

At starte med Gemini 2.5 Flash-Lite via CometAPI er en spændende mulighed for at udnytte en af de mest omkostningseffektive generative AI-modeller med lav latenstid, der er tilgængelige i dag. Denne guide kombinerer de seneste annonceringer fra Google DeepMind, detaljerede specifikationer fra Vertex AI-dokumentationen og praktiske integrationstrin ved hjælp af CometAPI for at hjælpe dig med at komme hurtigt og effektivt i gang.
Hvad er Gemini 2.5 Flash-Lite, og hvorfor bør du overveje det?
Oversigt over Gemini 2.5-familien
I midten af juni 2025 udgav Google DeepMind officielt Gemini 2.5-serien, inklusive stabile GA-versioner af Gemini 2.5 Pro og Gemini 2.5 Flash, sammen med forhåndsvisningen af en helt ny, let model: Gemini 2.5 Flash-Lite. 2.5-serien er designet til at balancere hastighed, pris og ydeevne og repræsenterer Googles bestræbelser på at imødekomme et bredt spektrum af anvendelsesscenarier - fra tunge forskningsopgaver til store, omkostningsfølsomme implementeringer.
Nøgleegenskaber ved Flash-Lite
Flash-Lite adskiller sig ved at tilbyde multimodale funktioner (tekst, billeder, lyd, video) med ekstremt lav latenstid, med et kontekstvindue, der understøtter op til en million tokens og værktøjsintegrationer, herunder Google-søgning, kodeudførelse og funktionskald. Afgørende er det, at Flash-Lite introducerer "tankebudget"-kontrol, der giver udviklere mulighed for at afveje ræsonnementsdybde mod svartid og omkostninger ved at justere en intern tokenbudgetparameter.
Positionering i modelrækken
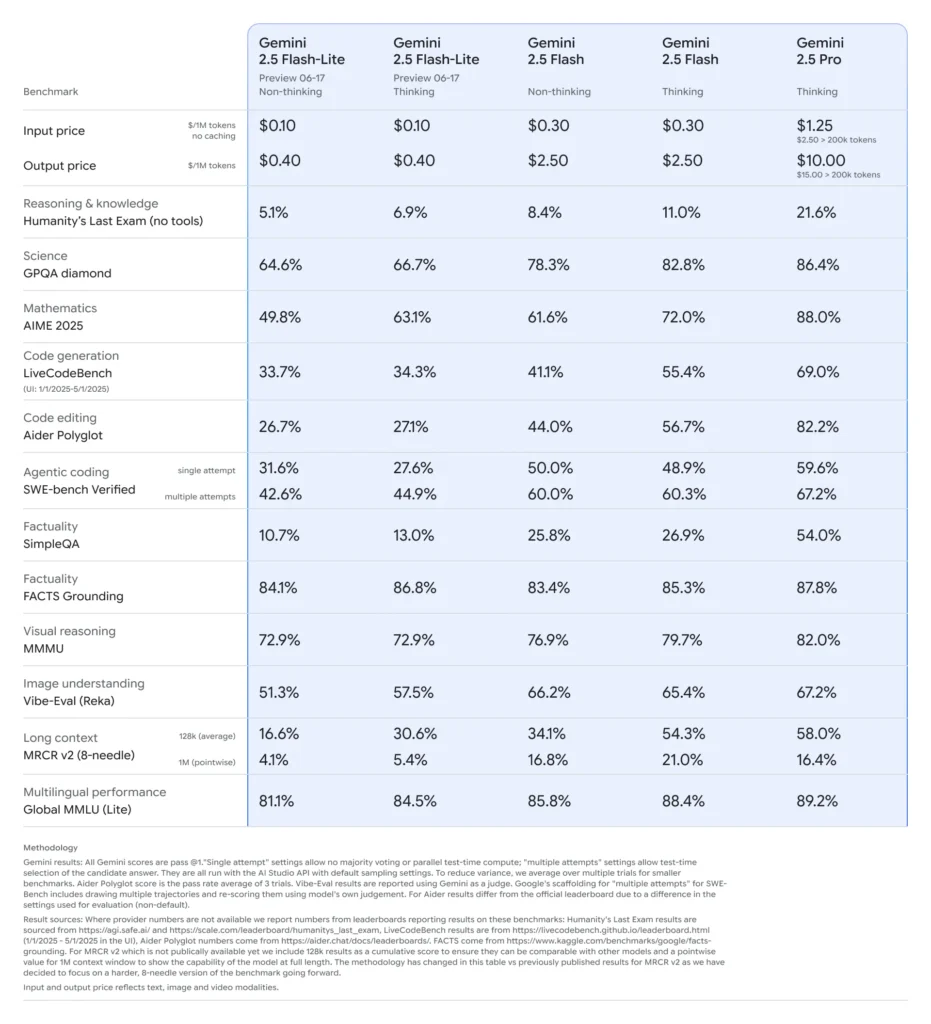
Sammenlignet med sine søskende befinder Flash-Lite sig på Paretos grænse for omkostningseffektivitet: Med en pris på cirka $0.10 pr. million input-tokens og $0.40 pr. million output-tokens under forhåndsvisningen undergraver den både Flash (til $0.30/$2.50) og Pro (til $1.25/$10), samtidig med at den bevarer det meste af deres multimodale dygtighed og understøttelse af funktionskald. Dette gør Flash-Lite ideel til opgaver med høj volumen og lav kompleksitet, såsom opsummering, klassificering og lette konversationsagenter.
Hvorfor bør udviklere overveje Gemini 2.5 Flash-Lite?
Ydelsesbenchmarks og tests i den virkelige verden
I direkte sammenligninger demonstrerede Flash-Lite:
- 2 gange hurtigere gennemløb end Gemini 2.5 Flash på klassifikationsopgaver.
- 3 gange omkostningsbesparelser til opsummeringspipelines på virksomhedsniveau.
- Konkurrencepræcision på benchmarks inden for logik, matematik og kode, der matcher eller overgår tidligere Flash-Lite-forhåndsvisninger.
Ideelle anvendelsesscenarier
- Chatbots med høj volumenLever ensartede samtaleoplevelser med lav latenstid på tværs af millioner af brugere.
- Automatiseret indholdsgenereringSkalér dokumentopsummering, oversættelse og oprettelse af mikrokopier.
- Søge- og anbefalingspipelinesUdnyt hurtig inferens til personalisering i realtid.
- BatchdatabehandlingAnnotér store datasæt med minimale beregningsomkostninger.
Hvordan får og administrerer man API-adgang til Gemini 2.5 Flash-Lite via CometAPI?
Hvorfor bruge CometAPI som din gateway?
CometAPI samler over 500 AI-modeller – inklusive Googles Gemini-serie – under et samlet REST-slutpunkt, hvilket forenkler godkendelse, hastighedsbegrænsning og fakturering på tværs af udbydere. I stedet for at jonglere med flere basis-URL'er og API-nøgler, peger du alle anmodninger til https://api.cometapi.com/v1, angiv målmodellen i nyttelasten og administrer brugen via et enkelt dashboard.
Forudsætninger og tilmelding
- Log ind på cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først
- Få adgangslegitimations-API-nøglen til grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.
- Hent url'en til dette websted: https://api.cometapi.com/
Administration af dine tokens og kvoter
CometAPIs dashboard leverer samlede token-kvoter, der kan deles på tværs af Google, OpenAI, Anthropic og andre modeller. Brug de indbyggede overvågningsværktøjer til at indstille brugsalarmer og hastighedsgrænser, så du aldrig overskrider budgetterede allokeringer eller pådrager dig uventede gebyrer.
Hvordan konfigurerer du dit udviklingsmiljø til CometAPI-integration?
Installation af nødvendige afhængigheder
Installer følgende pakker for Python-integration:
pip install openai requests pillow
- openaiKompatibelt SDK til kommunikation med CometAPI.
- anmodningerTil HTTP-handlinger såsom download af billeder.
- pude: Til billedhåndtering ved afsendelse af multimodale input.
Initialisering af CometAPI-klienten
Brug miljøvariabler til at holde din API-nøgle ude af kildekoden:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Denne klientinstans kan nu målrette mod enhver understøttet model ved at angive dens ID (f.eks. gemini-2.5-flash-lite-preview-06-17) i dine anmodninger.
Konfiguration af tankebudget og andre parametre
Når du sender en anmodning, kan du inkludere valgfrie parametre:
- temperatur/top_pKontroller tilfældigheden i genereringen.
- kandidatAntalAntal alternative udgange.
- max_tokensMaksimalt antal outputtokens.
- tankebudgetBrugerdefineret parameter til Flash-Lite for at afveje dybde for hastighed og pris.
Hvordan ser en grundlæggende anmodning til Gemini 2.5 Flash-Lite via CometAPI ud?
Eksempel med kun tekst
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Dette kald returnerer et kortfattet resumé på under 200 ms, ideelt til chatbots eller realtidsanalysepipelines.
Eksempel på multimodal input
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite behandler op til 7 MB billeder og returnerer kontekstuelle beskrivelser, hvilket gør det velegnet til dokumentforståelse, brugergrænsefladeanalyse og automatiseret rapportering.
Hvordan kan du udnytte avancerede funktioner som streaming og funktionskald?
Streaming af svar til realtidsapplikationer
Brug streaming-API'en til chatbot-grænseflader eller livetekstning:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Dette leverer delvise output, efterhånden som de bliver tilgængelige, hvilket reducerer den opfattede latenstid i interaktive brugergrænseflader.
Funktion, der kalder struktureret dataoutput
Definer JSON-skemaer for at håndhæve strukturerede svar:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Denne tilgang garanterer JSON-kompatible output, hvilket forenkler downstream-datapipelines og integrationer.
Hvordan optimerer man ydeevne, omkostninger og pålidelighed, når man bruger Gemini 2.5 Flash-Lite?
Tanke om budgetjustering
Flash-Lites tankebudgetparameter giver dig mulighed for at indstille mængden af "kognitiv indsats", som modellen bruger. Et lavt budget (f.eks. 0) prioriterer hastighed og omkostninger, mens højere værdier giver dybere ræsonnement på bekostning af latenstid og tokens.
Administration af tokengrænser og troughput
- Indtast tokensOp til 1,048,576 tokens pr. anmodning.
- Output tokensStandardgrænse på 65,536 tokens.
- Multimodale inputOp til 500 MB på tværs af billed-, lyd- og videomateriale.
Implementer klientsidet batching til store arbejdsbelastninger, og udnyt CometAPI's automatiske skalering til at håndtere burst-trafik uden manuel indgriben.
Omkostningseffektivitetsstrategier
- Saml lavkomplekse opgaver på Flash-Lite, mens du reserverer Pro- eller standard Flash til mere krævende opgaver.
- Brug prisgrænser og budgetadvarsler i CometAPI-dashboardet for at forhindre uoverskuelige udgifter.
- Overvåg brugen efter model-ID for at sammenligne omkostninger pr. anmodning og juster din routinglogik i overensstemmelse hermed.
Hvad er bedste praksis og de næste skridt efter den første integration?
Overvågning, logning og sikkerhed
- LogningIndfang metadata for anmodninger/svar (tidsstempler, latenser, tokenbrug) til performancerevisioner.
- AdvarslerOpsæt tærskelnotifikationer for fejlrater eller omkostningsoverskridelser i CometAPI.
- SikkerhedRoter API-nøgler regelmæssigt, og gem dem i sikre vaults eller miljøvariabler.
Almindelige brugsmønstre
- chatbotsBrug Flash-Lite til hurtige brugerforespørgsler og brug Pro til komplekse opfølgninger.
- DokumentbehandlingBatchanalyser af PDF'er eller billeder natten over med et lavere budget.
- RealtidsanalyserStream finansielle eller operationelle data for øjeblikkelig indsigt via streaming-API'en.
Undersøger nærmere
- Eksperimentér med hybride prompts: kombiner tekst- og billedinput for at få en mere omfattende kontekst.
- Prototype RAG (Retrieval-Augmented Generation) ved at integrere vektorsøgeværktøjer med Gemini 2.5 Flash-Lite.
- Sammenlign med konkurrenters tilbud (f.eks. GPT-4.1, Claude Sonnet 4) for at validere afvejninger mellem omkostninger og ydeevne.
Skalering i produktionen
- Udnyt CometAPIs virksomhedsniveau til dedikerede kvotepuljer og SLA-garantier.
- Implementer blågrønne implementeringsstrategier for at teste nye prompts eller budgetter uden at forstyrre live-brugere.
- Gennemgå regelmæssigt modelbrugsmålinger for at identificere muligheder for yderligere omkostningsbesparelser eller kvalitetsforbedringer.
Kom godt i gang
CometAPI leverer en samlet REST-grænseflade, der samler hundredvis af AI-modeller – under et ensartet slutpunkt med indbygget API-nøglestyring, brugskvoter og faktureringsdashboards. I stedet for at jonglere med flere leverandør-URL'er og legitimationsoplysninger.
Udviklere kan få adgang Gemini 2.5 Flash-Lite (forhåndsvisning) API(Model: gemini-2.5-flash-lite-preview-06-17) Gennem CometAPI, de nyeste modeller, der er anført, er fra artiklens udgivelsesdato. For at begynde, skal du udforske modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Med blot et par trin kan du integrere Gemini 2.5 Flash-Lite via CometAPI i dine applikationer og dermed opnå en kraftfuld kombination af hastighed, overkommelighed og multimodal intelligens. Ved at følge ovenstående retningslinjer – der dækker opsætning, grundlæggende anmodninger, avancerede funktioner og optimering – vil du være godt positioneret til at levere næste generations AI-oplevelser til dine brugere. Fremtiden for omkostningseffektiv AI med høj kapacitet er her: kom i gang med Gemini 2.5 Flash-Lite i dag.