

OpenAI offentliggjorde en forhåndsvisning af forskningen gpt-oss-sikkerhedsbeskyttelse, en åbenvægts inferensmodelfamilie, der er udviklet til at lade udviklere håndhæve deres egen sikkerhedspolitikker på inferenstidspunktet. I stedet for at levere en fast klassifikator eller en black-box-modereringsmotor er de nye modeller finjusteret til årsag fra en politik leveret af udvikleren, udsende en tankekæde (CoT), der forklarer deres ræsonnement, og producere strukturerede klassifikationsoutput. gpt-oss-safeguard, der blev annonceret som en forskningsforhåndsvisning, præsenteres som et par ræsonnementsmodeller—gpt-oss-safeguard-120b og gpt-oss-safeguard-20b—finjusteret fra gpt-oss-familien og eksplicit designet til at udføre sikkerhedsklassificering og politikhåndhævelsesopgaver under inferens.
Hvad er gpt-oss-safeguard?
gpt-oss-safeguard er et par åbne, tekstbaserede ræsonnementsmodeller, der er blevet eftertrænet fra gpt-oss-familien til fortolke en politik skrevet i naturligt sprog og mærke tekst i overensstemmelse med denne politikDet særlige træk er, at politikken er leveret på inferenstidspunktet (policy-as-input), ikke indbygget i statiske klassifikatorvægte. Modellerne er primært designet til sikkerhedsklassificeringsopgaver – f.eks. moderering af flere politikker, indholdsklassificering på tværs af flere reguleringsordninger eller kontrol af politikoverholdelse.
Hvorfor dette spørgsmål
Traditionelle moderationssystemer er typisk afhængige af (a) faste regelsæt, der er knyttet til klassifikatorer, der er trænet ud fra mærkede eksempler, eller (b) heuristikker/regexer til nøgleordsdetektion. gpt-oss-safeguard forsøger at ændre paradigmet: i stedet for at omtræne klassifikatorer, når politikken ændres, leverer du en politiktekst (f.eks. din virksomheds politik for acceptabel brug, platformens brugsbetingelser eller en regulators retningslinje), og modellen ræsonnerer om, hvorvidt et givet stykke indhold overtræder denne politik. Dette lover agilitet (politikændringer uden omtræning) og fortolkelighed (modellen leverer sin ræsonnementskæde).
Dette er dens kernefilosofi – "At erstatte udenadslære med ræsonnement og gætværk med forklaring."
Dette repræsenterer en ny fase inden for indholdssikkerhed, hvor man går fra "passiv indlæring af regler" til "aktiv forståelse af regler".
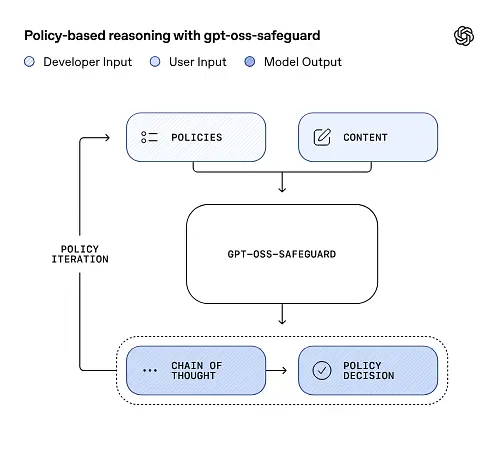
gpt-oss-safeguard kan direkte læse de sikkerhedspolitikker, der er defineret af udviklerne, og følge disse politikker for at foretage vurderinger under inferens.
Hvordan fungerer gpt-oss-safeguard?
Politik-som-input-argumentation
Ved inferenstidspunktet angiver du to ting: politiktekst og kandidatindhold skal mærkes. Modellen behandler politikken som den primære instruktion og udfører derefter trinvis argumentation for at afgøre, om indholdet er tilladt, ikke tilladt eller kræver yderligere modereringstrin. Ved inferens gør modellen følgende:
- producerer et struktureret output, der inkluderer en konklusion (etiket, kategori, konfidens) og et menneskeligt læsbart ræsonnement, der forklarer, hvorfor denne konklusion blev nået.
- indtager politikken og det indhold, der skal klassificeres,
- ræsonnerer internt gennem politikkens klausuler ved hjælp af tankekædelignende trin, og
For eksempel:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Den vil svare:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Tankekæde (CoT) og strukturerede output
gpt-oss-safeguard kan udsende et fuldt CoT-spor som en del af hver inferens. CoT'en er beregnet til at være inspicerbar – compliance-teams kan læse, hvorfor modellen nåede en konklusion, og ingeniører kan bruge sporet til at diagnosticere politikuklarhed eller modelfejltilstande. Modellen understøtter også strukturerede output—for eksempel en JSON, der indeholder en dom, overtrådte politikafsnit, alvorlighedsscore og foreslåede afhjælpende handlinger — hvilket gør det nemt at integrere i moderationspipelines.
Justerbare niveauer af "ræsonnementsindsats"
For at afbalancere latenstid, omkostninger og grundighed understøtter modellerne konfigurerbar ræsonnementindsats: lav / mellem / højHøjere indsats øger dybden af tankekæden og giver generelt mere robuste, men langsommere og dyrere, inferenser. Dette giver udviklere mulighed for at prioritere arbejdsbyrder – brug lav indsats til rutinemæssigt indhold og høj indsats til edge cases eller indhold med høj risiko.
Hvad er modellens struktur, og hvilke versioner findes der?
Modelfamilie og slægt
gpt-oss-safeguard er efteruddannet varianter af OpenAIs tidligere gpt-oss åbne modeller. Safety-familien omfatter i øjeblikket to udgivne størrelser:
- gpt-oss-safeguard-120b — en model på 120 milliarder parametre beregnet til ræsonnementsopgaver med høj nøjagtighed, der stadig kører på en enkelt 80 GB GPU i optimerede runtimes.
- gpt-oss-safeguard-20b — en model på 20 milliarder parametre, der er optimeret til billigere inferens og edge- eller on-prem-miljøer (kan køre på 16 GB VRAM-enheder i nogle konfigurationer).
Arkitekturnoter og runtime-karakteristika (hvad man kan forvente)
- Aktive parametre pr. token: Den underliggende gpt-oss-arkitektur bruger teknikker, der reducerer antallet af parametre, der aktiveres pr. token (en blanding af tæt og sparsom opmærksomhed / blanding af eksperter-stildesign i den overordnede gpt-oss).
- Praktisk set passer 120B-klassen på enkelte store acceleratorer, og 20B-klassen er designet til at fungere på 16 GB VRAM-opsætninger i optimerede runtimes.
Sikkerhedsmodeller var ikke trænet med yderligere biologiske eller cybersikkerhedsdata, og at analyser af worst-case misbrugsscenarier udført for gpt-oss-udgivelsen nogenlunde gælder for beskyttelsesvarianterne. Modellerne er beregnet til klassificering snarere end indholdsgenerering til slutbrugere.
Hvad er målene med gpt-oss-safeguard
Mål
- Politikfleksibilitet: Lad udviklere definere enhver politik i naturligt sprog og få modellen til at anvende den uden indsamling af brugerdefinerede etiketter.
- Forklarlighed: afdække ræsonnement, så beslutninger kan revideres, og politikker kan itereres.
- Tilgængelighed: tilbyde et åbent alternativ, så organisationer kan udføre sikkerhedsræsonnement lokalt og inspicere modellens indre dele.
Sammenligning med klassiske klassifikatorer
Fordele vs. traditionelle klassifikatorer
- Ingen efteruddannelse ved politikændringer: Hvis din modereringspolitik ændres, skal du opdatere politikdokumentet i stedet for at indsamle etiketter og omtræn en klassifikator.
- Rigere argumentation: CoT-output kan afsløre subtile politiske interaktioner og give narrativ begrundelse, der er nyttig for menneskelige anmeldere.
- Tilpasning: En enkelt model kan anvende mange forskellige politikker samtidigt under inferens.
Ulemper vs. traditionelle klassifikatorer
- Ydelseslofter for nogle opgaver: OpenAIs evaluering bemærker, at Klassifikatorer af høj kvalitet, der er trænet på titusindvis af mærkede eksempler, kan overgå gpt-oss-safeguard på specialiserede klassifikationsopgaver. Når målet er nøjagtighed af rå klassifikation, og du har mærkede data, kan en dedikeret klassifikator, der er trænet i den fordeling, være bedre.
- Latens og omkostninger: Ræsonnement med CoT er computerintensivt og langsommere end en letvægtsklassifikator; dette kan gøre rent sikkerhedsbaserede pipelines dyre i stor skala.
Kort sagt: gpt-oss-safeguard bruges bedst hvor politisk agilitet og revisionsbarhed er prioriteter, eller når mærkede data er knappe – og som en komplementær komponent i hybride pipelines, ikke nødvendigvis som en drop-in-erstatning for en skalaoptimeret klassifikator.
Hvordan klarede gpt-oss-safeguard sig i OpenAIs evalueringer?
OpenAI offentliggjorde baselineresultater i en 10-siders teknisk rapport, der opsummerer interne og eksterne evalueringer. Vigtigste konklusioner (udvalgte, bærende målinger):
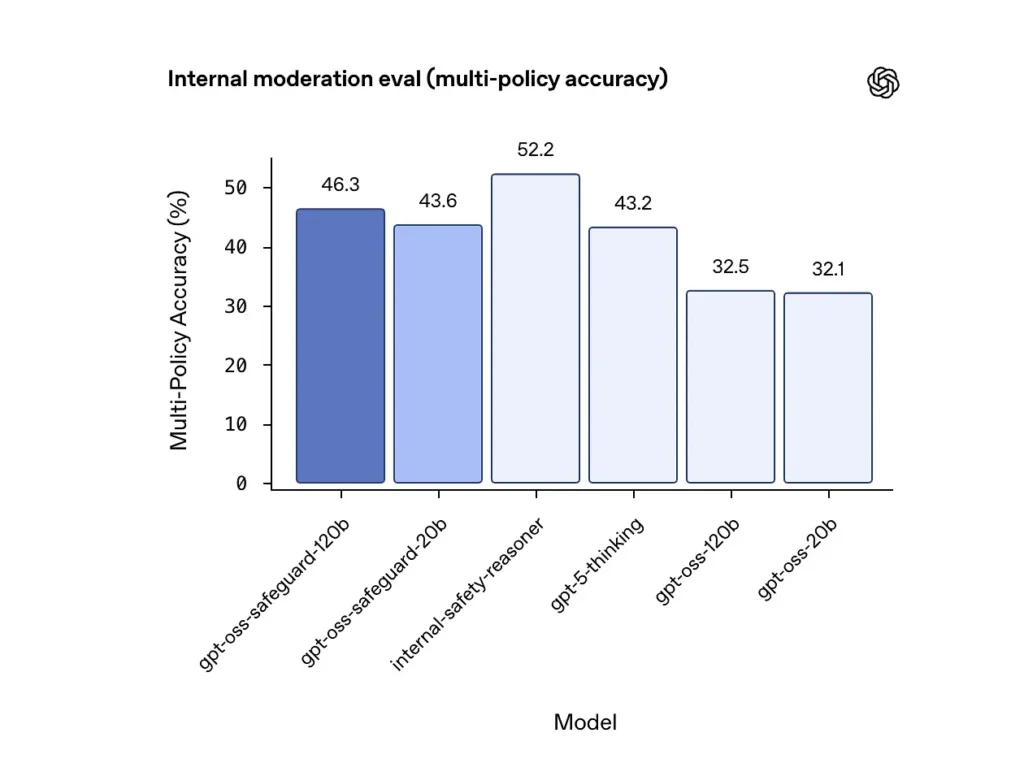
Nøjagtighed på tværs af flere politikker (intern evaluering)
OpenAI evaluerede nøjagtigheden af flere politikker ved at give modellen flere politikker samtidigt og kun tælle en forudsigelse som korrekt, hvis den matchede de gyldne etiketter på tværs alle politikker. Resultater:
- gpt-oss-safeguard-120b: 46.3% nøjagtighed i flere politikker
- gpt-oss-safeguard-20b: 43.6%
- Til sammenligning: gpt-5-tænkning: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
OpenAIs interne "safety-reasoner"-ensemble scorede 52.2% i samme test. Disse tal viser, at safety-modellerne klarer sig væsentligt bedre end deres gpt-oss-basismodeller på multi-policy-opgaven, og de overgik endda den større gpt-5-thinking-grundlinje i den interne multi-policy-måling.
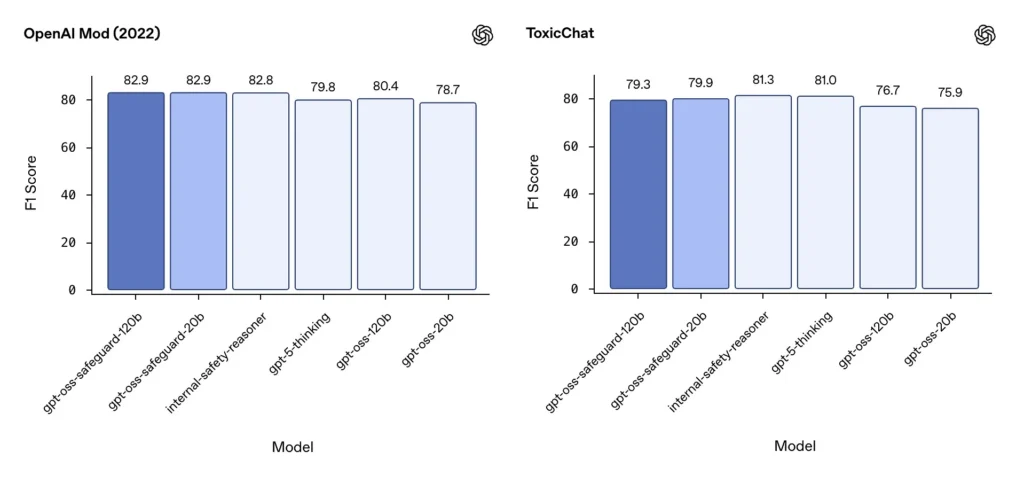
Moderering F1 (eksterne benchmarks)
På OpenAIs modereringsdatasæt fra 2022 og den offentlige ToxicChat-benchmark opnåede gpt-oss-safeguard-modellerne solide F1-scorer:
- OpenAI-mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Disse scorer placerer gpt-oss-safeguard nær eller en smule bag specialiserede OpenAI interne systemer på nogle benchmarks, og generelt foran de ufinjusterede gpt-oss-modparter.
Observerede begrænsninger
OpenAI markerer to praktiske begrænsninger:
- Klassifikatorer trænet på store, opgavespecifikke, mærkede datasæt kan stadig overgå sikkerhedsmodeller når klassificeringsnøjagtighed er det eneste mål.
- Beregnings- og latenstidsomkostninger: CoT-ræsonnement øger inferenstiden og beregningsforbruget, hvilket komplicerer skalering til trafik på platformsniveau, medmindre det parres med triage-klassifikatorer og asynkrone pipelines.
Flersproget paritet
gpt-oss-safeguard præsterer på niveau med de underliggende gpt-oss-modeller på tværs af mange sprog i MMMLU-lignende tests, hvilket indikerer, at de finjusterede safeguard-varianter bevarer bred ræsonnementsevne.
Hvordan kan teams tilgå og implementere gpt-oss-safeguard?
OpenAI leverer vægtene under Apache 2.0 og linker modellerne til download (Hugging Face). Da gpt-oss-safeguard er en åben vægtmodel, anbefales lokal og selvadministreret implementering (anbefales af hensyn til privatliv og tilpasning).
- Download modelvægte (fra OpenAI / Hugging Face) og host dem på dine egne servere eller cloud-VM'er. Apache 2.0 tillader modifikation og kommerciel brug.
- RuntimeBrug standard inferens-runtimes, der understøtter store transformer-modeller (ONNX Runtime, Triton eller optimerede leverandør-runtimes). Community-runtimes som Ollama og LM Studio tilføjer allerede understøttelse af gpt-oss-familier.
- Hardware120B kræver typisk GPU'er med høj hukommelse (f.eks. 80 GB A100/H100 eller multi-GPU sharding), mens 20B kan køres billigere og har muligheder optimeret til 16 GB VRAM-opsætninger. Planlæg kapacitet til peak throughput og omkostninger til evaluering af flere politikker.
Administrerede og tredjeparts runtime-programmer
Hvis det er upraktisk at køre din egen hardware, CometAPI tilføjer hurtigt understøttelse af gpt-oss-modeller. Disse platforme giver muligvis nemmere skalering, men genintroducerer afvejninger vedrørende dataeksponering med tredjepart. Evaluer privatliv, SLA'er og adgangskontroller, før du vælger administrerede runtime-programmer.
Effektive modereringsstrategier med gpt-oss-safeguard
1) Brug en hybrid pipeline (triage → begrundelse → afgørelse)
- Triage-lag: Små, hurtige klassifikatorer (eller regler) filtrerer trivielle tilfælde fra. Dette reducerer belastningen på den dyre sikkerhedsmodel.
- Beskyttelseslag: Kør gpt-oss-safeguard for tvetydige, højrisiko- eller flerpolitiktjek, hvor politiknuancer er vigtige.
- Menneskelig bedømmelse: eskalerer sager og appeller på kanten af processen, og lagrer CoT som bevis for gennemsigtighed. Dette hybride design balancerer gennemløb og præcision.
2) Policy engineering (ikke prompt engineering)
- Behandl politikker som softwareartefakter: versionsér dem, test dem mod datasæt, og hold dem eksplicitte og hierarkiske.
- Skriv politikker med eksempler og modeksempler. Inkluder, når det er muligt, flertydige instruktioner (f.eks. "Hvis brugerintentionen tydeligt er udforskende og historisk, skal den markeres som X; hvis intentionen er operationel og realtidsbaseret, skal den markeres som Y").
3) Konfigurer ræsonnementsindsatsen dynamisk
- Brug lav indsats til bulkforarbejdning og høj indsats for markeret indhold, appeller eller vertikaler med stor effekt (juridisk, medicinsk, finansiel).
- Juster tærskler med feedback fra mennesker for at finde det optimale pris/kvalitetsforhold.
4) Valider CoT og hold øje med hallucinationer
CoT er værdifuld, men den kan hallucinere: sporet er en modelgenereret begrundelse, ikke sandheden på jorden. Revider CoT's output rutinemæssigt; instrumentdetektorer for hallucinerede citater eller uoverensstemmelser i ræsonnementet. OpenAI dokumenterer hallucinerede tankekæder som en observeret udfordring og foreslår afbødende strategier.
5) Opbyg datasæt fra systemdrift
Log modelbeslutninger og menneskelige korrektioner for at oprette mærkede datasæt, der kan forbedre triageklassifikatorer eller informere omskrivning af politikker. Over tid reducerer et lille, mærket datasæt af høj kvalitet plus en effektiv klassifikator ofte afhængigheden af fuld CoT-inferens for rutinemæssigt indhold.
6) Overvåg beregning og omkostninger; anvend asynkrone flows
For forbrugerrettede applikationer med lav latenstid bør man overveje asynkrone sikkerhedstjek med en kortsigtet konservativ brugeroplevelse (f.eks. midlertidigt at skjule indhold, der afventer gennemgang) i stedet for at udføre højtydende CoT synkront. OpenAI bemærker, at Safety Reasoner bruger asynkrone flows internt til at administrere latenstid for produktionstjenester.
7) Overvej privatliv og implementeringsplacering
Da vægte er åbne, kan du køre inferens udelukkende on-premises for at overholde streng datastyring eller reducere eksponering for tredjeparts-API'er – værdifuldt for regulerede brancher.
konklusion:
gpt-oss-safeguard er et praktisk, transparent og fleksibelt værktøj til politikdrevet sikkerhedsargumentationDen skinner, når du har brug for det revisionsbare beslutninger knyttet til eksplicitte politikker, når dine politikker ændres ofte, eller når du ønsker at holde sikkerhedskontroller på stedet. Det er ikke en mirakelkur, der automatisk vil erstatte specialiserede klassifikatorer med høj volumen – OpenAIs egne evalueringer viser, at dedikerede klassifikatorer, der er trænet i store mærkede korpora, kan overgå disse modeller på rå nøjagtighed for snævre opgaver. Behandl i stedet gpt-oss-safeguard som en strategisk komponent: den forklarlige ræsonnementsmotor i hjertet af en lagdelt sikkerhedsarkitektur (hurtig triage → forklarlig ræsonnement → menneskeligt tilsyn).
Kom godt i gang
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere – såsom OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i en enkelt, udviklervenlig grænseflade. Ved at tilbyde ensartet godkendelse, formatering af anmodninger og svarhåndtering forenkler CometAPI dramatisk integrationen af AI-funktioner i dine applikationer. Uanset om du bygger chatbots, billedgeneratorer, musikkomponister eller datadrevne analysepipelines, giver CometAPI dig mulighed for at iterere hurtigere, kontrollere omkostninger og forblive leverandøruafhængig – alt imens du udnytter de seneste gennembrud på tværs af AI-økosystemet.
Den seneste integration med gpt-oss-safeguard vil snart blive vist på CometAPI, så følg med! Mens vi færdiggør upload af gpt-oss-safeguard-modellen, kan udviklere få adgang til den. GPT-OSS-20B API og GPT-OSS-120B API gennem Comet API, den nyeste modelversion opdateres altid med den officielle hjemmeside. For at begynde, udforsk modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!