
OpenThinker-7B API er en state-of-the-art sprogmodel designet til komplekse naturlige sprogbehandlingsopgaver, der giver udviklere en robust grænseflade til at generere, forstå og interagere med tekstdata.
Teknisk beskrivelse
Kernen i OpenThinker-7B er en transformer-baseret arkitektur, som er blevet standarden for moderne sprogmodeller. Denne banebrydende model bygger på årtiers forskning i neurale netværk, specifikt fokuseret på at forbedre forståelsen af kontekst, semantik og syntaks i store datasæt. Med en optimeret foruddannet vidensbase afledt af forskellige korpora, udmærker OpenThinker-7B sig i at udføre en række opgaver såsom opsummering, besvarelse af spørgsmål, oversættelse og generering af indhold.
OpenThinker-7B inkorporerer flere avancerede teknikker der har rykket grænserne for tidligere naturlige sprogmodeller:
- Selvopmærksomhedsmekanisme: Modellen udnytter denne mekanisme til at fokusere på relevante dele af en sætning eller et afsnit, hvilket forbedrer dens forståelse af afhængigheder mellem ord.
- Fortræning med store datasæt: Ved at bruge en stor samling af forskelligartede tekster har OpenThinker-7B lært generelle sprogmønstre, som giver den evnen til at forstå nuancer, idiomer og komplekse sætningsstrukturer.
- Finjusteringsmuligheder: Modellen kan finjusteres til specifikke opgaver eller brancher, så den kan udmærke sig inden for specialiserede domæner såsom sundhedspleje, finans eller juridiske områder.
- Skalerbar infrastruktur: OpenThinker-7B's infrastruktur tillader implementering på cloud-baserede platforme, hvilket sikrer problemfri skalerbarhed og hurtig inferens til virksomhedsapplikationer.
API'et giver brugerne mulighed for at interagere med modellen gennem en brugervenlig grænseflade, som kan tilgås via standard REST API'er. Dette letter integrationen i eksisterende arbejdsgange, produkter og tjenester, hvilket gør det muligt for virksomheder at forbedre deres drift gennem avancerede AI-funktioner.
Evolution og udvikling
Udviklingen af OpenThinker-7B markerer en væsentlig milepæl i udviklingen af modeller for behandling af naturlige sprog. Efterhånden som AI-forskningen skred frem, fokuserede udviklere på at gøre modeller mere effektive og i stand til at forstå en bredere vifte af kontekster og sprog.
Tidlige stadier af OpenThinker
Oprindeligt var OpenThinkers sprogmodeller relativt små og krævede betydelig finjustering for at udføre specialiserede opgaver. Efterhånden som AI-teknologien udviklede sig, gjorde OpenThinker det også. Med hver iteration integrerede teamet flere data, brugte bedre fortræningsteknikker og forfinede de underliggende algoritmer.
Rejsen mod OpenThinker-7B begyndte specifikt med OpenThinker-2B, som var en mindre, mere eksperimenterende version. Det demonstrerede de grundlæggende muligheder for transformer-baserede arkitekturer, som blev forbedret med OpenThinker-5B. Hver udgivelse oplevede forbedringer i forståelsen af lang rækkevidde afhængigheder, multi-turn samtaler og dybere domænespecifik viden.
Skiftet til OpenThinker-7B repræsenterede en mere radikal afgang med betydelige opgraderinger i modellens skala, alsidighed og applikationsparathed i den virkelige verden. Integrationen af banebrydende finjusteringsteknikker og mere ekspansive datasæt gjorde det muligt for OpenThinker-7B at blive et alsidigt værktøj for udviklere, der arbejder på tværs af forskellige brancher.
Træningsproces og dataudnyttelse
OpenThinker-7B blev trænet vha milliarder af tokens fra et ekspansivt datasæt, som omfattede offentligt tilgængelige data samt proprietære datasæt fra partnerorganisationer. Datasættet omfattede en bred vifte af teksttyper, herunder:
- Bøger og artikler: Tilbyder stor generel viden
- Videnskabelige artikler: Bidrage med specialiseret, teknisk sprogforståelse
- Websider og indhold på sociale medier: Give opdaterede sprogmønstre og nutidige udtryk
- Dialoger og samtaledata: Gør det muligt for modellen at fungere godt i interaktive realtidsindstillinger
Træningsprocessen involverede at bruge distribuerede træningsteknikker, hvilket sikrer, at modellen kunne behandle dette enorme datasæt effektivt. Fremskridtene inden for modelparallelisme, træning med blandet præcision og optimeringsalgoritmer gjorde det muligt for OpenThinker-7B at opnå en imponerende ydeevne på trods af dens store skala.
Relaterede emner:De bedste 8 mest populære AI-modeller sammenligning af 2025
Fordele
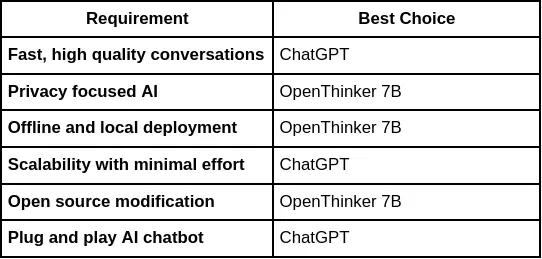
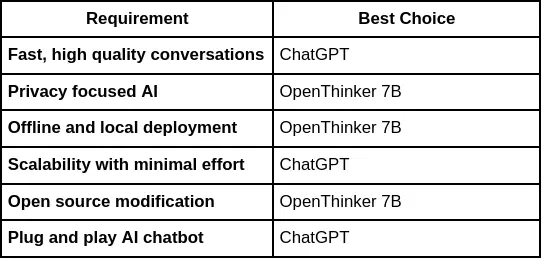
Der er flere bemærkelsesværdige fordele at udnytte OpenThinker-7B frem for andre sprogmodeller, især når det kommer til forretningsmæssige og tekniske applikationer.
1. Forbedret kontekstforståelse
OpenThinker-7B er designet til at forstå sprog på en meget dybere, mere nuanceret måde end sine forgængere. Ved at bruge selvopmærksomhedsmekanismer og transformer arkitektur, forstår modellen komplekse sætningsstrukturer, idiomatiske udtryk og langtrækkende afhængigheder i tekst. Denne evne til at forstå kontekst giver den mulighed for at give mere relevante og præcise svar i en bred vifte af applikationer.
2. Forbedret sproggenerering
tekstgenereringsmuligheder af OpenThinker-7B er væsentligt mere avancerede end tidligere modeller. Modellen kan generere tekst, der ikke kun er sammenhængende og kontekstuelt passende, men også yderst kreativ. Uanset om det drejer sig om at generere marketingkopier, udarbejde teknisk dokumentation eller producere fortællinger, udmærker OpenThinker-7B sig ved at opretholde høje kvalitetsniveauer på tværs af forskellige indholdstyper.
3. Finjusterende fleksibilitet
I modsætning til mange andre modeller, der ofte er begrænset til deres basistræning, tilbyder OpenThinker-7B fleksibiliteten til at blive finjusteret til specifikke opgaver. Det betyder, at virksomheder kan tilpasse modellen til at løse særlige udfordringer, såsom automatisering af kundeservice, opsummering af juridiske dokumenter eller teknisk fejlfinding. Finjustering giver OpenThinker-7B mulighed for at udføre specialiserede opgaver med et niveau af ekspertise, der er skræddersyet til branchens behov.
4. Skalerbarhed og hastighed
OpenThinker-7B er bygget til skalerbarhed, i stand til at håndtere store mængder af anmodninger og integreres i cloud-baserede infrastrukturer. Dens API kan bruges i en fordelt måde, hvilket sikrer, at anmodninger behandles i realtid med lav latenstid, hvilket gør den ideel til dynamiske miljøer, hvor hastighed og reaktionsevne er afgørende.
5. Bred sprogunderstøttelse
OpenThinker-7B tilbyder forbedret flersproget support, så virksomheder og udviklere kan skabe globaliserede applikationer. Med finjusteret ydeevne i over 50 sprog, kan OpenThinker-7B forstå og generere tekst på tværs af forskellige sproglige og kulturelle kontekster. Denne globale support giver virksomheder mulighed for at nå nye markeder og operere på tværs af internationale grænser problemfrit.
6. Robust problemløsning
OpenThinker-7B er trænet til at besvare spørgsmål, løse tekniske problemer og give indsigt på tværs af en bred vifte af emner. Modellen kan behandle komplekse forespørgsler, som f.eks teknisk fejlfinding, kunde support, eller endda generere løsninger til R&D teams. Dens evne til at integrere ekstern viden og generere løsninger baseret på omfattende data gør det til et stærkt værktøj til problemløsning på tværs af domæner.
Tekniske indikatorer
For bedre at forstå de tekniske muligheder i OpenThinker-7B er her nogle nøgler indikatorer der fremhæver dens imponerende præstation:
1. Parametertælling
OpenThinker-7B indeholder 7 milliarder parametre, hvilket gør det til en meget sofistikeret model, der skaber en balance mellem ydeevne og effektivitet. Denne skala giver den mulighed for at opretholde en høj grad af kontekstforståelse, mens den stadig er relativt let i forhold til større modeller som OpenAI's GPT-3.
2. Træningstid
Træning af OpenThinker-7B krævede betydelige beregningsressourcer, hvor modellen blev trænet over flere uger vha. højtydende GPU'er og distribuerede træningsteknikker. Træningsprocessen brugte adskillige petabytes af data, hvilket sikrede, at modellen havde eksponering for et bredt spektrum af sprog- og vidensdomæner.
3. Slutningsforsinkelse
Modellen er designet til hurtig inferens, med en typisk svartid på mindre end 200 ms pr. forespørgsel, selv under scenarier med høj efterspørgsel. Denne hurtige responstid gør OpenThinker-7B velegnet til realtidsapplikationer, såsom chatbots og virtuelle assistenter.
4. Nøjagtighed
OpenThinker-7B klarer sig usædvanligt godt på industristandard benchmarks til forskellige opgaver:
- LIM benchmark: 85 % nøjagtighed i naturlig sprogforståelse
- SQUAD: 90 % F1-score for besvarelse af spørgsmål
- Tekstgenereringskvalitet: Vurderet blandt de bedste i menneskelige evalueringer for sammenhæng og kreativitet
Disse benchmarks viser, at OpenThinker-7B præsterer på et konkurrencedygtigt niveau på tværs af flere use cases.
5. Energieffektivitet
Mens større modeller ofte lider af højt energiforbrug, blev OpenThinker-7B optimeret til energieffektivitet under både træning og konklusioner. Brugen af aritmetik med blandet præcision og energieffektiv hardware har gjort det muligt for OpenThinker-7B at reducere miljøpåvirkningen af AI-implementering markant.
Applikationer
OpenThinker-7B's alsidighed gør den anvendelig på tværs af adskillige domæner. Her er nogle af de mest bemærkelsesværdige applikationer for virksomheder, udviklere og indholdsskabere:
1. Kundesupport automatisering
En af de mest populære applikationer af OpenThinker-7B er i automatisere kundeservice. Med sin evne til at forstå og generere naturligt sprog kan modellen bruges til at drive intelligente virtuelle assistenter, der besvarer kundeforespørgsler, løser problemer og forbedrer den overordnede kundetilfredshed. Modellen kan finjusteres til at håndtere specifikke brancher, såsom telekommunikation, detailhandel eller bankvirksomhed, hvilket giver en personlig oplevelse for hver kunde.
2. Indholdsskabelse og markedsføring
OpenThinker-7B er velegnet til indholdsskabere og marketingfolk og tilbyder muligheden for at generere højkvalitetsartikler, produktbeskrivelser og annoncer. Ved at integrere det i marketing-workflows kan virksomheder strømline indholdsskabelse og sikre, at den genererede tekst er både engagerende og relevant for målgrupper.
3. Sundhedspleje og medicinske applikationer
I sundhedssektoren kan OpenThinker-7B bruges til at behandle og generere medicinsk dokumentation, yde klinisk beslutningsstøtte og hjælpe med fortolkning af medicinsk forskning. Med sin evne til at analysere komplekse medicinske tekster kan modellen hjælpe fagfolk med at holde sig ajour med de seneste fremskridt inden for lægevidenskaben.
4. Finansiel analyse og risikostyring
Finansielle institutioner drager fordel af OpenThinker-7B's evne til at analysere store mængder data, generere rapporter og hjælpe med risikostyring. Modellen kan behandle finansielle dokumenter, opsummere rapporter og generere indsigt, hvilket hjælper organisationer med at træffe datadrevne beslutninger hurtigere.
5. Uddannelse og læring
OpenThinker-7B er også et effektivt værktøj i uddannelsessektor. Det kan bruges til at skabe personlige læringsoplevelser, vejlede elever eller hjælpe lærere med at udvikle læseplanindhold. Derudover kan den besvare spørgsmål, generere praksiseksamener og hjælpe eleverne med at forstå komplekse begreber.
6. Jura og overholdelse
Advokatfirmaer og compliance-teams kan bruge OpenThinker-7B til hurtigt at analysere store mængder juridiske dokumenter, udtrække relevant information og opsummere nøgleresultater. Denne kapacitet forbedrer i høj grad effektiviteten i opgaver som kontraktgennemgang og overholdelse af lovgivning.
konklusion:
OpenThinker-7B repræsenterer et væsentligt skridt fremad i udviklingen af naturlig sprogbehandling. Ved at kombinere avanceret teknologi med et fleksibelt og effektivt design tilbyder OpenThinker-7B virksomheder, udviklere og forskere et avanceret værktøj til at tackle komplekse sprogopgaver. Dens overlegne ydeevne, skalerbarhed og evne til at blive finjusteret til specifikke brugstilfælde gør det til et værdifuldt aktiv for en lang række industrier. Efterhånden som modellen fortsætter med at udvikle sig, vil dens potentiale for at transformere industrier og forbedre arbejdsgange kun stige, hvilket placerer den som en nøglespiller i fremtiden for kunstig intelligens.
Sådan kalder du denne OpenThinker-7B API fra vores hjemmeside
1.Log på til cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først
2.Få adgangslegitimations-API-nøglen af grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.
-
Hent webadressen til dette websted: https://api.cometapi.com/
-
Vælg OpenThinker-7B-slutpunktet for at sende API-anmodningen og indstil anmodningens brødtekst. Anmodningsmetoden og anmodningsorganet er hentet fra vores hjemmeside API dok. Vores hjemmeside giver også Apifox-test for din bekvemmelighed.
-
Bearbejd API-svaret for at få det genererede svar. Efter at have sendt API-anmodningen, vil du modtage et JSON-objekt, der indeholder den genererede fuldførelse.