

Grok-4-Fast er xAI's ny omkostningseffektiv ræsonnementsmodel designet til at gøre ræsonnement og websøgning af høj kvalitet billigere og hurtigere for både forbrugere og udviklere. xAI positionerer det som en grænse et tilbud, der bevarer Grok-4's benchmark-ydeevne, samtidig med at det forbedrer token-effektiviteten, og som leverer to varianter, der er tunet til begge dele. ræsonnement or ikke-ræsonnement arbejdsbelastninger.
Nøglefunktioner (hurtig liste)
- To modelvarianter:
grok-4-fast-reasoningoggrok-4-fast-non-reasoning(kan justeres for dybde vs. hastighed). - Meget stort kontekstvindue: op til 2,000,000-symboler, hvilket muliggør ekstremt lange dokumenter / transskriptioner på flere timer / arbejdsgange med flere dokumenter.
- Tokeneffektivitet / omkostningsfokus: xAI-rapporter ~40% færre tænkebrikker i gennemsnit versus Grok-4 og en påstået ~98% reduktion i omkostninger for at opnå samme benchmark-ydeevne (på xAI-rapporterne om metrikker).
- Indbygget værktøj / browserintegration: trænet end-to-end med værktøjsbaseret RL til web/X-browsing, kodeudførelse og agentisk søgeadfærd.
- Multimodal og funktionskald: understøtter billeder og strukturerede output; funktionskald og strukturerede svarformater understøttes i API'en.
Tekniske detaljer
Ensartet ræsonnementarkitektur: Grok-4-Fast bruger en vægtbase med én model der kan styres ind i ræsonnement (lang tankekæde) eller ikke-ræsonnement (hurtige svar) adfærd via systemprompter eller variantvalg i stedet for at levere to helt separate backbone-modeller. Dette reducerer switching latency og token-omkostninger for blandede arbejdsbelastninger.
Forstærkningslæring for intelligenstæthed: xAI-rapporter ved hjælp af storstilet forstærkningslæring fokuseret på intelligenstæthed (maksimering af ydeevne pr. token), hvilket er grundlaget for de angivne gevinster i tokeneffektivitet.
Værktøjsbehandling og agentsøgning: Grok-4-Fast blev trænet og evalueret i opgaver, der kræver aktiveringsværktøjer (websurfing, X-søgning, kodeudførelse). Modellen præsenteres som dygtig til vælge hvornår man skal tilkalde værktøjer, og hvordan man kan sammensætte browsing evidens til svar.
Benchmark ydeevne
Iforbedringer i BrowseComp (44.9% bestået@1 vs. 43.0% for Grok-4), **SimpleQA (95.0% vs. 94.0%)**og store gevinster i visse kinesisksprogede browser-/søgearenaer. xAI rapporterer også en topplacering i LMArenas søgearena for en grok-4-fast-search variant.
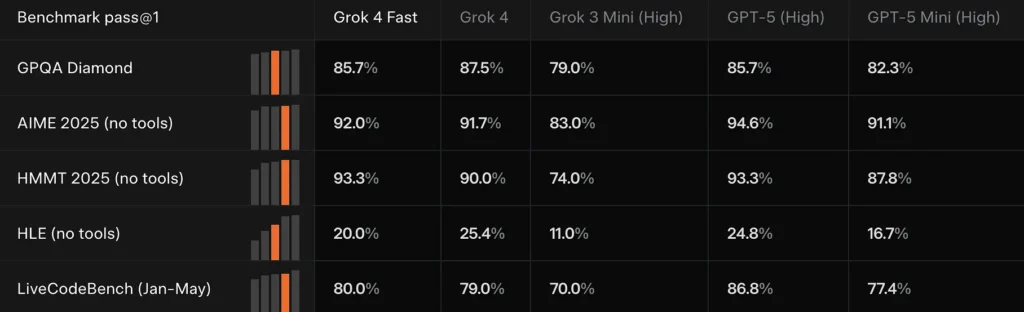
Modelversioner og navngivning
Offentlige navne annonceret af xAI: grok-4-fast-reasoning og **grok-4-fast-non-reasoning**Hver variant rapporterer det samme 2M token kontekstgrænse. Platformen fortsætter også med at være vært for den tidligere Grok-4 flagskib (f.eks. grok-4-0709 varianter brugt tidligere).
Begrænsninger og sikkerhedshensyn
- Bekymringer om indholdssikkerhed: Rapportering fra efterforskningskanaler indikerer, at xAI's Grok-familie (og nogle Grok-funktioner) er blevet udviklet med tilladelige indholdsmuligheder, og at nogle interne arbejdsgange har udsat annotatorer for stærkt forstyrrende materiale. Der er eksplicitte bekymringer om robustheden af moderering og rapportering til myndighederne af ulovligt indhold. Disse sikkerheds- og compliance-problemer er væsentlige, når man implementerer enhver Grok-variant i produktion.
- Uafhængig verifikation: Mange af xAI's påstande om præstation/økonomi er selvrapporterede; uafhængige benchmarks og peer reviews offentliggøres stadig. Behandl påstande om omkostningseffektivitet som leverandørleverede, indtil tredjepartsreplikering er tilgængelig.
- Operationelle risici: fordi Grok-4-Fast er designet til agentisk browsing, bør brugerne bemærke hallucination, grænser for dataaktualitet (på trods af browsingfunktioner), og Beskyttelse af personlige oplysninger overvejelser, når modellen bruges med eksterne værktøjer eller live webforespørgsler.
Typiske og anbefalede anvendelsesscenarier
- Søgning og hentning med høj kapacitet — søgeagenter, der har brug for hurtig multi-hop web-ræsonnement.
- Agentassistenter og bots — agenter, der kombinerer browsing, kodeudførelse og asynkrone værktøjskald (hvor det er tilladt).
- Omkostningsfølsomme produktionsimplementeringer — tjenester, der kræver mange opkald og ønsker forbedret token-to-utility-økonomi i forhold til en tungere basismodel.
- Udviklereksperimenter — prototyping af multimodale eller web-udvidede flows, der er afhængige af hurtige, gentagne forespørgsler.
Sådan ringer du grok-4-fast API fra CometAPI
grok-code-fast-1 API-priser i CometAPI, 20 % rabat på den officielle pris:
| grok-4-fast-ikke-ræsonnement | Input-tokens: $0.16/M tokens Output-tokens: $0.40/M-tokens |
| grok-4-hurtig-ræsonnement | Input-tokens: $0.16/M tokens Output-tokens: $0.40/M-tokens |
Påkrævede trin
- Log ind på cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først
- Få adgangslegitimations-API-nøglen til grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.
Brug metoden
- Vælg "
grok-4-fast-reasoning”/“grok-4-fast-reasoning"slutpunkt" til at sende API-anmodningen og indstille anmodningsteksten. Anmodningsmetoden og anmodningsteksten kan hentes fra vores hjemmesides API-dokumentation. Vores hjemmeside tilbyder også Apifox-tests for din bekvemmelighed. - Erstatte med din faktiske CometAPI-nøgle fra din konto.
- Indsæt dit spørgsmål eller din anmodning i indholdsfeltet – det er det, modellen vil reagere på.
- . Behandle API-svaret for at få det genererede svar.
CometAPI leverer en fuldt kompatibel REST API – til problemfri migrering. Vigtige detaljer til API-dok:
- Basis URL: https://api.cometapi.com/v1/chat/completions
- Modelnavne:"
grok-4-fast-reasoning”/“grok-4-fast-reasoning" - Godkendelse: Bærertoken via
Authorization: Bearer YOUR_CometAPI_API_KEYheader - Indholdstype:
application/json.
API-integration og eksempler
Python-kodestykke til et Chatafslutning kald gennem CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-4-fast's main features."}
]
response = openai.ChatCompletion.create(
model="grok-4-fast-reasoning",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Se også Grok 4