

Den 3. marts 2026 introducerede Google Gemini 3.1 Flash-Lite, det nyeste medlem af Gemini 3-familien, der er designet specifikt som en motor med høj gennemstrømning, lav latens og høj omkostningseffektivitet til udvikler- og virksomhedsarbejdsbelastninger. Google positionerer Flash-Lite som den “hurtigste og mest omkostningseffektive” model i Gemini 3-serien: en letvægtsvariant, der sigter mod at levere streaminginteraktioner, storskala baggrundsbehandling og højfrekvente produktionstasks (for eksempel oversættelse, ekstraktion, UI-generering og klassificering i stor skala) til en meget lavere pris end Pro-modellerne.
Nedenfor gennemgår vi, hvad Flash-Lite er.
Hvad er Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite er et medlem af Googles Gemini 3-familie, der bevidst bytter noget af den højeste ræsonneringsdybde for hastighed og omkostningseffektivitet. Den er nativt multimodal i Gemini-linjen (kan acceptere tekst, billeder og andre modaliteter som input), men er tunet og implementeret specifikt til at levere maksimal tokens-per-sekund-gennemstrømning og væsentligt lavere afregning pr. token for workloads, der kræver hurtig, gentagen inferens frem for maksimal kognitiv dybde. Modellen beskrives som afledt af 3.1 Pro-arkitekturen, men optimeret til gennemstrømning, latens og omkostninger.
Centrale designafvejninger
Betegnelsen “Lite” signalerer modellens ingeniørmæssige fokus:
- Gennemstrømning frem for tung ræsonnering: Flash-Lite reducerer bevidst beregning pr. token for at levere hurtigere Time-to-First-Token (TTFT) og kontinuerlig outputhastighed. Det gør den ideel til pipelines, hvor hver forespørgsel skal betjenes hurtigt og i skala (fx sikkerhedsfiltre, realtidsassistenter, højvolumengenerering).
- Omkostningseffektivitet ved store volumener: Ved at sænke beregning pr. token kan modellen tilbydes til lavere priser pr. million tokens, hvilket reducerer marginalomkostningen i storskala applikationer (fx millioner til milliarder af tokens pr. måned). Googles forhåndspriser viser en markant forskel sammenlignet med Pro-niveauet.
- Kvalitet tunet til pragmatiske opgaver: Ifølge tidlige scoringsoversigter opretholder Flash-Lite stærke resultater på standardklassifikation, flersproglige og mange multimodale opgaver, men den er ikke positioneret til at slå Pro på de mest komplekse flertrins ræsonnerings- eller kodegenereringsbenchmarks, hvor dybde betyder noget.
Disse arbejdsbelastninger kræver pålideligt output og høj gennemstrømning, men de kræver ikke altid de komplekse flertrins ræsonneringsevner fra flagskibsmodeller.
Nøglefunktioner i Gemini 3.1 Flash-Lite
1. Lav latens og hurtig tid til første token
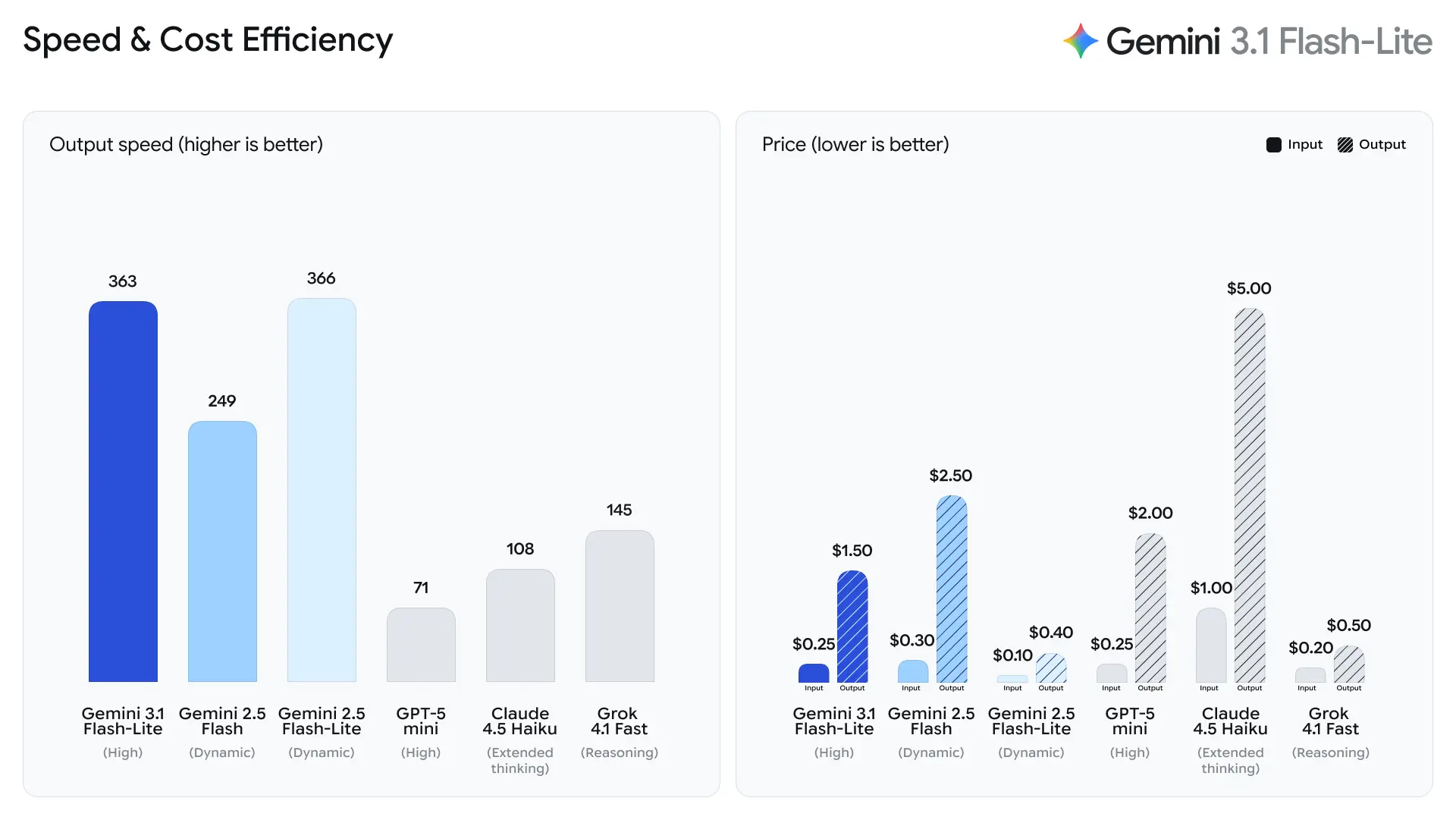
Google fremhæver time-to-first-answer token som en primær metrik for Flash-Lite. Selskabet rapporterer ~2.5× hurtigere tid til første token sammenlignet med Gemini 2.5 Flash og op til 45% hurtigere outputgenerering — forbedringer der direkte påvirker oplevet responsivitet for slutbrugere og gennemstrømningsomkostninger for backendsystemer. Disse gevinster gør Flash-Lite velegnet til interaktive funktioner (fx chatbots indlejret i apps) og pipelines med høj QPS, hvor mikrosekunder betyder noget.
Denne forbedring løfter markant realtidsapplikationer som:
- samtale-AI
- AI-drevne søgeassistenter
- interaktive chatbots
- live-oversættelsestjenester
Lavere latens forbedrer brugeroplevelsen ved at reducere ventetid og muliggøre mere flydende interaktioner.
2. Omkostningseffektiv token-prissætning
AI-inferensomkostninger beregnes ofte pr. token, hvilket gør prissætning til en kritisk faktor for storskala implementeringer.
Gemini 3.1 Flash-Lite introducerer en meget konkurrencedygtig prisstruktur:
| Token Type | Price |
|---|---|
| Input tokens | $0.25 pr. 1M tokens |
| Output tokens | $1.50 pr. 1M tokens |
Dette er en reduktion sammenlignet med tidligere Flash-modeller, hvilket gør modellen attraktiv for organisationer, der kører store workloads.
Til sammenligning:
| Model | Input Price | Output Price |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Denne prisstrategi gør det muligt for udviklere at køre AI i skala uden dramatisk at øge driftsomkostningerne.
Hvis du leder efter en endnu bedre pris, tilbyder Gemini Flash-Lite 20% rabat på CometAPI.
3. “Tankeniveauer” (kontrollerbar inferensdybde)
Gemini 3.1 Flash-Lite inkluderer funktionen “tankeniveauer” — en udviklerkonfigurerbar parameter, der instruerer modellen i at foretrække hurtigere, mere overfladisk behandling til trivielle opgaver og dybere ræsonnering til sværere opgaver. Dette er vigtigt i praksis, fordi det muliggør dynamiske kompromiser mellem omkostninger/latens pr. forespørgsel uden at skifte model.
Udviklere kan konfigurere modellens ræsonneringsdybde, så den matcher opgavens kompleksitet. Tankeniveauer: Understøtter fire niveauer: Minimal, Low, Medium og High.
Denne dynamiske tilgang gør det muligt for applikationer at optimere ressourceforbrug og samtidig opretholde kvalitet, hvor det er vigtigt. Den praktiske strategi er omtrent som følger:
- Minimal/Low: Velegnet til opgaver med høj samtidighed men logisk enkelhed, såsom oversættelse, klassifikation og sentimentanalyse, med prioritering af maksimal hastighed og minimale omkostninger.
- Medium: Velegnet til de fleste produktionsopgaver med en balance mellem kvalitet og effektivitet.
- High: Velegnet til opgaver, der kræver dyb ræsonnering, såsom generering af brugergrænseflader, oprettelse af simulationer og udførelse af komplekse instruktioner.
4. Multimodale muligheder med letvægtsprofil
Selv om Flash-Lite er optimeret til hastighed og omkostninger, bevarer den Gemini 3-seriens multimodale fundamenter: Den kan acceptere billedinput til klassifikation eller let multimodal ræsonnering, når use casen kræver det — men udviklere bør forvente, at det økonomiske design favoriserer kortere, afgrænsede multimodale operationer frem for meget store, billedtunge workflows. Ligesom andre Gemini-modeller understøtter Gemini 3.1 Flash-Lite multimodale input, hvilket gør det muligt for udviklere at behandle forskellige typer data.
Understøttede input omfatter:
- Tekst
- Billeder
- Video
- Lyd
- PDF'er
Modellens evne til at analysere flere typer information muliggør nye use cases, såsom:
- automatisk dokumentbehandling
- visuel dataekstraktion
- multimedieopsummering
Tidligere Gemini-modeller viste også stærk multimodal ræsonnering på tværs af visuelle og videnbaserede benchmarks.
Ydeevnebenchmarks — konkrete tal og hvad de betyder
Googles meddelelse og produktdokumentation præsenterer flere benchmarkdatapunkter, der skal hjælpe købere med at forstå, hvor Flash-Lite placerer sig i økosystemet.
Udviklerrettede hastighedsmetrikker
- 2.5× hurtigere tid til første svar-token vs Gemini 2.5 Flash (Googles angivne interne sammenligning).
- 45% hurtigere outputgenerering vs Gemini 2.5 Flash.
Dette er performance-engineeringmetrikker snarere end menneskevurderede kvalitetsmetrikker; de afspejler forbedringer i runtime-mikroarkitektur, batching og optimeringer i inferensstakken, der reducerer latens for korte svar. Hurtigere første-token-tider reducerer oplevet forsinkelse i interaktive applikationer og øger den samlede gennemstrømning pr. server, hvilket kan sænke de samlede beregningsomkostninger for samme QPS.
Tokens per sekund (t/s) og gennemstrømning
Ifølge Artificial Analysis' testdata opnåede 3.1 Flash-Lite en outputhastighed på 388.8 tokens pr. sekund (medianen for modeller i samme prisklasse er kun 96.7 tokens/sekund). Denne hastighed er i top blandt modeller i sin klasse.
Dog påpegede Artificial Analysis også et problem: 3.1 Flash-Lites latens for første token (TTFT) er 5.18 sekunder, hvilket er relativt højt for inferensmodeller i samme prisklasse (medianen er 1.82 sekunder). Derudover genererede modellen 53 millioner tokens under evalueringsprocessen, hvilket er relativt højt sammenlignet med gennemsnittet på 20 millioner. Det betyder, at hvis dit scenarie er meget følsomt over for første-token-latens eller har strenge krav til output-koncished, kan du få behov for at optimere tankeniveau og prompts.
Benchmarkresultater for ræsonnering og faktuel korrekthed
Google inkluderede sammenligninger på tværs af modeller, der viser, at Gemini 3.1 Flash-Lite klarer sig stærkt mod jævnaldrende og tidligere Gemini-varianter på samlede ræsonnerings-/faktuelle opgaver:
- Arena.ai Elo-score: Gemini 3.1 Flash-Lite opnåede angiveligt en Elo på 1432 på Arena-evalueringsleaderboardet — en sammensat head-to-head-placering, der viser konkurrencedygtig relativ performance i direkte sammenligninger.
- GPQA Diamond: 86.9% (et mål for robustheden i besvarelse af spørgsmål).
- MMMU Pro: 76.8% (en multimodal/multitask-metrik, der bruges internt/eksternt af nogle laboratorier).
- LiveCodeBench (kodningsevne): 72.0%
- CharXiv Reasoning (grafisk ræsonnering): 73.2%
- Video-MMMU (videoforståelse): 84.8%
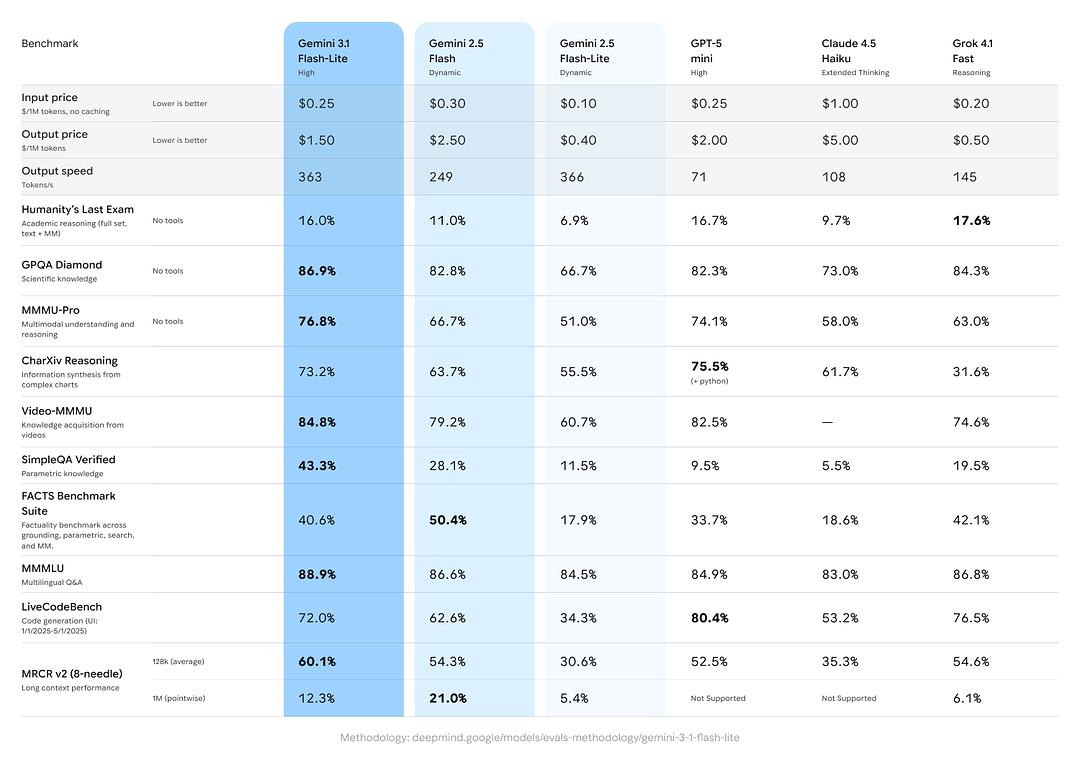
Gemini 3.1 Flash-Lite overgår ældre Gemini 2.5 Flash på flere af disse metrikker og leverer samtidig meget bedre hastighed/omkostning.
Anvendelsestilfælde, der passer til Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite er designet omkring et klart sæt praktiske workloads, hvor høj gennemstrømning og lavere omkostning pr. token er afgørende:
Højfrekvente konversationsagenter og streaming-UI
Realtidschatbots, live transkription + oversættelsesstreams og kollaborative UI'er, der viser delvise svar, mens modellen genererer, drager fordel af Flash-Lites streaming-tokenoutput og lave tid til første token.
Masse-databehandling (RAG, transformationspipelines)
Massiv dokumentindtagelse: enhedsekstraktion, metadatamærkning, klassifikation og oversættelse udført over millioner af dokumenter — Gemini 3.1 Flash-Lite sænker inferensomkostningerne samtidig med, at den giver acceptabel nøjagtighed for skabelon- eller regeldrevne outputs.
Edge-lignende eller baggrundsberegning
Workloads, der løbende behandler indkommende telemetri eller ustrukturerede data (fx indholdsmoderationsklassifikation, automatiseret rapportgenerering), er gode kandidater, fordi Gemini 3.1 Flash-Lite minimerer omkostningen pr. enhed.
Udviklerværktøjer og batch-kodefuldførelse
For funktioner som scaffoldering på tværs af flere filer, storskala kodelinting og skabelongenerering i skala reducerer Gemini 3.1 Flash-Lites hastighedsfordele latens og omkostninger for udvikleroplevelsesværktøjer, hvor absolut maksimal ræsonneringsdybde ikke er påkrævet.
Sammenligning af Gemini 3.1 Flash-Lite med andre Gemini-modeller og konkurrenter
Inden for Gemini-familien
- Gemini 3.1 Pro: højeste kapabilitet på kompleks ræsonnering og flertrins planlægning; væsentligt dyrere og langsommere pr. token, men bedre til dybe, nuancerede opgaver.
- Gemini 3.1 Flash (ikke-Lite): sigter mod et kompromis mellem rå gennemstrømning og kapabilitet — Flash-Lite optimerer yderligere ned gennem beregningsstakken for maksimal gennemstrømning.
Sammenlignet med konkurrerende “hurtige” modeller
Gemini 3.1 Flash-Lite overgår eller matcher flere hurtige/mini-modeller på mange gennemstrømnings- og kvalitetsmetrikker — men uafhængige analytikere advarer om, at direkte head-to-head-sammenligninger er følsomme over for evalueringsmetodik og valg af datasæt. Forvent, at Gemini 3.1 Flash-Lite er meget konkurrencedygtig på gennemstrømning og omkostning, mens den forbliver omkring midterfeltet på de højeste ræsonneringsmetrikker.
Konklusion — hvor Flash-Lite passer ind i AI-stakken
Gemini 3.1 Flash-Lite er et bevidst ingeniørarbejde: et effektivt, gennemstrømningsfokuseret medlem af Gemini 3-familien, der lader teams bytte noget per-eksempel-beregning for dramatiske forbedringer i latens og omkostninger. For virksomheder og udviklere, der bygger højvolumen-pipelines — oversættelser, batchbehandling, streaming-UI'er og opgaver med moderat kompleksitet — repræsenterer Flash-Lite en fornuftig basismotor. For organisationer, der kræver den absolut højeste ræsonneringsfidelitet, er Pro-modellerne stadig det passende valg.
Hvis din arbejdsbelastning domineres af mange korte, gentagelige inferenser, eller du har brug for hurtig streamingoutput i stor skala, er Flash-Lite værd at pilotteste. Hvis din arbejdsbelastning afhænger af dyb multi-hop-ræsonnering, så planlæg en hybrid tilgang: diriger gennemstrømnings-trafik til Flash-Lite og eskaler komplekse, højværdi-forespørgsler til Pro-modeller.
Udviklere kan få adgang til Gemini 3.1 Flash Lite via CometAPI nu. For at komme i gang kan du udforske modellens kapabiliteter i Playground og konsultere API guide for detaljerede instruktioner. Før adgang, skal du sikre, at du er logget ind på CometAPI og har fået en API-nøgle. CometAPI tilbyder en pris langt under den officielle pris for at hjælpe dig med integrationen.
Ready to Go?→ Tilmeld dig Gemini 3.1 Flash-Lite i dag !
Hvis du vil have flere tips, vejledninger og nyheder om AI, så følg os på VK, X og Discord!