vil reagere på.
- . Behandle API-svaret for at få det genererede svar.
CometAPI leverer en fuldt kompatibel REST API – til problemfri migrering. Vigtige detaljer til API-dok:
- Basis URL: https://api.cometapi.com/v1/chat/completions
- Modelnavne: "
glm-4.6" - Godkendelse:
Bearer YOUR_CometAPI_API_KEYheader - Indholdstype:
application/json.
API-integration og eksempler
Nedenfor er en Python uddrag der demonstrerer hvordan man kalder GLM-4.6 via CometAPI's API. Erstat <API_KEY> og <PROMPT> derfor:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Nøgleparametre:
- modelAngiver GLM-4.6-varianten
- max_tokensStyrer outputlængden
- temperaturJusterer kreativitet vs. determinisme
Se også Claude Sonnet 4.5