GLM-4.6 er den seneste store udgivelse i Z.ai’s (tidligere Zhipu AI) GLM-familie: en 4. generation, stor-sproglig MoE (Mixture-of-Experts) model optimeret til agentbaserede arbejdsgange, lang-kontekst ræsonnering og praktisk kodning. Udgivelsen lægger vægt på praktisk agent-/værktøjsintegration, et meget stort kontekstvindue og tilgængelighed af åbne vægte til lokal udrulning.
Nøglefunktioner
- Lang kontekst — indbygget kontekstvindue på 200K tokens (udvidet fra 128K). (docs.z.ai)
- Kodning og agentbaserede kapaciteter — markedsførte forbedringer på kodningsopgaver i virkelige scenarier og bedre værktøjskald for agenter.
- Effektivitet — rapporteret ~30% lavere tokenforbrug end GLM-4.5 i Z.ai’s tests.
- Udrulning og kvantisering — først annonceret FP8- og Int4-integration for Cambricon-chips; indfødt FP8-understøttelse på Moore Threads via vLLM.
- Modelstørrelse og tensortype — offentliggjorte artefakter indikerer en ~357B-parameter model (BF16 / F32-tensorer) på Hugging Face.
Tekniske detaljer
Modaliteter og formater. GLM-4.6 er en kun tekst LLM (input- og outputmodaliteter: tekst). Kontekstlængde = 200K tokens; maks. output = 128K tokens.
Kvantisering og hardwareunderstøttelse. Teamet rapporterer FP8/Int4-kvantisering på Cambricon-chips og indfødt FP8-eksekvering på Moore Threads-GPU’er med vLLM til inferens — vigtigt for at sænke inferensomkostninger og muliggøre on-prem og indenlandske cloud-udrulninger.
Værktøjer og integrationer. GLM-4.6 distribueres via Z.ai’s API, tredjepartsleverandørnetværk (f.eks. CometAPI), og er integreret i kodningsagenter (Claude Code, Cline, Roo Code, Kilo Code).
Tekniske detaljer
Modaliteter og formater. GLM-4.6 er en kun tekst LLM (input- og outputmodaliteter: tekst). Kontekstlængde = 200K tokens; maks. output = 128K tokens.
Kvantisering og hardwareunderstøttelse. Teamet rapporterer FP8/Int4-kvantisering på Cambricon-chips og indfødt FP8-eksekvering på Moore Threads-GPU’er med vLLM til inferens — vigtigt for at sænke inferensomkostninger og muliggøre on-prem og indenlandske cloud-udrulninger.
Værktøjer og integrationer. GLM-4.6 distribueres via Z.ai’s API, tredjepartsleverandørnetværk (f.eks. CometAPI), og er integreret i kodningsagenter (Claude Code, Cline, Roo Code, Kilo Code).
Benchmark-ydeevne
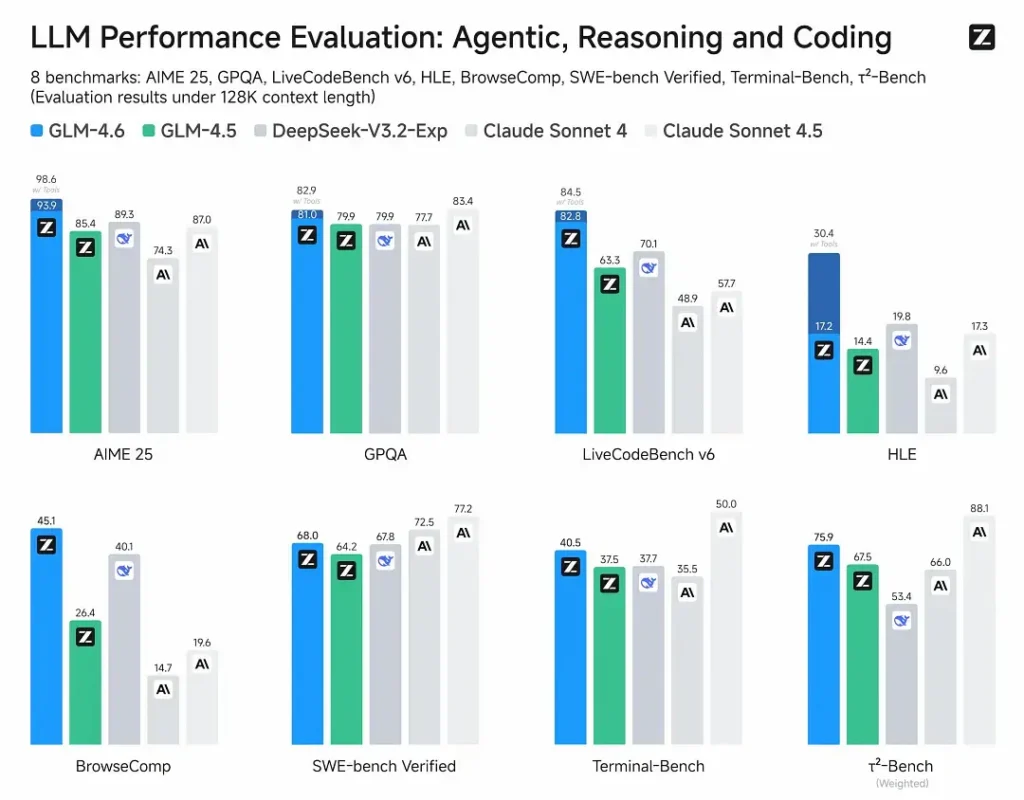
- Offentliggjorte evalueringer: GLM-4.6 blev testet på otte offentlige benchmarks, der dækker agenter, ræsonnering og kodning, og viser tydelige forbedringer over GLM-4.5. På menneskeevaluerede, virkelighedsnære kodningstests (udvidet CC-Bench) bruger GLM-4.6 ~15% færre tokens end GLM-4.5 og opnår en ~48.6% sejrsrate mod Anthropics Claude Sonnet 4 (næsten på niveau på mange ranglister).
- Positionering: resultaterne hævder, at GLM-4.6 er konkurrencedygtig med førende nationale og internationale modeller (eksempler omfatter DeepSeek-V3.1 og Claude Sonnet 4).
Begrænsninger og risici
- Hallucinationer og fejl: som alle nuværende LLM’er kan og vil GLM-4.6 lave faktuelle fejl — Z.ai’s dokumentation advarer eksplicit om, at outputs kan indeholde fejl. Brugere bør anvende verifikation og retrieval/RAG for kritisk indhold.
- Modelkompleksitet og driftsomkostninger: 200K kontekst og meget store outputs øger markant kravene til hukommelse og latenstid og kan hæve inferensomkostninger; kvantisering/inferens-ingeniørarbejde er nødvendigt for drift i skala.
- Domænegab: selv om GLM-4.6 rapporterer stærk agent-/kodningsperformance, påpeger nogle offentlige rapporter, at den stadig haleter efter visse versioner af konkurrerende modeller i specifikke mikrobenchmarks (f.eks. nogle kodningsmålinger vs Sonnet 4.5). Vurder pr. opgave før udskiftning af produktionsmodeller.
- Sikkerhed og politik: åbne vægte øger tilgængeligheden, men rejser også forvaltningsspørgsmål (afværgeforanstaltninger, guardrails og red-teaming er fortsat brugerens ansvar).
Anvendelsesområder
- Agentbaserede systemer og værktøjsorkestrering: lange agentspor, planlægning på tværs af flere værktøjer, dynamisk værktøjskald; modellens agentbaserede tuning er et centralt salgsargument.
- Kodningsassistenter til virkelige opgaver: multi-turn kodegenerering, kodegennemgang og interaktive IDE-assistenter (integreret i Claude Code, Cline, Roo Code—ifølge Z.ai). Forbedringer i tokeneffektivitet gør den attraktiv til udviklerplaner med høj brug.
- Arbejdsgange for lange dokumenter: opsummering, syntese på tværs af flere dokumenter, lange juridiske/tekniske gennemgange takket være 200K-vinduet.
- Indholdsskabelse og virtuelle karakterer: udvidede dialoger, konsistent opretholdelse af persona i multi-turn-scenarier.
Hvordan GLM-4.6 sammenlignes med andre modeller
- GLM-4.5 → GLM-4.6: markant løft i kontekststørrelse (128K → 200K) og tokeneffektivitet (~15% færre tokens på CC-Bench); forbedret agent-/værktøjsbrug.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai rapporterer næsten paritet på flere ranglister og en ~48.6% sejrsrate på CC-Benchs virkelige kodningsopgaver (dvs. tæt konkurrence, med nogle mikrobenchmarks hvor Sonnet stadig fører). For mange ingeniørteams er GLM-4.6 positioneret som et omkostningseffektivt alternativ.
- GLM-4.6 vs andre lang-kontekst-modeller (DeepSeek, Gemini-varianter, GPT-4-familien): GLM-4.6 fremhæver stor kontekst og agentbaserede kodningsarbejdsgange; relative styrker afhænger af metrik (tokeneffektivitet/agentintegration vs rå kode-syntesenøjagtighed eller sikkerhedspipelines). Empirisk udvælgelse bør være opgave-drevet.
Zhipu AI’s nyeste flagskibsmodel GLM-4.6 er udgivet: 355B samlede parametre, 32B aktive. Overgår GLM-4.5 i alle kernekapaciteter.
- Kodning: På niveau med Claude Sonnet 4, bedst i Kina.
- Kontekst: Udvidet til 200K (fra 128K).
- Ræsonnering: Forbedret, understøtter værktøjskald under inferens.
- Søgning: Forbedret værktøjskald og agentperformance.
- Skrivning: Bedre tilpasning til menneskelige præferencer i stil, læsbarhed og rollespil.
- Multisproglig: Forbedret oversættelse på tværs af sprog.