

Kling O1 – udgivet som en del af Kling AIs "Omni"-lanceringsuge – positionerer sig selv som en enkelt, samlet multimodal videofundamentsmodel, der accepterer tekst, billeder og videoer i samme anmodning og både kan generere og redigere video i iterative arbejdsgange på instruktørniveau. Klings team betegner O1 som "verdens første samlede multimodale videomodel i stor skala". Klings interne tests hævder betydelige sejre i forhold til Googles Veo 3.1 og Runway Aleph.
Hvad er Kling O1?
Kling O1 (ofte markedsført som Video O1 or Omni One) er en nyligt udgivet videofundamentsmodel fra Kling AI, der forener generering og redigering på tværs af tekst, billeder og video i et enkelt, promptdrevet framework. I stedet for at behandle tekst-til-video, billede-til-video og videoredigering som separate pipelines, accepterer Kling O1 blandede input (tekst + flere billeder + valgfri referencevideo) i en enkelt prompt, ræsonnerer over dem og producerer sammenhængende korte klip eller redigerer eksisterende optagelser med finmasket kontrol. Virksomheden positionerede udrulningen som en del af en "Omni Launch" og beskriver O1 som en "multimodal videomotor" bygget op omkring et Multimodal Visual Language (MVL)-paradigme og en Chain-of-Thought (CoT) ræsonnementsvej til at fortolke komplekse, flerdelte kreative instruktioner.
Klings budskaber lægger vægt på tre praktiske arbejdsgange: (1) tekst → videogenerering, (2) billede/element → video (komposition og udskiftning af motiv/rekvisit ved hjælp af eksplicitte referencer) og (3) videoredigering/optagelsesfortsættelse (restyling, tilføj/fjern objekt, start-frame/slut-frame-kontrol). Modellen understøtter flerelementprompts (inklusive en "@"-syntaks til at målrette bestemte referencebilleder) og har instruktørlignende kontroller såsom start/slut-frame-forankring og videofortsættelse til at opbygge flerskudssekvenser.
5 kernehøjdepunkter ved Kling O1
1) Ægte samlet multimodal input (MVL)
Kling O1's flagskibsfunktion er at behandle tekst, stillbilleder (flere referencer) og video som førsteklasses, samtidige input. Brugere kan levere flere referencebilleder (eller et kort referenceklip). og en instruktion i naturligt sprog; modellen vil analysere alle input sammen for at producere eller redigere et sammenhængende output. Dette reducerer friktion mellem værktøjskæden og muliggør arbejdsgange som "brug emne fra @image1, placer dem i miljøet fra @image2, match bevægelse til ref_video.mp4, og anvende filmisk farvegrad X.” Denne “Multimodale visuelle sprog” (MVL)-framing er kernen i Klings præsentation.
Hvorfor det er vigtigt: Ægte kreative arbejdsgange kræver ofte en kombination af referencer: en karakter fra ét element, en kamerabevægelse fra et andet og en narrativ instruktion i tekst. En forening af disse input muliggør generering i én omgang og færre manuelle kompositionstrin.
2) Redigering + generering i én model (multi-elements mode)
De fleste tidligere systemer adskilte generering (tekst→video) fra billedpræcis redigering. O1 kombinerer dem bevidst: den samme model, der opretter et klip fra bunden, kan også redigere eksisterende optagelser – bytte om på objekter, restyle tøj, fjerne rekvisitter eller forlænge et optagelse – alt sammen via instruktioner i naturligt sprog. Denne konvergens er en væsentlig forenkling af arbejdsgangen for produktionsteams.
O1-modellen opnår dyb integration af flere videoopgaver i sin kerne:
- Tekst-til-video-generering
- Generering af billed-/emnereference
- Videoredigering og inpainting
- Video-restyle
- Næste/Forrige optagelsesgenerering
- Nøglebilledbegrænset videogenerering
Den største betydning af dette design ligger i: Komplekse processer, der tidligere krævede flere modeller eller uafhængige værktøjer, kan nu udføres i en enkelt motor. Dette reducerer ikke kun oprettelses- og beregningsomkostningerne betydeligt, men lægger også grundlaget for udviklingen af en "samlet model til forståelse og generering af video".
3) Sammenhængen i videogenerering
Identitetskonsistens: O1-modellen forbedrer mulighederne for tværmodal konsistensmodellering og opretholder stabiliteten af referenceobjektets struktur, materiale, belysning og stil under genereringsprocessen:
- Den understøtter referencebilleder fra flere visninger til motivmodellering;
- den understøtter ensartethed i motivet på tværs af forskellige optagelser (karakter-, objekt- og scenefunktioner forbliver kontinuerlige på tværs af forskellige optagelser);
- Den understøtter hybride referencer til flere motiver, hvilket muliggør generering af gruppeportrætter og interaktiv scenekonstruktion.
Denne mekanisme forbedrer kohærensen og "identitetskonsistensen" af videogenerering betydeligt, hvilket gør den velegnet til scenarier med ekstremt høje krav til konsistens, såsom reklamer og generering af optagelser på filmniveau.
Forbedret hukommelse: O1-modellen har også "hukommelse", der forhindrer dens outputstil i at blive ustabil på grund af lange kontekster eller skiftende instruktioner. Den kan endda:
- husk flere tegn samtidigt;
- tillade forskellige karakterer at interagere i videoen;
- opretholde ensartethed i stil, påklædning og kropsholdning.
4) Præcis komposition med "@"-syntaks og start-/slutrammekontrol
Kling introducerede en sammensat forkortelse (rapporteret som et "@"-omtalesystem), så du kan referere til specifikke billeder i prompten (f.eks. @image1, @image2) for at tildele roller til aktiver pålideligt. Kombineret med eksplicit Start + End frame-specifikation muliggør dette kontrol på instruktørniveau over, hvordan elementer overgår, bevæger sig eller ændrer form på tværs af det genererede klip - et produktionsfokuseret funktionssæt, der adskiller O1 fra mange forbrugerorienterede generatorer.
5) Hi-fi, lange output og multitask-stacking
Kling O1 rapporteres at producere filmisk 1080p output (30fps), og – med tidligere Kling-versioner, der sætter scenen – fremhæver virksomheden generering af længere klip (rapporteret op til 2 minutter i de seneste produktbeskrivelser). Den understøtter også at stable flere kreative opgaver i en enkelt anmodning (generering, tilføjelse af et emne, ændring af belysning og redigering af komposition). Disse egenskaber gør den konkurrencedygtig med de mere avancerede tekst→video-motorer.
Hvorfor det er vigtigt: Længere klip i høj kvalitet og muligheden for at kombinere redigeringer reducerer behovet for at sammensætte mange korte klip og forenkler produktionen fra start til slut.
Hvordan er Kling O1 opbygget, og hvad er de underliggende mekanismer?
O1 omkring en Multimodalt visuelt sprog (MVL) kerne: en model, der lærer fælles indlejringer for sprog + billeder + bevægelsessignaler (videobilleder og optiske flow-lignende funktioner), og derefter anvender diffusions- eller transformerbaserede dekodere til at syntetisere tidsmæssigt kohærente billeder. Modellen beskrives som udførende condition på flere referencer (tekst; en-til-mange-billeder; korte videoklip) for at producere en latent videorepræsentation, som derefter afkodes til billeder pr. billedramme, samtidig med at den tidsmæssige konsistens bevares via opmærksomhed på tværs af billeder eller specialiserede tidsmæssige moduler.
1. Multimodal transformer + lang kontekstarkitektur
O1-modellen anvender Kelings egenudviklede multimodale Transformer-arkitektur, der integrerer tekst-, billed- og videosignaler og understøtter lang tidsmæssig konteksthukommelse (Multimodal Long Context).
Dette gør det muligt for modellen at forstå tidsmæssig kontinuitet og rumlig konsistens under videogenerering.
2. MVL: Multimodalt visuelt sprog
MVL er den centrale innovation i denne arkitektur.
Den justerer sproglige og visuelle signaler dybt i Transformeren gennem et samlet semantisk mellemlag, hvorved:
- Tillader et enkelt inputfelt at blande multimodale instruktioner;
- Forbedring af modellens præcise forståelse af beskrivelser i naturligt sprog;
- Understøtter meget fleksibel generering af interaktive videoer.
Introduktionen af MVL markerer et skift i videogenerering fra "tekstdrevet" til "semantisk-visuel samdrevet".
3. Tankekæde-inferensmekanisme
O1-modellen introducerer en "tankekæde"-inferenssti i videogenereringsfasen.
Denne mekanisme gør det muligt for modellen at udføre hændelseslogik og timingdeduktion før generering, og dermed opretholde en naturlig forbindelse mellem handlinger og begivenheder i videoen.
Inferens- og redigeringspipelines
- Generation: feed: (tekst + valgfrie billedreferencer + valgfrie videoreferencer + genereringsindstillinger) → model producerer latente videobilleder → afkoder til billeder → valgfri farve-/tidsmæssig efterbehandling.
- Instruktionsbaseret redigering: feed: (original video + tekstinstruktion + valgfri billedreferencer) → modellen knytter internt den ønskede redigering til et sæt pixel-space-transformationer og syntetiserer derefter redigerede billeder, mens uændret indhold bevares. Fordi alt er i én model, bruges de samme konditionerings- og tidsmoduler til både oprettelse og redigering.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
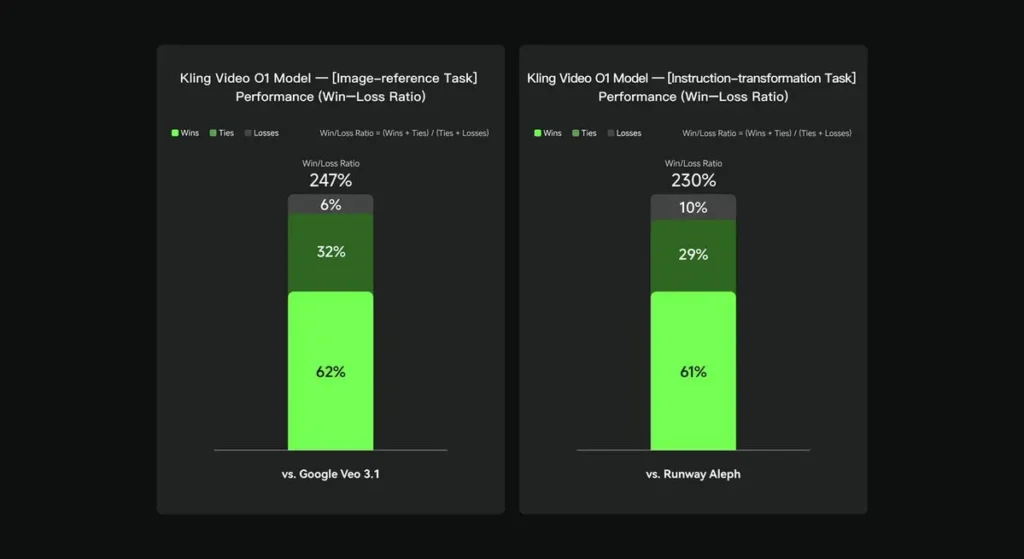
I interne evalueringer overgik Keling Video O1 betydeligt eksisterende internationale modparter på flere nøgledimensioner. Performanceresultater (baseret på Keling AI's selvbyggede evalueringssæt):
- Opgave "Billedreference": O1 klarer sig bedre end Google Veo 3.1 samlet set med en sejrsrate på 247%;
- Opgave “Instruktionstransformation”: O1 klarer sig bedre end Runway Aleph med en sejrsrate på 230%.
Konkurrentoverblik (sammenligning på funktionsniveau)
| Evne / Model | Kling O1 | Google Veo 3.1 | Landingsbane (Aleph / Gen-4.5) |
|---|---|---|---|
| Ensartet multimodal prompt (tekst + billeder + video) | **Ja (vigtigste salgsargument)**multimodale strømme med én anmodning. | Delvis — tekst→video + referencer findes; mindre vægt på én samlet MVL. | Runway fokuserer på generation + redigering, men ofte som separate tilstande; den seneste Gen-4.5 mindsker kløften. |
| Konversationsbaserede/tekstbaserede pixelredigeringer | Ja — “rediger som en samtale” (ingen masker). | Delvis — redigering findes, men maske-/nøglebillede-arbejdsgange er stadig almindelige. | Runway har stærke redigeringsværktøjer; Runway hævder stærke instruktionstransformationer (varierer fra udgivelse til udgivelse). |
| Start-/slutbilledkontrol og kamerareference | Ja — eksplicitte start-/slutbillede- og referencekamerabevægelser beskrevet. | Begrænset / i udvikling | Landingsbane: forbedret styring; ikke præcis samme brugeroplevelse. |
| Generering af lange klip (high fidelity) | op til ~2 minutter (1080p, 30fps) i produktmaterialer og fællesskabsindlæg; | Veo 3.1: stærk kohærens, men tidligere versioner havde kortere standardindstillinger; varierer med model/indstilling. | Runway Gen-4.5: sigter mod høj kvalitet; længde/troværdighed varierer. |
konklusion:
Kling O1's offentlige krav på berømmelse er arbejdsgangsforening: giver en enkelt model mandat til at forstå tekst, billeder og video og til at udføre både generering og omfattende instruktionsbaseret redigering inden for det samme semantiske system. For skabere og teams, der ofte bevæger sig mellem trinene "opret", "rediger" og "udvid", kan denne konsolidering dramatisk forenkle iterationshastighed og værktøjskompleksitet. Forbedret tidsmæssig konsistens, start/slut-rammekontrol og pragmatiske platformintegrationer, der gør den tilgængelig for skabere.
Kling Video o1 API'en vil snart være tilgængelig på CometAPI.
Udviklere kan få adgang Kling 2.5 Turb og Veo 3.1 API ved CometAPI, de nyeste modeller, der er anført, er fra artiklens udgivelsesdato. For at begynde, skal du udforske modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!