

I det hastigt udviklende landskab inden for kunstig intelligens har 2025 oplevet betydelige fremskridt inden for store sprogmodeller (LLM'er). Blandt frontløberne er Alibabas Qwen2.5, DeepSeeks V3- og R1-modeller og OpenAIs ChatGPT. Hver af disse modeller bringer unikke funktioner og innovationer til bordet. Denne artikel dykker ned i den seneste udvikling omkring Qwen2.5 og sammenligner dens funktioner og ydeevne med DeepSeek og ChatGPT for at bestemme, hvilken model der i øjeblikket fører AI-kapløbet.
Hvad er Qwen2.5?
Oversigt
Qwen 2.5 er Alibaba Clouds nyeste kompakte, dekoderbaserede sprogmodel, der fås i flere størrelser fra 0.5B til 72B parametre. Den er optimeret til instruktionsfølgende programmer, strukturerede output (f.eks. JSON, tabeller), kodning og matematisk problemløsning. Med understøttelse af over 29 sprog og en kontekstlængde på op til 128K tokens er Qwen2.5 designet til flersprogede og domænespecifikke applikationer.
Nøglefunktioner
- flersproget SupportUnderstøtter over 29 sprog og henvender sig til en global brugerbase.
- Udvidet kontekstlængdeHåndterer op til 128K tokens, hvilket muliggør behandling af lange dokumenter og samtaler.
- Specialiserede varianterInkluderer modeller som Qwen2.5-Coder til programmeringsopgaver og Qwen2.5-Math til matematisk problemløsning.
- TilgængelighedTilgængelig via platforme som Hugging Face, GitHub og en nyligt lanceret webgrænseflade på chat.qwenlm.ai.
Hvordan bruger man Qwen 2.5 lokalt?
Nedenfor er en trin-for-trin vejledning til 7 B Chat kontrolpunkt; større størrelser adskiller sig kun i GPU-krav.
1. Hardwarekrav
| Model | vRAM til 8-bit | vRAM til 4-bit (QLoRA) | Diskstørrelse |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Et enkelt RTX 4090 (24 GB) er tilstrækkeligt til 7 B-inferens med fuld 16-bit præcision; to sådanne kort eller CPU-offload plus kvantisering kan håndtere 14 B.
2. Installation
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Hurtig inferens script
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
trust_remote_code=True flag er påkrævet, fordi Qwen sender en specialfremstillet vare Roterende positionsindlejring indpakning.
4. Finjustering med LoRA
Takket være parametereffektive LoRA-adaptere kan du specialtræne Qwen på ~50 K domænepar (f.eks. medicinsk) på under fire timer på en enkelt 24 GB GPU:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Den resulterende adapterfil (~120 MB) kan flettes tilbage eller indlæses efter behov.
Valgfrit: Kør Qwen 2.5 som en API
CometAPI fungerer som et centraliseret knudepunkt for API'er af flere førende AI-modeller, hvilket eliminerer behovet for at engagere sig med flere API-udbydere separat. CometAPI tilbyder en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere Qwen API, og du får $1 på din konto efter registrering og login! Velkommen til at registrere dig og opleve CometAPI. For udviklere, der sigter mod at integrere Qwen 2.5 i applikationer:
Trin 1: Installer nødvendige biblioteker:
bash
pip install requests
Trin 2: Hent API-nøgle
- Naviger til CometAPI.
- Log ind med din CometAPI-konto.
- Vælg Hovedmenu.
- Klik på "Get API Key" og følg vejledningen for at generere din nøgle.
Trin 3: Implementer API-kald
Brug API-legitimationsoplysningerne til at sende anmodninger til Qwen 2.5. Erstat med din faktiske CometAPI-nøgle fra din konto.
For eksempel i Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Denne integration muliggør problemfri integration af Qwen 2.5's funktioner i forskellige applikationer, hvilket forbedrer funktionaliteten og brugeroplevelsen. Vælg “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” endpoint til at sende API-anmodningen og angive anmodningsteksten. Anmodningsmetoden og anmodningsteksten kan hentes fra vores hjemmesides API-dokumentation. Vores hjemmeside tilbyder også en Apifox-test for din bekvemmelighed.
Vær sød at henvise til Qwen 2.5 Max API for integrationsdetaljer.CometAPI har opdateret det seneste QwQ-32B API.For mere modeloplysninger i Comet API, se venligst API-dok.
Bedste praksis og tips
| Scenario | Anbefaling |
|---|---|
| Spørgsmål og svar i et langt dokument | Opdel passager i ≤16 tokens, og brug hentningsudvidede prompts i stedet for naive 100 kontekster for at reducere latenstid. |
| Strukturerede udgange | Sæt følgende præfiks foran systemmeddelelsen: You are an AI that strictly outputs JSON. Qwen 2.5's justeringstræning udmærker sig ved begrænset generering. |
| Kode afsluttet | sæt temperature=0.0 og top_p=1.0 for at maksimere determinismen, samples derefter flere stråler (num_return_sequences=4) for rangering. |
| Sikkerhedsfiltrering | Brug Alibabas open source-baserede "Qwen-Guardrails" regex-bundle eller OpenAIs text-moderation-004 som en første omgang. |
Kendte begrænsninger ved Qwen 2.5
- Hurtig injektionsmodtagelighed. Eksterne revisioner viser jailbreak-succesrater på 18 % på Qwen 2.5-VL – en påmindelse om, at modelstørrelse alene ikke immuniserer mod fjendtlige instruktioner.
- Ikke-latinsk OCR-støj. Når modellens end-to-end-pipeline finjusteres til vision-sproglige opgaver, forveksler den nogle gange traditionelle og forenklede kinesiske glyffer, hvilket kræver domænespecifikke korrektionslag.
- GPU-hukommelsesklippe ved 128 K. FlashAttention-2 forskyder RAM, men en 72 B tæt fremadrettet pass på tværs af 128 K tokens kræver stadig >120 GB vRAM; praktikere bør bruge WindowAttend eller KV-cache.
Køreplan og samfundsøkosystem
Qwen-holdet har antydet Qwen 3.0, der er rettet mod en hybrid routing-backbone (Dense + MoE) og samlet tale-syn-tekst-fortræning. I mellemtiden er økosystemet allerede vært for:
- Q-Agent – en ReAct-lignende tankekædeagent, der bruger Qwen 2.5‑14B som politik.
- Kinesisk finansiel alpaka – en LoRA på Qwen2.5‑7B trænet med 1 mio. regulatoriske indberetninger.
- Åbn Interpreter-plugin – bytter GPT-4 ud med et lokalt Qwen-checkpoint i VS Code.
Tjek siden "Qwen2.5-kollektionen" med Hugging Face for en løbende opdateret liste over kontrolpunkter, adaptere og evalueringsseler.
Sammenlignende analyse: Qwen2.5 vs. DeepSeek og ChatGPT
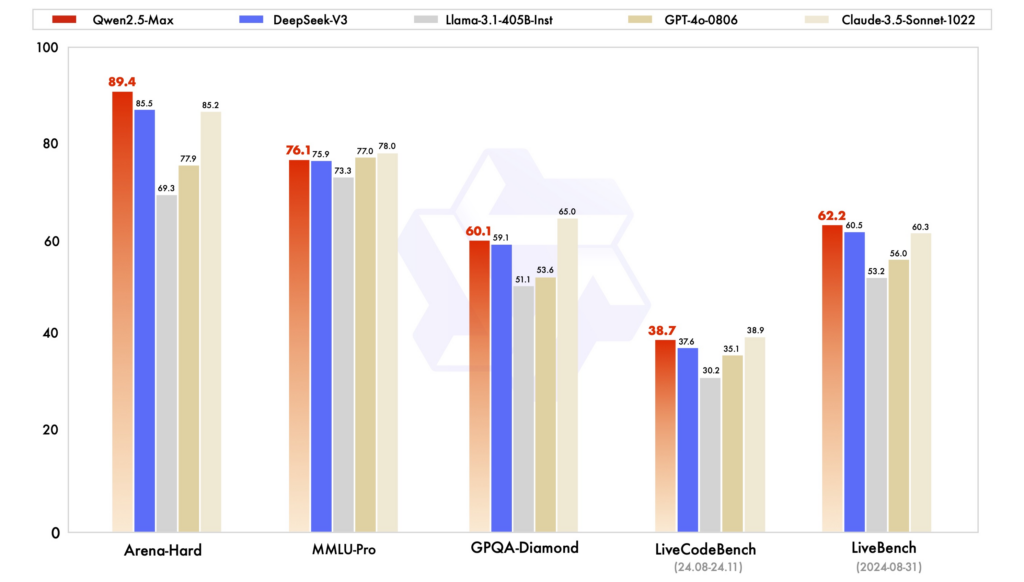
Ydeevne benchmarks: I forskellige evalueringer har Qwen2.5 vist stærk ydeevne i opgaver, der kræver ræsonnement, kodning og flersproget forståelse. DeepSeek-V3, med sin MoE-arkitektur, udmærker sig ved effektivitet og skalerbarhed og leverer høj ydeevne med reducerede beregningsressourcer. ChatGPT er fortsat en robust model, især i generelle sprogopgaver.
Effektivitet og omkostninger: DeepSeeks modeller er kendte for deres omkostningseffektive træning og inferens, idet de udnytter MoE-arkitekturer til kun at aktivere nødvendige parametre pr. token. Qwen2.5, selvom densitet, tilbyder specialiserede varianter for at optimere ydeevnen til specifikke opgaver. ChatGPTs træning involverede betydelige beregningsressourcer, hvilket afspejles i driftsomkostningerne.
Tilgængelighed og tilgængelighed af open source: Qwen2.5 og DeepSeek har i varierende grad omfavnet open source-principper, med modeller tilgængelige på platforme som GitHub og Hugging Face. Qwen2.5's nylige lancering af en webgrænseflade forbedrer dens tilgængelighed. ChatGPT, selvom det ikke er open source, er bredt tilgængeligt via OpenAI's platform og integrationer.
Konklusion
Qwen 2.5 ligger på et godt punkt mellem lukket vægt premium-tjenester og fuldt åbne hobbymodellerDens blanding af permissiv licensering, flersproget styrke, kompetence inden for lang kontekst og en bred vifte af parameterskalaer gør den til et overbevisende fundament for både forskning og produktion.
I takt med at open source LLM-landskabet haster fremad, demonstrerer Qwen-projektet det Gennemsigtighed og ydeevne kan sameksistereFor både udviklere, dataloger og beslutningstagere er det en investering i en mere pluralistisk og innovationsvenlig AI-fremtid at mestre Qwen 2.5 i dag.