

Den 17. juni blev Shanghai AI-enhjørningen MiniMax officielt tilgængelig som open source MiniMax-M1, verdens første åbne, storskala hybridopmærksomhedsinferensmodel. Ved at kombinere en Mixture-of-Experts (MoE)-arkitektur med den nye Lightning Attention-mekanisme leverer MiniMax-M1 store gevinster inden for inferenshastighed, håndtering af ultralang kontekst og ydeevne af komplekse opgaver.
Baggrund og evolution
Bygger på fundamentet af MiniMax-Tekst-01, som introducerede lynnedslag i et Mixture-of-Experts (MoE) framework for at opnå 1 million token-kontekster under træning og op til 4 millioner tokens ved inferens, repræsenterer MiniMax-M1 den næste generation af MiniMax-01-serien. Forgængermodellen, MiniMax-Text-01, indeholdt 456 milliarder parametre i alt med 45.9 milliarder aktiverede pr. token, hvilket demonstrerer en ydeevne på niveau med top-LLM'er, samtidig med at kontekstfunktionerne blev udvidet betydeligt.
Nøglefunktioner ved MiniMax-M1
- Hybrid MoE + Lightning AttentionMiniMax-M1 kombinerer et sparsomt Mixture-of-Experts-design – 456 milliarder parametre i alt, men kun 45.9 milliarder aktiverede pr. token – med Lightning Attention, en lineær kompleksitetsopmærksomhed optimeret til meget lange sekvenser.
- Ultralang kontekst: Understøtter op til 1 millioner inputtokens – cirka otte gange grænsen på 128 K for DeepSeek-R1 – hvilket muliggør dyb forståelse af massive dokumenter.
- Overlegen effektivitetNår der genereres 100 tokens, kræver MiniMax-M1's Lightning Attention kun ~25-30% af den beregning, der bruges af DeepSeek-R1.
Modelvarianter
- MiniMax‑M1‑40K1 M token-kontekst, 40 K token-inferensbudget
- MiniMax‑M1‑80K1 M token-kontekst, 80 K token-inferensbudget
I scenarier med brug af TAU-bænkværktøj overgik 40K-varianten alle modeller med åben vægt – inklusive Gemini 2.5 Pro – og demonstrerede dermed dens agentfunktioner.
Træningsomkostninger og opsætning
MiniMax-M1 blev trænet fra start til slut ved hjælp af storstilet reinforcement learning (RL) på tværs af en bred vifte af opgaver – fra avanceret matematisk ræsonnement til sandkassebaserede softwareudviklingsmiljøer. En ny algoritme, CISPO (Clipped Importance Sampling for Policy Optimization) forbedrer yderligere træningseffektiviteten ved at klippe vigtighedssamplingvægte i stedet for opdateringer på tokenniveau. Denne tilgang, kombineret med modellens lynhurtige opmærksomhed, gjorde det muligt at gennemføre fuld RL-træning på 512 H800 GPU'er på bare tre uger til en samlet lejepris på 534,700 dollars.
Tilgængelighed og prisfastsættelse
MiniMax-M1 er udgivet under Apache 2.0 open source-licens og er umiddelbart tilgængelig via:
- GitHub repository, herunder modelvægte, træningsscripts og evalueringsbenchmarks.
- SiliconCloud hosting, der tilbyder to varianter — 40 K-token (“M1-40K”) og 80 K-token (“M1-80K”) — med planer om at aktivere hele 1 M-token-tragten.
- Prisen er i øjeblikket fastsat til 4 ¥ pr. million tokens til input og 16 ¥ pr. million tokens til output, med mængderabatter tilgængelige for virksomhedskunder.
Udviklere og organisationer kan integrere MiniMax-M1 via standard API'er, finjustere domænespecifikke data eller implementere lokalt til følsomme arbejdsbelastninger.
Ydeevne på opgaveniveau
| Opgavekategori | Fremhæv | Relativ ydeevne |
|---|---|---|
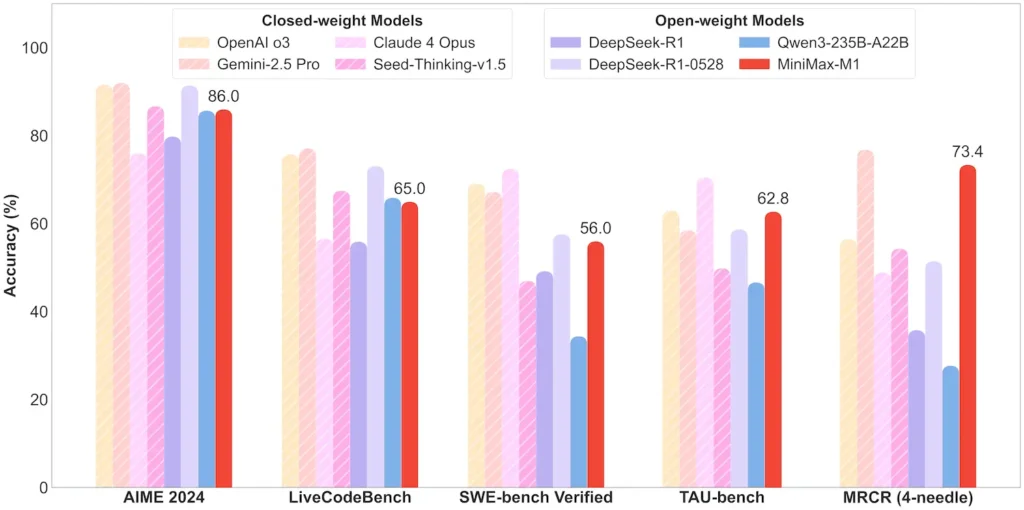
| Matematik og logik | AIME 2024: 86.0% | > Qwen 3, DeepSeek-R1; næsten lukket kildekode |
| Lang kontekstforståelse | Lineal (4 K–1 M brikker): Stabil topklasse | Overgår GPT-4 ud over en tokenlængde på 128 K |
| Software Engineering | SWE-bench (rigtige GitHub-fejl): 56% | Bedst blandt åbne modeller; næst førende lukkede |
| Brug af agent og værktøj | TAU-bench (API-simulering) | 62–63.5 % vs. Gemini 2.5, Claude 4 |
| Dialog og assistent | Multiudfordring: 44.7% | Matcher Claude 4, DeepSeek-R1 |
| Fakta QA | SimpleQA: 18.5% | Område til fremtidig forbedring |
Bemærk: Procenter og benchmarks fra officielle MiniMax-oplysninger og uafhængige nyhedsrapporter
Tekniske innovationer
- Hybrid opmærksomhedsstak: Lyn opmærksomhed lag (lineær omkostning) interleaved med periodisk Softmax Attention (kvadratisk, men mere udtryksfuld) for at balancere effektivitet og modelleringskraft.
- Sparsom MoE-routing32 ekspertmoduler; hver token aktiverer kun ~10% af de samlede parametre, hvilket reducerer inferensomkostningerne og samtidig bevarer kapaciteten.
- CISPO ForstærkningslæringEn ny "Clipped IS-weight Policy Optimization"-algoritme, der bevarer sjældne, men afgørende tokens i læringssignalet, hvilket accelererer RL-stabilitet og -hastighed.
MiniMax-M1's åbne udgivelse åbner op for ultralang kontekst, højeffektiv inferens for alle – og bygger bro mellem forskning og implementeringsbar storskala AI.
Kom godt i gang
CometAPI leverer en samlet REST-grænseflade, der samler hundredvis af AI-modeller – inklusive ChatGPT-familien – under et ensartet slutpunkt med indbygget API-nøglestyring, brugskvoter og faktureringsdashboards. I stedet for at jonglere med flere leverandør-URL'er og legitimationsoplysninger.
Til at begynde med, udforsk modellernes muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen.
Den seneste integration med MiniMax-M1 API vil snart blive vist på CometAPI, så følg med! Mens vi færdiggør upload af MiniMax-M1-modellen, kan du udforske vores andre modeller på Modeller side eller prøv dem i AI LegepladsMiniMax' seneste model i CometAPI er Minimax ABAB7-Preview API og MiniMax Video-01 API ,se til:
