

คเวน2.5-วีแอล-32บี API ได้รับความสนใจเป็นอย่างมาก ประสิทธิภาพที่โดดเด่น ในงานที่ซับซ้อนต่างๆ โดยผสมผสานทั้งสองอย่างเข้าด้วยกัน ข้อมูลภาพและข้อความ เพื่อความเข้าใจโลกที่สมบูรณ์ยิ่งขึ้น พัฒนาโดย อาลีบาบาโมเดลพารามิเตอร์ 32 พันล้านนี้เป็นการอัปเกรดจากรุ่นก่อนหน้า คเวน2.5-วีแอล ซีรี่ย์ที่ขยายขอบเขตออกไป การใช้เหตุผลที่ขับเคลื่อนโดย AI และ ความเข้าใจภาพ.

ภาพรวมของ Qwen2.5-VL-32B
Qwen2.5-VL-32B คือ โมเดลมัลติโหมดโอเพนซอร์สที่ล้ำสมัย ออกแบบมาเพื่อรองรับงานต่างๆ ที่เกี่ยวข้องกับทั้งข้อความและรูปภาพ ด้วย 32 พันล้านพารามิเตอร์มันมี สถาปัตยกรรมอันทรงพลัง สำหรับ การจดจำภาพ, การใช้เหตุผลทางคณิตศาสตร์, การสร้างบทสนทนาและอื่น ๆ อีกมากมาย ซึ่งได้รับการปรับปรุง ความสามารถในการเรียนรู้โดยอาศัยการเรียนรู้แบบเสริมแรง ช่วยให้สามารถสร้างคำตอบที่ตรงกับความต้องการของมนุษย์ได้ดีขึ้น
คุณสมบัติและหน้าที่หลัก
Qwen2.5-VL-32B แสดงให้เห็นถึงความสามารถอันโดดเด่นในหลายโดเมน:
ความเข้าใจและการอธิบายภาพ:รุ่นนี้มีความโดดเด่นในด้าน การวิเคราะห์ภาพระบุวัตถุและฉากได้อย่างแม่นยำ สามารถสร้างคำอธิบายภาษาธรรมชาติโดยละเอียดและแม้กระทั่งให้ ข้อมูลเชิงลึกที่ละเอียด เข้าสู่คุณสมบัติของวัตถุและความสัมพันธ์ของมัน
การใช้เหตุผลทางคณิตศาสตร์และตรรกะ:โมเดลนี้ออกแบบมาเพื่อแก้ไขปัญหาทางคณิตศาสตร์ที่ซับซ้อน ตั้งแต่ เรขาคณิตสู่พีชคณิต—โดยการจ้างงาน การใช้เหตุผลหลายขั้นตอน ด้วยตรรกะที่ชัดเจนและผลลัพธ์ที่มีโครงสร้าง
การสร้างข้อความและบทสนทนา:ด้วยโมเดลภาษาขั้นสูง Qwen2.5-VL-32B สร้างการตอบสนองที่สอดคล้องและเกี่ยวข้องกับบริบทโดยอิงตามข้อความหรือรูปภาพที่ป้อนเข้า นอกจากนี้ยังรองรับ บทสนทนาหลายรอบซึ่งช่วยให้การโต้ตอบเป็นไปอย่างเป็นธรรมชาติและต่อเนื่องมากยิ่งขึ้น
การตอบคำถามด้วยภาพ:นางแบบสามารถตอบคำถามที่เกี่ยวข้องกับเนื้อหาภาพได้ เช่น การรับรู้วัตถุ และ คำอธิบายฉากซึ่งให้ความสามารถในการอนุมานและตรรกะภาพที่ซับซ้อน
รากฐานทางเทคนิคของ Qwen2.5-VL-32B
หากต้องการทำความเข้าใจพลังเบื้องหลัง Qwen2.5-VL-32B จำเป็นต้องศึกษาหลักการทางเทคนิคของมัน ด้านล่างนี้คือประเด็นสำคัญที่ส่งผลต่อประสิทธิภาพ:
- การฝึกอบรมก่อนการทำงานหลายรูปแบบ:โมเดลได้รับการฝึกอบรมล่วงหน้าโดยใช้ ชุดข้อมูลขนาดใหญ่ ประกอบด้วยทั้ง ข้อมูลข้อความและภาพซึ่งจะทำให้สามารถเรียนรู้คุณลักษณะทางภาพและภาษาที่หลากหลาย ส่งผลให้เข้าใจข้ามโหมดได้อย่างราบรื่น
- สถาปัตยกรรมหม้อแปลงไฟฟ้า:สร้างขึ้นบนพื้นฐานความแข็งแกร่ง สถาปัตยกรรมหม้อแปลงไฟฟ้าแบบจำลองนี้ใช้ประโยชน์จากทั้งสอง encoder และ ถอดรหัส โครงสร้างในการประมวลผลอินพุตของภาพและข้อความ เพื่อสร้างเอาต์พุตที่มีความแม่นยำสูง กลไกการเอาใจใส่ตนเอง ช่วยให้สามารถเน้นไปที่ส่วนประกอบที่สำคัญภายในข้อมูลอินพุตได้ จึงเพิ่มความแม่นยำมากขึ้น
- การเพิ่มประสิทธิภาพการเรียนรู้การเสริมแรง:Qwen2.5-VL-32B ได้รับประโยชน์จากการเรียนรู้แบบเสริมแรง ซึ่งปรับแต่งตามข้อเสนอแนะของมนุษย์ กระบวนการนี้ช่วยให้มั่นใจว่าการตอบสนองของแบบจำลองจะดีขึ้น สอดคล้องกับความชอบของมนุษย์ ขณะเดียวกันก็เพิ่มประสิทธิภาพวัตถุประสงค์ต่างๆ เช่น ความถูกต้อง, ตรรกะและ ความคล่องแคล่ว.
- การจัดวางแนวภาษาและภาพ: ผ่าน การเรียนรู้ที่ตรงกันข้าม และกลยุทธ์การจัดตำแหน่ง แบบจำลองนี้รับประกันว่าทั้งสอง คุณสมบัติด้านภาพ และ ข้อมูลข้อความ ได้รับการบูรณาการอย่างเหมาะสมใน พื้นที่ภาษาทำให้มีประสิทธิภาพสูงสำหรับ งานหลายรูปแบบ.
ไฮไลท์ประสิทธิภาพ
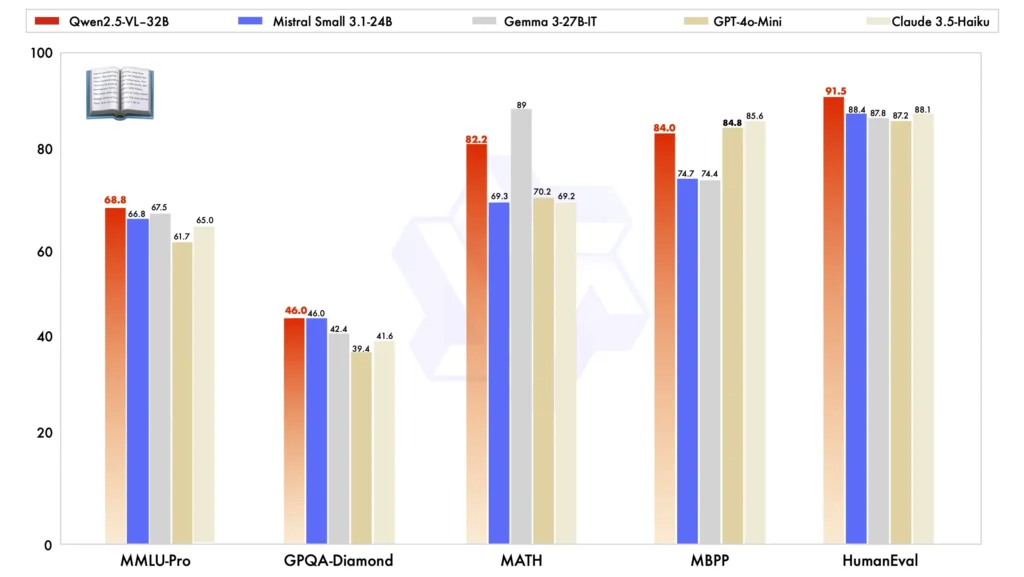
เมื่อเปรียบเทียบกับรุ่นขนาดใหญ่รุ่นอื่นๆ Qwen2.5-VL-32B โดดเด่นในเกณฑ์มาตรฐานสำคัญหลายประการ โดยแสดงให้เห็นถึง ประสิทธิภาพที่เหนือกว่า ทั้งคู่ หลายรูปแบบ และ งานข้อความธรรมดา:
เปรียบเทียบรุ่น:เทียบกับรุ่นอื่นเช่น มิสทรัล-เล็ก-3.1-24B และ เจมม่า-3-27บี-ไอทีQwen2.5-VL-32B แสดงให้เห็นถึงความสามารถที่ได้รับการปรับปรุงอย่างมีนัยสำคัญ โดยเฉพาะอย่างยิ่ง เหนือกว่า Qwen2-VL-72B ที่ใหญ่กว่า ในงานต่างๆ
การปฏิบัติงานตามภารกิจหลายรูปแบบ: อยู่ในคอมเพล็กซ์ งานหลายรูปแบบ เช่น มม, เอ็มเอ็มเอ็มยู-โปรและ คณิตวิสต้าQwen2.5-VL-32B โดดเด่นด้วยการให้ผลลัพธ์ที่แม่นยำ ซึ่งทำให้แตกต่างจากรุ่นอื่นที่มีขนาดใกล้เคียงกัน
MM-MT-Bench เกณฑ์มาตรฐาน:เมื่อเทียบกับรุ่นก่อนหน้า Qwen2-VL-72B-Instruct รุ่นใหม่นี้แสดงให้เห็นถึงการปรับปรุงที่สำคัญ โดยเฉพาะอย่างยิ่งใน เหตุผลเชิงตรรกะ และ การใช้เหตุผลหลายรูปแบบ ความสามารถในการ
ประสิทธิภาพของข้อความธรรมดา:ในงานที่ใช้ข้อความธรรมดา Qwen2.5-VL-32B ได้กลายมาเป็น นักแสดงชั้นนำ ในระดับเดียวกัน โดยเสนอ การสร้างข้อความที่ปรับปรุง, เหตุผลและความแม่นยำโดยรวม
ทรัพยากรโครงการ
สำหรับนักพัฒนาและผู้ที่ชื่นชอบ AI ที่ต้องการสำรวจ Qwen2.5-VL-32B เพิ่มเติม มีแหล่งข้อมูลสำคัญหลายประการที่พร้อมให้บริการ:
- เว็บไซต์อย่างเป็นทางการ: โครงการ Qwen2.5-VL-32B
- นางแบบกอดหน้า: HuggingFace Qwen2.5-VL-32B-คำสั่ง
แอปพลิเคชั่นในโลกแห่งความจริง
ความคล่องตัวของ Qwen2.5-VL-32B ทำให้เหมาะกับการใช้งานหลากหลาย การใช้งานจริง ครอบคลุมหลากหลายอุตสาหกรรม:
การบริการลูกค้าที่ชาญฉลาด:โมเดลนี้สามารถใช้งานเพื่อจัดการคำถามของลูกค้าโดยอัตโนมัติ โดยใช้ประโยชน์จากความสามารถในการทำความเข้าใจและสร้าง การตอบสนองแบบข้อความและแบบรูปภาพ.
ความช่วยเหลือด้านการศึกษา: โดยการแก้ปัญหา ปัญหาทางคณิตศาสตร์, ล่าม เนื้อหารูปภาพและการอธิบายแนวคิดสามารถช่วยเพิ่มกระบวนการเรียนรู้ของนักเรียนได้อย่างมาก
คำอธิบายประกอบรูปภาพ:ในระบบการจัดการเนื้อหา Qwen2.5-VL-32B สามารถสร้างแบบอัตโนมัติได้ คำบรรยายภาพ และ รายละเอียดทำให้เป็นเครื่องมืออันล้ำค่าสำหรับอุตสาหกรรมสื่อและสร้างสรรค์
การขับขี่อัตโนมัติ:โดยการวิเคราะห์ป้ายจราจรและสภาพการจราจรผ่านความสามารถในการประมวลผลภาพ โมเดลสามารถให้ข้อมูลเชิงลึกแบบเรียลไทม์เพื่อปรับปรุง ความปลอดภัยในการขับขี่.
การสร้างเนื้อหา:ในสื่อและโฆษณาโมเดลสามารถสร้างได้ ข้อความ โดยอาศัยสิ่งเร้าทางภาพ ช่วยให้ผู้สร้างเนื้อหาสามารถผลิตเรื่องราวที่น่าสนใจสำหรับวิดีโอและโฆษณาได้
อนาคตและความท้าทาย
แม้ว่า Qwen2.5-VL-32B จะเป็นก้าวกระโดดในด้าน AI หลายโหมด แต่ยังคงมีความท้าทายและโอกาสอยู่ข้างหน้า ปรับจูน แบบจำลองสำหรับงานที่เฉพาะเจาะจงมากขึ้น โดยบูรณาการกับแอปพลิเคชันแบบเรียลไทม์ และปรับปรุง scalability การจัดการชุดข้อมูลหลายโหมดที่ซับซ้อนมากขึ้นเป็นพื้นที่ที่ต้องมีการวิจัยและการพัฒนาอย่างต่อเนื่อง
นอกจากนี้ เนื่องจากมีการเปิดตัวโมเดล AI ที่มีขีดความสามารถคล้ายกันมากขึ้น ข้อกังวลด้านจริยธรรม เนื้อหาที่สร้างโดย AI โดยรอบ อคติและ ความเป็นส่วนตัวของข้อมูล ยังคงได้รับความสนใจอย่างต่อเนื่อง การรับรองว่า Qwen2.5-VL-32B และรุ่นที่คล้ายกันได้รับการฝึกอบรมและใช้งานอย่างมีความรับผิดชอบจะเป็นสิ่งสำคัญต่อความสำเร็จในระยะยาว
หัวข้อที่เกี่ยวข้อง:การเปรียบเทียบโมเดล AI ยอดนิยม 8 อันดับแรกของปี 2025
สรุป
Qwen2.5-VL-32B เป็นเครื่องมืออันทรงพลังในคลังอาวุธของโมเดล AI ที่ออกแบบมาเพื่อรับมือกับ งานหลายรูปแบบ ด้วยความแม่นยำและความซับซ้อนที่น่าประทับใจ ด้วยการผสานรวมขั้นสูง การเรียนรู้การเสริมแรง, สถาปัตยกรรมหม้อแปลงไฟฟ้าและ การจัดตำแหน่งภาษาภาพ, มันไม่เพียงแต่ เหนือกว่ารุ่นก่อนหน้า แต่ยังเปิดโอกาสที่น่าตื่นเต้นให้กับอุตสาหกรรมต่างๆ ตั้งแต่ การศึกษา ไปยัง การขับขี่แบบอิสระเนื่องจากเป็นเทคโนโลยีโอเพ่นซอร์ส จึงมอบศักยภาพมหาศาลให้กับนักพัฒนาและผู้ใช้ AI ในการทดลอง ปรับแต่ง และนำไปใช้งานในแอปพลิเคชันโลกแห่งความเป็นจริง
วิธีการเรียกใช้ API Qwen2.5-VL-32B จาก CometAPI
1.ล็อกอิน ไปยัง โคเมตาปิดอทคอม. หากคุณยังไม่ได้เป็นผู้ใช้ของเรา กรุณาลงทะเบียนก่อน
2.รับรหัส API ของข้อมูลรับรองการเข้าถึง ของอินเทอร์เฟซ คลิก "เพิ่มโทเค็น" ที่โทเค็น API ในศูนย์ส่วนบุคคล รับคีย์โทเค็น: sk-xxxxx และส่ง
-
รับ URL ของเว็บไซต์นี้: https://api.cometapi.com/
-
เลือกจุดสิ้นสุด Qwen2.5-VL-32B เพื่อส่งคำขอ API และตั้งค่าเนื้อหาคำขอ วิธีการคำขอและเนื้อหาคำขอจะได้รับจาก เอกสาร API ของเว็บไซต์ของเราเว็บไซต์ของเรายังให้บริการทดสอบ Apifox เพื่อความสะดวกของคุณอีกด้วย
-
ประมวลผลการตอบสนองของ API เพื่อรับคำตอบที่สร้างขึ้น หลังจากส่งคำขอ API แล้ว คุณจะได้รับอ็อบเจ็กต์ JSON ที่มีคำตอบที่สร้างขึ้น