

GLM-5 er Zhipu AI’s nye open-weight, agentcentreret grundmodel bygget til lang-horisont kodning og multi-trins agenter. Den er tilgængelig via flere hostede API’er (inklusive CometAPI og udbyder-endpoints) og som en forskningsudgivelse med kode og vægte; du kan integrere den med standard OpenAI-kompatible REST-kald, streaming og SDK’er.
Hvad er GLM-5 fra Z.ai?
GLM-5 er Z.ai’s femte generations flagskibs-grundmodel designet til agentisk engineering: lang-horisont planlægning, multi-trins værktøjsbrug og storstilet kode/systemdesign. Offentligt lanceret i februar 2026, GLM-5 er en Mixture-of-Experts (MoE) model med ~744 milliarder totale parametre og et aktivt parametersæt i 40B-området pr. forward pass; arkitektur- og træningsvalg prioriterer lang-kontekst kohærens, værktøjskald samt omkostningseffektiv inferens til produktionsbelastninger. Disse designvalg gør det muligt for GLM-5 at køre udvidede agentiske workflows (for eksempel: browse → planlæg → skriv/test kode → iterér) samtidig med at konteksten bevares over meget lange input.
Key technical highlights :
- MoE-arkitektur ved ~744B totale / ~40B aktive parametre; skaleret prætræning (~28.5T tokens rapporteret) for at mindske afstanden til de førende lukkede modeller.
- Lang-kontekst support og optimeringer (deep sparse attention, DSA) for reducerede driftsomkostninger i forhold til naiv tæt skalering.
- Agentiske funktioner indbygget: værktøjs-/funktionskald, tilstandsførende sessioner og integrerede outputs (kan producere
.docx,.xlsx,.pdfartefakter som del af agent-workflows i udbyderes brugerflader). - Tilgængelighed med åbne vægte (vægte publiceret til modelhubs) og hostede adgangsmuligheder (udbyder-API’er, inferens-mikrotjenester).
Hvad er de vigtigste fordele ved GLM-5?
Agentisk planlægning og lang-horisont hukommelse
GLM-5’s arkitektur og tuning prioriterer konsistent flertrins ræsonnement og hukommelse på tværs af workflows — en fordel for:
- autonome agenter (CI-pipelines, opgaveorkestratorer),
- storstilet generering af kode på tværs af flere filer eller refaktoreringer, og
- dokumentintelligens, der skal fastholde omfattende historik.
Store kontekstvinduer
GLM-5 understøtter meget store kontekststørrelser (i størrelsesordenen ~200k tokens i offentliggjorte modelspecs), så du kan bevare mere af en session i én anmodning og reducere behovet for aggressiv chunking eller ekstern hukommelse for mange brugstilfælde. (Se sammenligningstabellen nedenfor.)
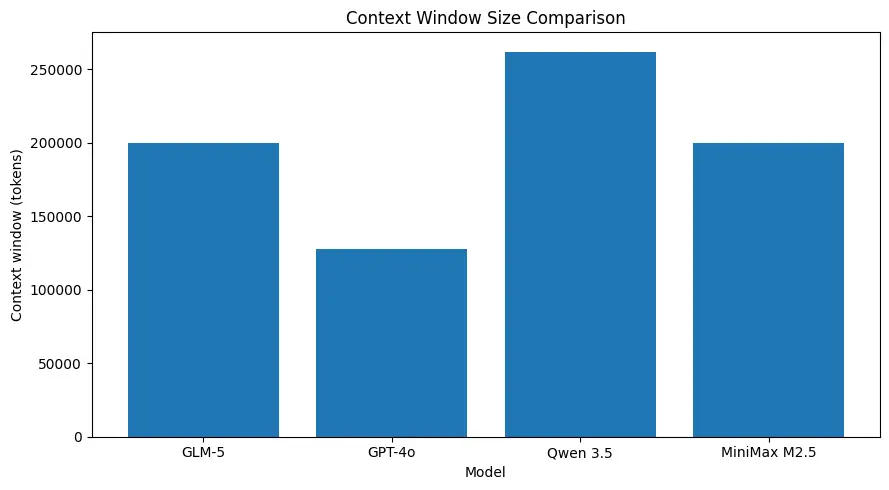
Stærk kodepræstation til systemniveauopgaver
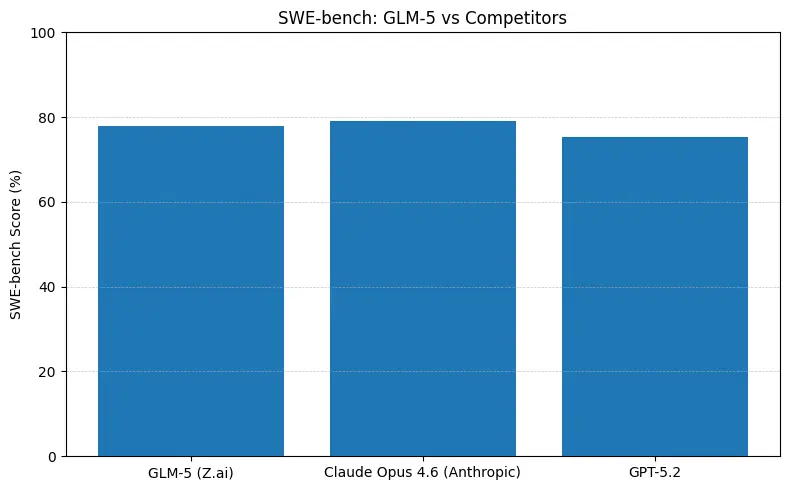
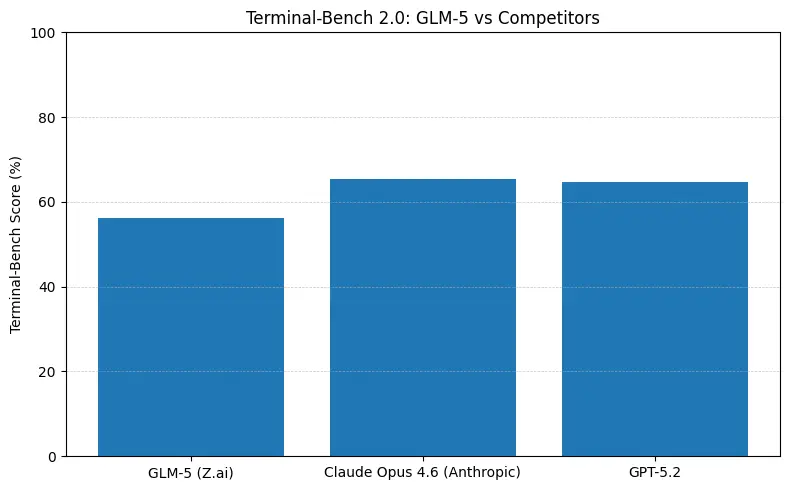
GLM-5 rapporterer top-performance blandt open source på software engineering-benchmarks (SWE-bench og anvendte kode- + agent-suiter). På SWE-bench-Verified rapporterer den ~77.8%; på kode-/terminalagtige agenttests (Terminal-Bench 2.0) ligger scorerne i midt-50’erne—evidens for praktisk kodeevne tæt på de førende proprietære modeller. Disse metrics betyder, at GLM-5 er egnet til opgaver som kodegenerering, automatiseret refaktorering, flerfilers ræsonnement og CI/CD-assistent-scenarier.
Omkostnings-/effektivitetsafvejninger
Fordi GLM-5 bruger MoE og “sparse” attention-innovationer, sigter den mod at reducere inferensomkostninger pr. kapabilitetsenhed sammenlignet med brute-force tæt skalering. CometAPI tilbyder konkurrencedygtige prisniveauer, der gør GLM-5 attraktiv til agentiske workloads med høj gennemstrømning.
Hvordan bruger jeg GLM-5 API via CometAPI?
Kort svar: behandl CometAPI som en OpenAI-kompatibel gateway — angiv din basis-URL og API-nøgle, vælg glm-5 som model, og kald chat/completions-endpointet. CometAPI tilbyder en OpenAI-lignende REST-overflade (endpoints som /v1/chat/completions) plus SDK’er og eksempelprojekter, der gør migrering triviel.
Nedenfor er en praktisk, produktionsorienteret kogebog: autentificering, grundlæggende chatkald, streaming, funktions-/værktøjskald samt omkostnings-/respons-håndtering.
De grundlæggende trin for at få adgang til GLM-5 via CometAPI er:
- Tilmeld dig på CometAPI, og få en API-nøgle.
- Find den nøjagtige model-id for GLM-5 i CometAPI’s katalog (
"glm-5"afhængigt af listen). - Send en autentificeret POST-anmodning til CometAPI’s chat/completions-endpoint (OpenAI-stil).
Grunddetaljer (CometAPI-mønstre): platformen understøtter OpenAI-sti-format som https://api.cometapi.com/v1/chat/completions, Bearer-autentificering, model-parameter, system-/brugermeddelelser, streaming og både curl/python-eksempler i dokumentationen.
Eksempel: hurtig Python (requests) chat-completion med GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Eksempel: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Streaming-svar (praktisk mønster)
CometAPI understøtter OpenAI-stil streaming (SSE / chunked). Den enkleste tilgang i Python er at angive "stream": true og iterere over responsdata, efterhånden som de ankommer. Dette er vigtigt, når du har brug for lav-latens delvise outputs (byg realtids-dev-assistenter, streaming-UI’er).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Reference: OpenAI-stil streaming og CometAPI-kompatibilitetsdokumentation.
Funktions-/værktøjskald (sådan kaldes et eksternt værktøj)
GLM-5 understøtter funktions- eller værktøjskaldsmønstre, der er kompatible med OpenAI-/aggregator-konventioner (gatewayen passerer strukturerede funktionskald i modelresponsen). Eksempelbrug: bed GLM-5 om at kalde et lokalt “run_tests”-værktøj; modellen returnerer en struktureret instruktion, du kan parse og udføre.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Når modellen returnerer en function_call-payload, udfør værktøjet på serversiden, og send derefter værktøjsresultatet tilbage som en meddelelse med rollen "tool" og fortsæt samtalen. Dette mønster muliggør sikker værktøjsinvokation og tilstandsfulde agentflows. Se CometAPI’s dokumenter og eksempler for konkrete SDK-hjælpere.
Praktiske parametre og tuning
function_call: bruges til at aktivere struktureret værktøjsinvokation og sikrere eksekveringsflows.
temperature: 0–0.3 for deterministiske systemniveau-outputs (kode, infrastruktur), højere til idéudvikling.
max_tokens: sæt efter forventet outputlængde; GLM-5 understøtter meget lange outputs ved hosted drift (udbydergrænser varierer).
top_p / nucleus sampling: nyttigt til at begrænse usandsynlige haler.
stream: true til interaktive UI’er.
GLM-5 sammenlignet med Anthropics Claude Opus og andre frontmodeller
Kort svar: GLM-5 mindsker afstanden til de førende lukkede modeller på agentiske og kode-benchmarks, samtidig med at den tilbyder deployment med åbne vægte og ofte bedre pris pr. token, når den hostes af aggregatorer. Nuancen: på nogle absolutte kode-benchmarks (SWE-bench, Terminal-Bench-varianter) ligger Anthropics Claude Opus (4.5/4.6) stadig et par point foran i mange offentliggjorte lister — men GLM-5 er meget konkurrencedygtig og overgår mange andre åbne modeller.
Hvad tallene betyder i praksis
- SWE-bench (~kodekorrekthed/engineering): Claude Opus viser et marginalt forspring (≈79% vs GLM-5 ≈77.8%) på offentliggjorte leaderboards; for mange reelle opgaver vil dette oversættes til færre manuelle rettelser, men ikke nødvendigvis til et andet arkitekturvalg for prototyper eller skalerede agentiske workflows.
- Terminal-Bench (kommandolinje-agentiske opgaver): Opus 4.6 fører (≈65.4% vs GLM-5 ≈56.2%) — hvis du har brug for robust terminalautomatisering og højeste pålidelighed på out-of-distribution shell-ops, er Opus ofte bedre ved margen.
- Agentisk og lang-horisont: GLM-5 klarer sig særdeles godt på lang-horisont forretningssimulationer (Vending-Bench 2 balance $4,432 rapporteret) og viser stærk planlægningskohærens for flertrins workflows. Hvis dit produkt er en langvarig agent (finans, drift), er GLM-5 stærk.
Hvordan designer jeg prompts og systemer for at få pålidelige GLM-5-outputs?
Systemmeddelelser og eksplicitte begrænsninger
Giv GLM-5 en stram rolle og begrænsninger, især for kode- eller værktøjskald-opgaver. Eksempel:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Bed om tests og kort begrundelse for hver ikke-triviel ændring.
Nedbryd komplekse opgaver
I stedet for “skriv hele produktet”, bed om:
- designoversigt,
- interface-signaturer,
- implementering og tests,
- endeligt integrationsscript.
Denne trinvis nedbrydning reducerer hallucinationer og giver deterministiske checkpoints, du kan validere.
Brug lav temperatur for deterministisk kode
Når du beder om kode, sæt temperature = 0–0.2 og max_tokens til en sikker øvre grænse. For kreativ skrivning eller design-brainstorming, hæv temperaturen.
Best practices ved integration af GLM-5 (via CometAPI eller direkte hosts)
Prompt engineering og systemprompter
- Brug eksplicitte systeminstruktioner, der definerer agentroller, politikker for værktøjsadgang og sikkerhedsbegrænsninger. Eksempel: “Du er systemarkitekt: foreslå kun ændringer, når unit tests passerer lokalt; list præcise CLI-kommandoer, der skal køres.”
- Til kodeopgaver, giv repository-kontekst (fillister, nøglekodeudsnit) og vedhæft unit-test outputs, hvis tilgængeligt. GLM-5’s lang-konteksthåndtering hjælper — men sørg altid for, at essentiel kontekst kommer først (rolle, opgave) og derefter støtteartefakter.
Session- og tilstandshåndtering
- Brug session-ID’er til lange agentsamtaler og hold en kompakt “hukommelse” over tidligere trin (resuméer) for at undgå kontekstsvulst. CometAPI og lignende gateways leverer session-/state-hjælpere — men applikationsniveau-state-komprimering er essentiel for langvarige agenter.
Værktøjer og funktionskald (sikkerhed + pålidelighed)
- Eksponér et snævert, reviderbart sæt værktøjer. Tillad ikke vilkårlig shell-eksekvering uden menneskelig kontrol. Brug strukturerede funktionsdefinitioner og valider deres argumenter på serversiden.
- Log altid værktøjskald og modelresponser for sporbarhed og efterfølgende fejlsøgning.
Omkostningskontrol og batching
- For højvolumen-agenter, rout baggrundsbehandling til billigere modelvarianter, når kvalitetsafvejninger er acceptable (CometAPI lader dig skifte modeller efter navn). Batch lignende anmodninger og reducer
max_tokens, hvor det er muligt. Overvåg input vs. output-token-forhold — output-tokens er ofte dyrere.
Latens- og gennemstrømningsengineering
- Brug streaming til interaktive sessioner. For baggrunds-agentjobs, foretræk asynkrone runtime-miljøer, arbejdskøer og rate-limiters. Hvis du selv hoster (åbne vægte), tun din accelerator-topologi til MoE-arkitekturen — FPGA / Ascend / specialiserede siliciumløsninger kan give omkostningsfordele.
Afsluttende bemærkninger
GLM-5 repræsenterer et praktisk skridt med åbne vægte mod agentisk engineering: store kontekstvinduer, planlægningskapabiliteter og stærk kodepræstation gør den attraktiv til udviklerværktøjer, agentorkestrering og systemniveau-automatisering. Brug CometAPI til hurtig integration eller en cloud-modelhave til managed hosting; valider altid på din egen workload og instrumentér grundigt for omkostnings- og hallucinationskontrol.
Udviklere kan få adgang til GLM-5 via CometAPI nu. For at komme i gang, udforsk modellens kapabiliteter i Playground og konsulter API guide for detaljerede instruktioner. Før adgang, sørg venligst for, at du er logget ind på CometAPI og har fået API-nøglen. CometAPI tilbyder en pris langt under den officielle pris for at hjælpe dig med integrationen.
Klar til at komme i gang?→ Tilmeld dig M2.5 i dag !
Hvis du vil have flere tips, guider og nyheder om AI, så følg os på VK, X og Discord!