

Anthropics Claude Opus 4.6 kom i februar 2026 som et klart, formålsbygget skub mod agentbaserede løsninger i enterprise-klassen, vidensarbejde med lang kontekst og stærkere autonom kodning. Udgivelsen blander ambitiøs ingeniørkunst (en beta-tilstand med en kontekst på én million tokens, en “adaptiv tænkning”-kapabilitet og agentteam-funktioner) med en pragmatisk kommerciel beslutning: Anthropic holdt API-prissætningen på linje med sine tidligere Opus-familie-modeller. Den kombination — materielt forbedrede kapabiliteter uden et øjeblikkeligt prishop — er overskriften.
Hvad er Claude Opus 4.6 helt præcist?
Claude Opus 4.6 er Anthropics flagskib i Opus-linjen: en storstilet, enterprise-fokuseret generativ AI-model optimeret til agentbaserede arbejdsgange, kodning og vidensarbejde med lang horisont. Anthropic positionerer Opus 4.6 som deres mest intelligente model til at bygge agenter og automatiseringer — noget der ikke blot er designet til at besvare forespørgsler, men til at planlægge, kalde værktøjer, koordinere underagenter og følge opgaver i flere trin på tværs af store kodebaser og dokumentkorpora.
I modsætning til forbrugerorienterede chatbots sigter Opus 4.6 mod enterprise-integrationer: den er tilgængelig gennem Anthropics claude.ai UI, Claude API og via CometAPI. Opus 4.6’s styrke ligger i agentbaserede kodningsopgaver og kald af værktøjer. For virksomheder betyder dette, at Opus 4.6 er positioneret som en drop-in-opgradering til agentassistenter, værktøjer til kode-migrering, pipelines til dokumentgennemgang og analytiske arbejdsgange, der behøver bredere kontekst end typiske chat-sessioner giver.
Dybdegående analyse af nye nøglefunktioner i Opus 4.6
Kontekst på én million tokens (og praktiske tilstande)
Opus 4.6 understøtter et udvidet standard-kontekstvindue (annonceret som 200K tokens med et kontekstvindue på 1M tokens tilgængeligt i beta). Et vindue på en million tokens er transformerende på papiret: det gør det muligt for modellen at rumme hele koderepositorier, lange juridiske skrivelser, flerårige e-mailarkiver eller store datatabeller i én samtale, hvilket reducerer behovet for ekstern hentningslogik. Anthropic parrer det rå kontekstvindue med værktøjer til “kontekstkomprimering”, der hjælper med at komprimere relevant information og reducere tokenomkostninger. Kort sagt: Opus kan reelt arbejde med meget store artefakter uden at skære dem i fragmenter, hvilket forenkler opbygning af langlivede agenter.
Hvorfor det er vigtigt: til koderefaktorering, juridisk/finansiel gennemgang eller forskningsprojekter, der kræver ræsonnement på tværs af dokumenter, reducerer det større vindue ingeniøroverhead (færre hentninger, mindre tilstandsmanagement) og forbedrer sammenhængen over meget lange ræsonnementskæder.
Adaptiv tænkning og udvidede styringer for ræsonnement
Opus 4.6 introducerer det, Anthropic kalder “adaptiv tænkning” (en udvikling af selskabets tidligere ideer om “extended thinking”). Det er både en intern kapabilitet og en API-kontrol: udviklere kan justere modellens “indsatsniveauer” og planlægningsdybde, så den kan bruge mere compute på kompliceret planlægning eller holde svar korte og hurtige til trivielle opgaver.
Hvorfor det er vigtigt: i agentbaserede arbejdsgange akkumuleres marginale kvalitetsforbedringer: bedre planlægning + koordinering betyder færre menneskelige rettelser og mere pålidelig autonom eksekvering.
Hvad er “agent teams” og agentbaseret orkestrering?
Opus 4.6 introducerer forbedret understøttelse af agentbaserede arbejdsgange: evnen til at oprette, koordinere og supervisere flere underagenter, der deler og løser opgaver. Anthropics materialer (og tidlige partnerberetninger) understreger, at Opus proaktivt kan skabe underagenter, tildele delopgaver, overvåge deres fremskridt og afslutte eller skifte strategi efter behov — effektivt agerende som en letvægtsorkestrator til komplekst, flertrins ingeniør- eller analysearbejde. Denne tætte integration mellem planlægning, værktøjsbrug og fejlkorrigering er et kerneargument for teams med tung automatisering.
API- og værktøjsforbedringer til virksomheds-integration
Anthropic har udvidet API-kontroller for komprimering, persistens og kald af værktøjer. Modellen understøtter større outputgrænser (Anthropic angiver op til 128K output-tokens), finere semantik for hentning og enterprise-integrationer til Microsoft 365 og udviklermiljøer. Den praktiske konsekvens er mindre “glue code”, når Opus kobles til regneark, præsentationer og interne toolchains. Anthropic har integreret Opus 4.6 i højere lag-værktøjer som Claude Cowork (no-code-grænseflader) og opdateringer til Claude Code, der lader ikke-tekniske brugere få adgang til automatisering.
Hvordan klarer Opus 4.6 sig på benchmarks?
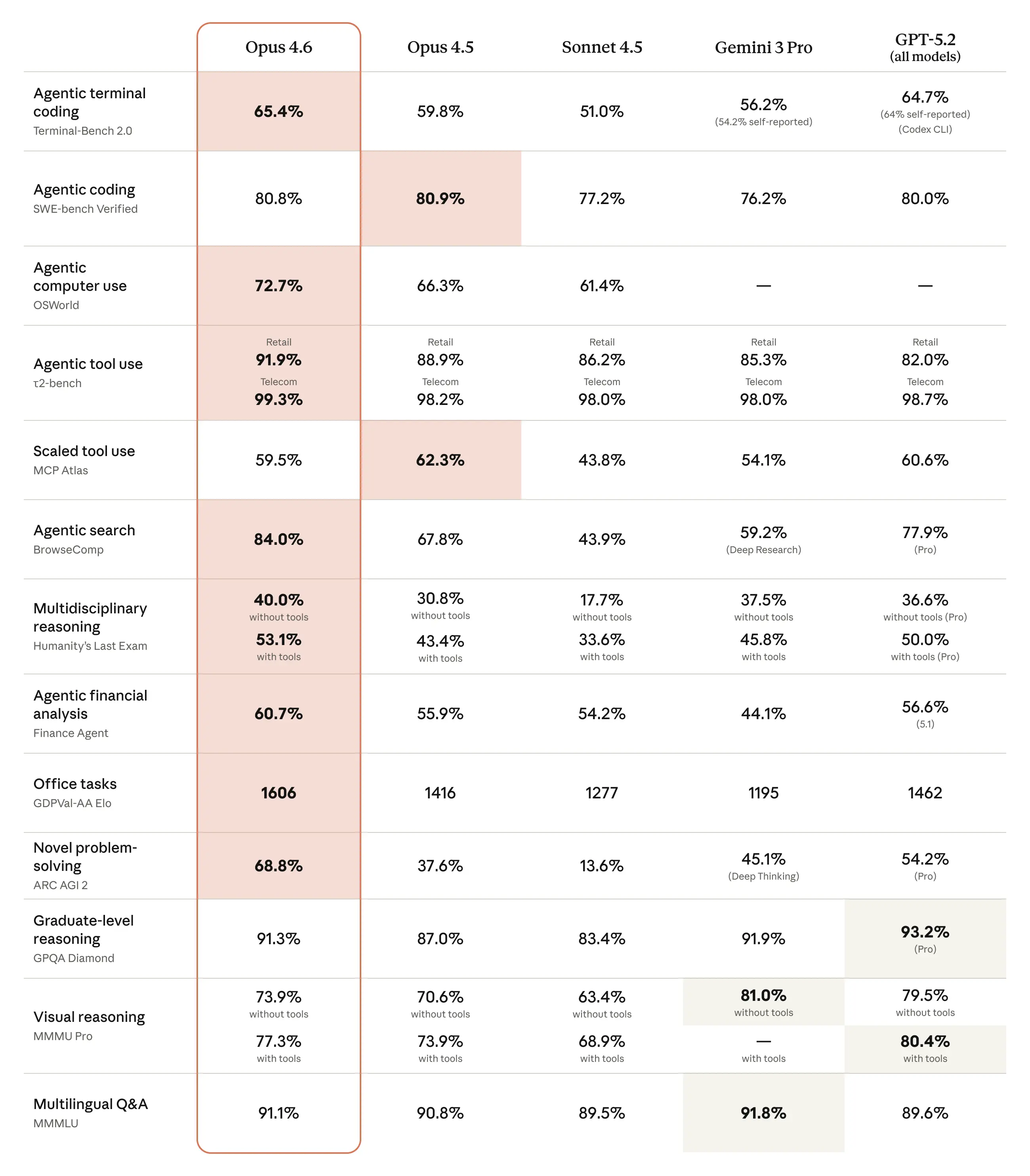
Opus 4.6 forbedrer resultaterne i forhold til Opus 4.5 og viser konkurrencedygtige placeringer mod nyere modeller fra OpenAI og Google på en blanding af kodning, ræsonnement og domænespecifikke test-suiter. Eksempler nævnt i korte træk:
- BigLaw Bench: Opus 4.6 nåede ~90.2% på Anthropics BigLaw Bench (juridisk ræsonnement).
- Terminal-Bench 2.0 / GDPval-metrikker: uafhængig dækning opremser Terminal-Bench 2.0-score og GDPval-AA Elo-vurderinger, der placerer Opus 4.6 foran Opus 4.5 og konkurrencedygtig med nogle nyere udgivelser fra rivaler. En rapport listede en Terminal-Bench 2.0-score på 65.4% og GDPval-AA Elo ~1,606.
Anthropic rapporterer store gevinster i agentbaserede kodningsopgaver med bedre planlægning, færre iterationer og stærkere performance på enorme kodebaser — inklusive påstande om at planlægge og gennemføre migreringer på repos med flere millioner linjer på kortere tid. Modellens forbedrede evne til at “fange egne” fejl og opretholde ræsonnement over mange trin fremhæves.
Hvad koster Opus 4.6?
Kort svar — pr.-token-priser
- Standard (prompter ≤ 200K tokens): $5 / 1M input tokens og $25 / 1M output tokens.
- Store prompter (prompter > 200K tokens): $10 / 1M input og $37.50 / 1M output.
- Hurtig tilstand (forskningsforhåndsvisning): et premium-niveau — $30 / 1M input og $150 / 1M output (hurtigere inferens).
Praktiske omkostningshensyn:
- Agentbaserede arbejdsgange har tendens til at være token-dyre. Flertrins planlægning, værktøjskald og lange outputs øger output-tokens; omhyggelig brug af komprimering og cache-læsninger er vigtig for at styre faktureringen.
- Batching sparer penge. Hvis din arbejdsbelastning passer til asynkron batch-behandling, kan Anthropics batch-API-priser reducere pr.-token-omkostningerne væsentligt.
- Premium-kontekst er dyrere. Hvis du ofte bruger 1M-token-betaen, bør du planlægge højere pr.-token-gebyrer. Mange organisationer vil blande tilstande: store kontekster kun hvor absolut nødvendigt og slanke sessioner andre steder.
Leder du efter billigere løsninger til at bruge Claude API
CometAPI er et godt valg. Opus 4.6 API kommer også fra Anthropic, men dets API-priser er 20% af den officielle pris, og dette ændrer sig ikke med ændringer i kontekstlængde.
Hvordan står Opus 4.6 i forhold til GPT-5.3 og Google Gemini 3?
Opus 4.6 vs. OpenAI’s GPT-5.3
OpenAIs nyere GPT-5.3 (brandet i OpenAIs “Codex”-linje til kodnings-/agentopgaver) er eksplicit tunet til dyb kodning og agentlignende arbejdsgange og hævder branchens bedste score på flere ingeniørbenchmarks (SWE-Bench Pro, Terminal-Bench). Tidlige omtaler antyder, at GPT-5.3-Codex skubber state of the art på softwareingeniør-benchmarks og agentisk planlægning, hvilket positionerer den som Opus 4.6’s tætteste direkte rival i rene kodnings- og agentopgaver. Opus 4.6 — i kontrast — fremhæver ekstremt lang kontekst og multi-agent orkestrering som differentieringspunkter. Kort sagt: GPT-5.3 ser ud til at være optimeret til rå ingeniørdybde og benchmark-dominans på udviklercentriske tests; Opus 4.6 betoner bredde på tværs af langkontekstuelle virksomhedsarbejdsgange og domænespecifikt ræsonnement.
Opus 4.6 vs Google Gemini 3?
Googles Gemini 3 (og Gemini 3 Pro / Deep Think-varianter) er blevet fremhævet for stærk performance i abstrakt ræsonnement, visuel problemløsning og visse videnskabelige QA-benchmarks; den har også flyttet avanceret multimodalt ræsonnement videre end sine forgængere. Dækning positionerer Gemini 3 som særligt stærk på videnskabelige og visuelle ræsonnement-suiter, mens Opus 4.6’s styrke ligger i langkontekstuel kode og juridisk/enterprise-arbejde. For organisationer, der har brug for multimodalt videnskabeligt ræsonnement eller avancerede visuelle-logiske opgaver, kan Gemini 3 have en fordel; til vedvarende vidensarbejde med lang kontekst og multi-agent-automatisering markerer Opus 4.6 sig.
Hvem “vinder” i direkte sammenligninger?
Ingen enkelt leverandør “vinder” universelt: valget afhænger af den arbejdsgang, du prioriterer. Tidlige uafhængige sammenligninger viser, at Opus 4.6 overgår Opus 4.5 med en meningsfuld margin på langhorisont- og domæneopgaver, mens GPT-5.3 og Gemini 3 bevarer fordele i visse kodnings- og multimodale testmiljøer. Som med enhver hurtigt udviklende generation er vinderen den kunde, der matcher modellernes styrker til virkelige arbejdsbelastninger og værktøjsintegration — ikke modellen med den højeste enkelt-benchmark.
Er Claude Opus 4.6 det værd?
Kort svar: Ja — hvis dine primære problemer er ræsonnement med lang kontekst, autonome agentarbejdsgange eller enterprise-compliance. Opus 4.6’s styrker er reelle og relevante: 200K- (og beta-1M-)vinduer, adaptiv tænkning, agentteams og enterprise-integrationer er håndgribelige opgraderinger, der reducerer produkt-ingeniørkompleksitet og udvider klassen af problemer, du kan automatisere.
Hvis din arbejdsbelastning derimod overvejende er korte, stærkt repetitive mikrOpgaver, hvor stykomkostning og latenstid er altafgørende, kan Opus 4.6 være overkill sammenlignet med en specialiseret model med kort horisont (f.eks. GPT-5.3 Codex) — medmindre du planlægger at kombinere dem og route opgaverne passende.
CometAPI er en alt-i-én aggregationsplatform for store model-API’er, der tilbyder problemfri integration og styring af API-tjenester. Den understøtter kald af forskellige mainstream-AI-modeller. Dette omfatter billedgenerering, videoproduktion, chat, TTS og STT — alt på én platform.
Du kan også vælge den model, du ønsker, baseret på dine omkostninger og modelkapabiliteter, og skifte mellem dem når som helst, såsom Gemini 3 Flash, GPT 5.3 eller Opus 4.6. Før du får adgang, skal du sikre, at du er logget ind på CometAPI og har fået API-nøglen. CometAPI tilbyder en pris, der er langt under den officielle pris, for at hjælpe dig med at integrere.
Ready to Go?→ Tilmeld dig for at kode i dag !
Hvis du vil have flere tips, vejledninger og nyheder om AI, så følg os på VK, X og Discord!