

Kinas Z.ai (tidligere Zhipu AI) har endnu engang greb overskrifterne med lanceringen af sin open source GLM 4.5-serie. GLM-4.5 er positioneret som et omkostningseffektivt og højtydende alternativ til eksisterende store sprogmodeller og lover at omforme tokenøkonomien og demokratisere adgangen for både startups, virksomheder og forskningsinstitutioner. Denne omfattende artikel udforsker GLM-4.5-seriens oprindelse, prisstruktur og reelle værdi – og adresserer de to centrale spørgsmål, som alle interessenter har: Hvor meget koster det, og er det det værd?
Hvad er GLM 4.5-serien?
Z.ais GLM 4.5-serie er bygget på et "agentisk" AI-framework, hvilket betyder, at modellen autonomt kan opdele komplekse opgaver i mindre, sekventielle delopgaver – hvilket forbedrer præcisionen og reducerer redundant beregning. Dette står i kontrast til mere monolitiske LLM'er, der håndterer prompts i en enkelt omgang. Ifølge Z.ai integrerer GLM 4.5 nativt ræsonnement og handlingsplanlægning i sin kernearkitektur, hvilket muliggør flertrinsarbejdsgange såsom generering af datavisualisering eller end-to-end dokumentbehandling uden ekstern orkestrering.
GLM 4.5-serien, udviklet af Z.ai, repræsenterer den seneste generation af open source, Mixture-of-Experts (MoE) store sprogmodeller designet til at forene avanceret ræsonnement, kodegenerering og agentfunktioner inden for en enkelt arkitektur. Den fås i to hovedvarianter: flagskibet GLM 4.5 (355 B i alt parametre, 32 B aktive) og lighteren GLM 4.5-Air (106 B i alt, 12 B aktive). Begge varianter udnytter en hybrid inferensmekanisme - "tænketilstand" til kompleks, værktøjsaktiveret ræsonnement og "ikke-tænketilstand" til hurtige og ligetil færdiggørelser - der dækker et bredt spektrum af use cases fra full-stack-udvikling til autonome agent-workflows.
centrale tekniske specifikationer:
- DriftsparametreGLM 4.5 har 355 milliarder parametre med en aktiv delmængde på 32 milliarder aktiveret pr. inferens for at optimere hardwarebrug og gennemløb.
- **Blanding af eksperter (MoE)**Serien udnytter MoE-arkitektur og routerer dynamisk tokens til ekspertundernetværk for effektivitet.
- KontekstvindueUdvidet til 128 tokens på udvalgte platforme (f.eks. SiliconFlow), der understøtter store dokumenter og kodebaser.
- GenerationshastighedHøjhastighedsvarianter overstiger 100 tokens/sekund, velegnede til realtidsapplikationer.
- Hybride inferenstilstandeBrugere kan skifte mellem "tænke"-tilstand (fuld MoE-aktivering for dyb ræsonnement) og "ikke-tænkende"-tilstand (minimal aktivering for hurtige reaktioner undervejs), hvilket giver udviklere finjusteret kontrol over ydeevne versus hastighed.
Hvilke varianter findes der i serien?
- **GLM 4.5 (Standard)**355 B i alt / 32 B aktive parametre. Primært designet til afbalanceret ydeevne på tværs af ræsonnement, kodning og agentopgaver.
- GLM 4.5-AirEn letvægtsversion med 106 B i alt / 12 B aktive parametere, skræddersyet til scenarier med strenge hardware- eller latensbegrænsninger – der leverer konkurrencedygtig nøjagtighed i sin klasse.
Hvor meget koster GLM 4.5-serien?
Hvad er priserne på input- og output-tokens?
Ifølge Z.ais offentlige API-prisoplysninger er GLM 4.5 prissat til:
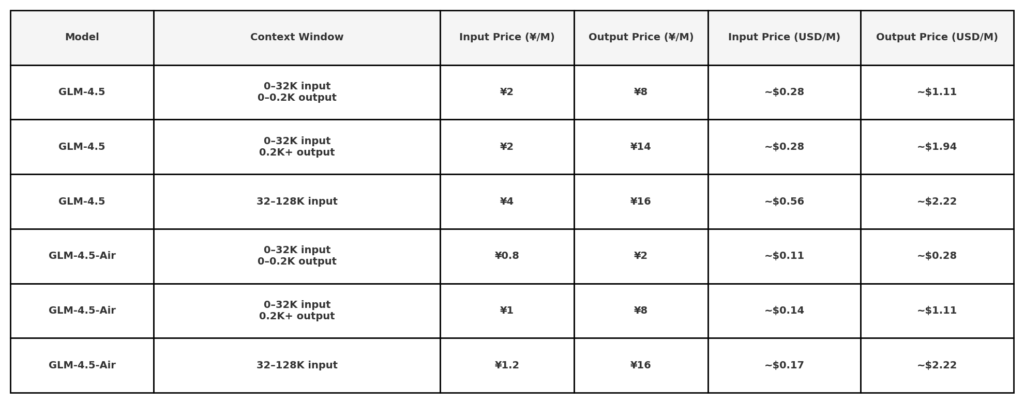
Bemærk: Meget lave priser ($0.11/$0.28) kan være begrænset til korte tokenlængder eller specifikke kampagner. 50% rabat på alle modeller i en begrænset periode, gyldig indtil 31. august 2025. Andre modeller, se prisside for kontor.
På CometAPI'en er serien bundtet med lidt forskellige niveauinddelte priser, se GLM-4.5 API:
| Model | indføre | Pris |
glm-4.5 | Vores mest kraftfulde ræsonnementsmodel med 355 milliarder parametre | Input-tokens $0.48 Output-tokens $1.92 |
glm-4.5-air | Omkostningseffektiv Letvægts Stærk Ydeevne | Input-tokens $0.16 Output-tokens $1.07 |
glm-4.5-x | Højtydende, stærk ræsonnement, ultrahurtig respons | Input-tokens $1.60 Output-tokens $6.40 |
glm-4.5-airx | Letvægts, stærk ydeevne, ultrahurtig respons | Input-tokens $0.02 Output-tokens $0.06 |
glm-4.5-flash | Stærk ydeevne Fremragende til ræsonnement, kodning og agenter | Input-tokens $3.20 Output-tokens $12.80 |
Hvordan er GLM 4.5-priserne sammenlignet med DeepSeek og Western LLM'er?
På verdenskonferencen for AI i 2025 positionerede Z.ai eksplicit GLM 4.5 som en udfordrer til DeepSeek – den tidligere omkostningsleder i Kina – og lovede "en brøkdel af token-omkostningerne" og halvdelen af hardware-fodaftrykket i forhold til DeepSeeks R1-model.
- DeepSeek R1Cirka 0.14 USD i input, 0.60 USD i output pr. million tokens.
- GLM 4.5: Påstået at underbyde DeepSeek med 20-30% på både input og output.
- Vestlige benchmarksOpenAIs GPT-4 og Googles Gemini koster mellem 3 og 15 USD pr. million tokens, hvilket positionerer GLM 4.5 som en betydelig omkostningsreduktion.
Denne prisstrategi afspejler Kinas bredere økonomiske model for AI: slankere beregningsevne, mindre modeller og aggressiv underbudspolitik for at vinde markedsandele.
Er GLM 4.5-serien det værd?
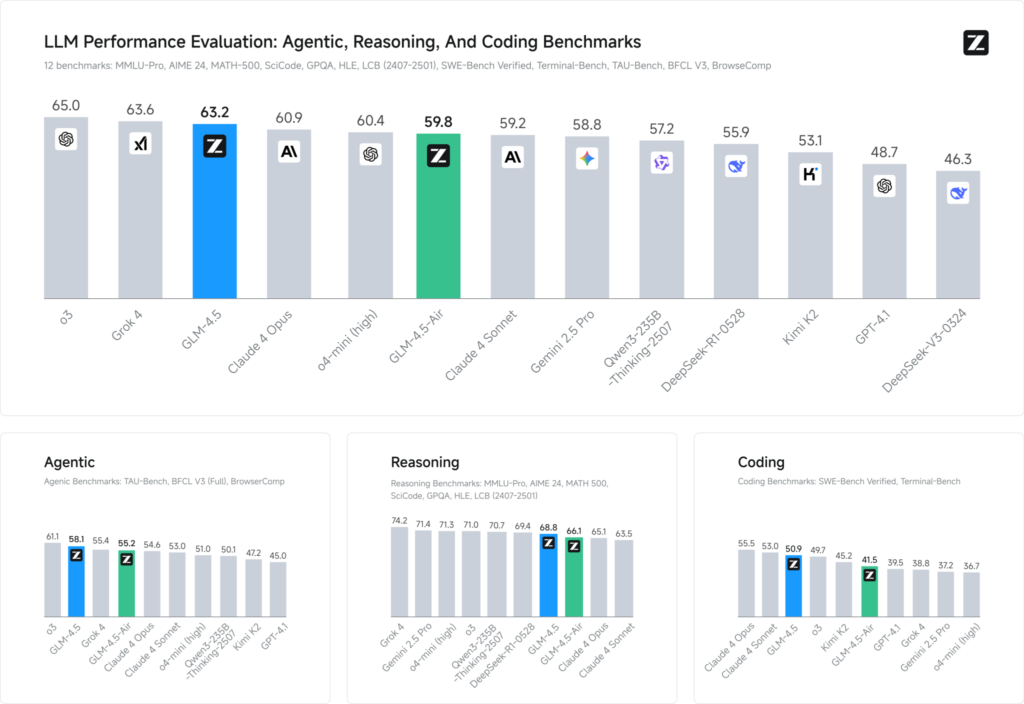
Benchmark-evalueringer på tværs af 12 repræsentative datasæt (spændende over MMLU Pro, MATH 500, SciCode, Terminal-Bench og TAU-Bench) afslører, at GLM 4.5 sikrer sig en global #3-placering efter xAI's Grok 4 og OpenAI's o3 – men alligevel rangerer som nummer 1 blandt open source-tilbud.
I kodningsopgaver (LiveCodeBench, SWE-Bench) bidrager GLM 4.5's Mixture-of-Experts-design til førsteklasses kodegenereringskvalitet, mens dens flertrinsplanlægning i ræsonnement (AIME 24, MMLU Pro) giver en robust nøjagtighed, der kan sammenlignes med closed source-modstykker. Den lette Air-variant opretholder konkurrencedygtige scorer inden for sin parametergruppe (100 B-skala), hvilket gør den til et fristende valg til edge-implementeringer og indlejrede systemer.
Performance benchmarks
- IntelligensindeksGLM 4.5-scorer 66 på et sammensat intelligensindeks (MMLU Pro, MATH 500, AIME 24), hvilket overgår mange open source- og kommercielle mellemklassemodeller.
- SlutningsforsinkelseGennemsnit af tid til første token 0.89 sekunder, konkurrencedygtig til komplekse ræsonnementopgaver, dog lidt langsommere i gennemløb (≈45.7 tokens/s) sammenlignet med nogle optimerede closed-source-modeller.
- Agent-arbejdsgangDemonstrerer robust beherskelse af flertrinsværktøjsbrug og dynamisk kodegenerering med direkte sejrsrater på ~54% mod Kimi K2 og 81% imod Qwen3‑Coder i uafhængige kodningsevalueringer.
Hvilke praktiske anvendelsesscenarier viser ROI?
- Full-Stack-udviklingGLM-4.5 kan scaffolde hele webapplikationer – fra frontend-layouts i HTML/CSS/JavaScript til backend-databaseskemaer – gennem multi-turn-prompts, hvilket reducerer prototypecyklusser fra dage til timer.
- Kompleks dokumentanalyseDet udvidede kontekstvindue på 128 K giver juridiske, finansielle og videnskabelige firmaer mulighed for at analysere flersidede kontrakter eller forskningsrapporter på én gang, hvilket reducerer segmenteringsomkostningerne.
- Automatiserede agentarbejdsgangeHybrid inferens tillader oprettelse af autonome scripts (f.eks. webscrapingbots, handelsagenter), der ræsonnerer gennem flertrinsprocesser med minimal menneskelig indgriben.
Kvantitative casestudier tyder på op til 60 procent reduktion af udviklertimer til kodecentrerede opgaver og 40 procent hurtigere ekspeditionstid ved analyse af langformatindhold.
Hvad er de potentielle ulemper og overvejelser?
Ingen teknologi er uden kompromiser. Potentielle brugere bør være opmærksomme på regulatoriske, operationelle og økosystemmæssige faktorer.
Begrænsninger
Support og SLA'erOpen source-udbydere tilbyder muligvis ikke SLA'er på virksomhedsniveau eller support døgnet rundt, i modsætning til kommercielle modparter.
GennemløbsbegrænsningerSelvom kontekstvinduet er enormt, halter token-per-sekund-hastighederne bagud i forhold til nogle inferensoptimerede closed source-modparter, hvilket potentielt påvirker realtidsapplikationer.
DriftsomkostningerSelvhostende MoE-modeller kræver omhyggelig orkestrering (ekspertrouting, hukommelsesstyring) for at undgå flaskehalse i ydeevnen og omkostningsoverskridelser.
Hvilke infrastrukturinvesteringer er nødvendige?
- Beregn fodaftryk: Selv med MoE-effektivitet kræver hosting af GLM-4.5's standardvariant GPU'er med ≥80 GB hukommelse og robuste NVLink-forbindelser til inferens med lav latenstid.
- Finjustering af overheadomkostninger: Tilpasning af modellen til domænespecifikke opgaver kan kræve betydelige GPU-cyklusser, hvilket øger de initiale omkostninger, før besparelserne på tokenfakturering realiseres.
- Vedligeholdelse: Implementeringer på stedet flytter ansvaret for opdateringer, sikkerhedsrettelser og skalering fra leverandøren til interne DevOps-teams.
Hvordan kan du komme i gang med GLM-4.5?
Det kræver et par enkle trin at starte en GLM-4.5-integration – især i betragtning af open source-strategien og den omfattende tredjepartssupport.
Hvilke API'er og platforme understøtter GLM-4.5?
- CometAPI APIFuldt OpenAI-kompatibelt slutpunkt med SDK'er i Python, JavaScript og Java.
- Direkte Z.ai-slutpunktTilbyder officiel support og tidlig adgang til funktioner såsom multi-agent-orkestrering.
- FællesskabsspejleHurtigt voksende mængde af open source-runtime-programmer (f.eks. Ollama, AutoGPT-CLI), der muliggør lokal inferens.
Hvor kan udviklere finde værktøjer og dokumentation?
- Z.ai officielle dokumenter: Omfattende vejledninger til installation, hurtig ingeniørarbejde og MoE-optimering.
- GitHub Repositories: Eksempelnotesbøger til kodegenerering, retrieval-augmented generation (RAG) og agentframeworks, der er kompatible med større orkestreringsværktøjer.
- Fællesskabsfora: Aktive diskussionsfora på platforme som Hugging Face, hvor praktikere deler finjusteringsopskrifter, promptbiblioteker og præstationsbenchmarks.
Konklusion
GLM-4.5-serien sætter en klar standard i dagens hyperkonkurrenceprægede AI-landskab: uovertruffen omkostningseffektivitet for både udviklere, virksomheder og forskningsinstitutioner. Med tokenpriser så lave som 0.11 USD pr. million input-tokens og 0.28 USD pr. million output – yderligere reduceret med en kampagnerabat på 50 procent – og en benchmark-ydeevne, der konkurrerer med eller overgår større proprietære modeller, leverer GLM-4.5 et betydeligt investeringsafkast for kodecentrerede applikationer, langsigtet forståelse og agentbaserede arbejdsgange.
Kom godt i gang
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere – såsom OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i en enkelt, udviklervenlig grænseflade. Ved at tilbyde ensartet godkendelse, formatering af anmodninger og svarhåndtering forenkler CometAPI dramatisk integrationen af AI-funktioner i dine applikationer. Uanset om du bygger chatbots, billedgeneratorer, musikkomponister eller datadrevne analysepipelines, giver CometAPI dig mulighed for at iterere hurtigere, kontrollere omkostninger og forblive leverandøruafhængig – alt imens du udnytter de seneste gennembrud på tværs af AI-økosystemet.
Udviklere kan få adgang GLM-4.5 Air API og GLM-4.5 API ved CometAPI, de seneste Claude Models-versioner, der er anført, er fra artiklens udgivelsesdato. For at begynde med, udforsk modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.