

Gemini Embedding 2 er Googles første nativt multimodale embedding-model, der kortlægger tekst, billeder, lyd, video og PDF'er til et enkelt 3,072-dimensionelt semantisk vektorrum (med konfigurerbare outputstørrelser). Den introducerer Matryoshka Representation Learning for at levere indlejrede / trunkerede embeddings, forbedret flersproget ydeevne (100+ sprog) og optimerede kontroller til opgavespecifikke embeddings (f.eks. task:search, task:code).
Hvad er Gemini Embedding 2?
Gemini Embedding 2 er en samlet embedding-model fra Google, der placerer flere inputmodaliteter — tekst, billeder, lyd, video og dokumenter — i ét semantisk vektorrum. Hver embedding er (som standard) en 3,072-dimensionel flydende vektor, der repræsenterer den semantiske betydning af inputtet, så semantisk lignende elementer (uanset modalitet) ligger tæt i vektorummet. De vigtigste funktioner er:
- Bred sproglig og formatmæssig dækning: én model, der accepterer tekst, billeder, lyd, video og dokumenter og placerer dem i ét semantisk vektorrum. Gemini Embedding 2 er dokumenteret til at fange semantisk intention på 100+ sprog og acceptere almindelige filformater (PNG/JPEG, MP4/MOV, MP3/WAV, PDF) med konkrete grænser pr. forespørgsel (f.eks. op til et par billeder eller snesevis af sekunder lyd/video pr. forespørgsel — se “Sådan bruges” nedenfor).
- Ægte multimodalitet: én model, der accepterer tekst, billeder, lyd, video og dokumenter og placerer dem i ét semantisk vektorrum, så du kan sammenligne eller hente på tværs af modaliteter (f.eks. tekst → billede, lyd → tekst).
- Stor standarddimensionalitet med fleksibel trunkering: modellen outputter som standard 3072-dimensionelle vektorer, men bruger Matryoshka Representation Learning (MRL) til at koncentrere den vigtigste semantiske information i de første dimensioner, så du kan trunkere til 1536, 768 (eller lavere) med kun beskedne fald i hentekvalitet. Dette reducerer afvejninger mellem lager og compute-omkostninger.
Hvorfor det er vigtigt. Historisk set var embeddings mest tekst-only eller krævede separate encodere pr. modalitet med komplekse tværmodale alignments. Gemini Embedding 2 fjerner den barriere ved nativt at understøtte flere formater — så en tekstforespørgsel kan hente et billede eller et kort klip via semantisk lighed uden mellemliggende transskription eller manuel mapping. Det forenkler RAG (retrieval-augmented generation), semantisk søgning og multimodale hentepipelines.
Nøglefunktioner og muligheder (hvad er nyt)
1. Ægte, nativ multimodalitet (ét embedding-rum)
En enkelt model, der accepterer tekst, billeder, lyd, video og dokumenter og placerer dem i ét semantisk vektorrum. Gemini Embedding 2 placerer tekst, billeder, lyd, video og dokumenter i det samme embedding-rum, så tværmodal hentning (tekst→billede, lyd→tekst) fungerer direkte uden tværmodel-justering. Dette reducerer pipeline-kompleksitet og forenkler RAG-stakke (Retrieval-Augmented Generation).
2. 3,072-dimensionelle standardvektorer med justerbart output
Gemini Embedding 2 outputter som standard 3072-dimensionelle vektorer, men bruger Matryoshka Representation Learning (MRL) til at koncentrere den vigtigste semantiske information i de første dimensioner, så du kan trunkere til 1536, 768 (eller lavere) med kun beskedne fald i hentekvalitet. Dette reducerer afvejninger mellem lager og compute-omkostninger.
3. Matryoshka Representation Learning (MRL)
MRL producerer “indlejrede” embeddings — som russiske babushka-dukker — så skiver med lavere dimensionalitet bevarer overordnede semantikker. Dette gør det muligt for systemer at vælge et driftspunkt (afvejning mellem lager/accuracy) uden at vedligeholde flere separate embedding-modeller. Tidlige bloganalyser og dokumentation beskriver denne teknik som en kerneinnovation for fleksibilitet.
4. Opgave-hints / tilpassede embedding-mål
API'en accepterer task-hints (f.eks. task:search, task:code retrieval, task:semantic-similarity), så modellen kan optimere embedding-geometrien til specifikke downstream-relationer — svarende til opgavekonditionering i tidligere embedding-systemer, men udvidet til multimodale input.
5. Sproglig og modal bredde
Gemini Embedding 2 er dokumenteret til at fange semantisk intention på 100+ sprog og acceptere almindelige filformater (PNG/JPEG, MP4/MOV, MP3/WAV, PDF) med konkrete grænser pr. forespørgsel (f.eks. op til et par billeder eller snesevis af sekunder lyd/video pr. forespørgsel — se “Sådan bruges” nedenfor).
Benchmarkresultater
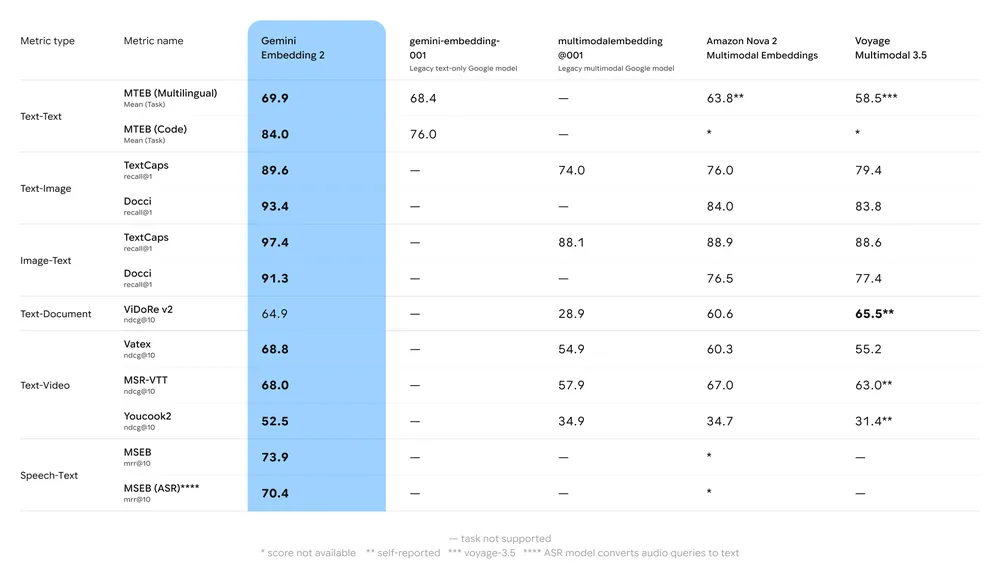
Nøgleopsummering af benchmarks:
- MTEB (Massive Text Embedding Benchmark): Rapporteret stærk placering på flersprogede MTEB-leaderboards for engelske og flersprogede opgaver; analyser viser meningsfulde løft ift. Geminis tidligere embedding-modeller og mange proprietære alternativer.
- Multimodal hentning: Overgår eller matcher førende enkeltmodale embeddings ved brug til tværmodal lighed (f.eks. tekst→billede-hentning) takket være nativ multimodal træning.
- Latens og throughput: Cloud-hostet embedding-generering, men latensfølsomme use cases kan foretrække trunkerede vektorer eller alternative letvægtsembedding-modeller til edge-behov.
Gemini Embedding 2 vs gemini-embedding-001 og text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| Modalities supported | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| Default embedding dim. | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| Native audio/video support | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| Typical use cases | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
Tekniske specifikationer og begrænsninger
Standard- og justerbar embedding-størrelse
- Standard: 3,072 dimensioner.
- Justerbar: Parameteren
output_dimensionalitygiver mulighed for at anmode om lavere dimensionelle output for at spare lager/CPU. Use cases med massive vektorlagre reducerer ofte dimensioner til 512–1,024 af omkostningsårsager, men accepterer noget accuracy-tab.
Understøttede modaliteter og begrænsninger pr. forespørgsel
- Billeder: PNG, JPEG — op til 6 billeder pr. forespørgsel (leverandørrapporterede grænser).
- Video: MP4, MOV — leverandøren rapporterer op til ~128 sekunder pr. video for embedding i en enkelt forespørgsel.
- Lyd: MP3, WAV — leverandøren rapporterer op til ~80 sekunder pr. lydinput.
- Dokumenter: PDF'er — op til 6 sider pr. forespørgsel (leverandørrapportering).
- Token-grænse for tekstindhold: modellen understøtter store token-input; praktiske grænser pr. forespørgsel findes (tjek API-dokumenter og Vertex AI-kvoter).
Tilgængelighed og adgang
- Public preview: Gemini Embedding 2 blev frigivet som en offentlig forhåndsvisning og er tilgængelig via Gemini API og Google Clouds Vertex AI til øjeblikkelig eksperimentel brug
Ofte stillede spørgsmål (FAQ)
Q1: What modalities does Gemini Embedding 2 support?
A: Tekst, billeder (PNG/JPEG), video (MP4/MOV), lyd (MP3/WAV) og PDF-dokumenter — alle kortlagt til det samme semantiske vektorrum.
Q2: What is the default vector size for Gemini Embedding 2?
A: Standard er 3,072 dimensioner. Du kan anmode om mindre outputdimensionalitet via API'en.
Q3: Is Gemini Embedding 2 available now?
A: Ja — det blev annonceret som en offentlig forhåndsvisning og er tilgængeligt via Gemini API og Vertex AI (tjek model-id'et gemini-embedding-2-preview og den aktuelle changelog).
Q4: How does it compare to embeddings from other providers?
A: Uafhængige leverandørtests rapporterer, at Gemini Embedding 2 rangerer blandt de bedste proprietære modeller for flersproget tekst og viser state-of-the-art ydeevne for flere multimodale opgaver. Præcise placeringer varierer efter opgave og datasæt; test på dine egne data.
Q5: Will I need to transcribe audio to use Gemini Embedding 2?
A: Nej — Gemini Embedding 2 kan acceptere lyd direkte og producere embeddings uden først at transskribere til tekst, hvilket muliggør end-to-end semantisk lydhentning.
Q6: How do I lower storage costs for 3,072-dim vectors?
A: Muligheder inkluderer at anmode om lavere output_dimensionality, bruge float16/kvantisering/PQ og lagre komprimerede repræsentationer i din vektordatabase. Leverandørindlæg giver workflows og bedste praksis.
Hvad er det næste — bør jeg adoptere det nu?
Gemini Embedding 2 er et stort skridt i at forene multimodal hentning og forenkler arkitekturer, der tidligere krævede separate retrievere til tekst, vision og tale. De vigtigste beslutningspunkter for adoption:
- Adoptér hurtigere, hvis dit produkt har brug for robust tværmodal hentning (tekst↔billede/video/lyd), eller hvis vedligeholdelse af flere enkeltmodalitetsretrievere er dyrt og komplekst.
- Pilotér nu, hvis du vil evaluere MRL-trunkering og måle omkostninger vs. kvalitet (behold en hybrid-implementering: 1536 som primær, 3072 til re-ranking).
- Vent hvis din arbejdsbyrde er ekstremt omkostningsfølsom, og kun teksthentning er påkrævet — top tekst-only-modeller (f.eks. OpenAI text-embedding-3-large) er fortsat konkurrencedygtige og nogle gange billigere afhængigt af din pipeline og kontrakt.
Udviklere kan få adgang til Gemini Embedding 2 og OpenAI text-embedding-3 API via CometAPI nu. For at komme i gang kan du udforske modellens kapabiliteter i Playground og konsultere API guide for detaljerede instruktioner. Før adgang, skal du sørge for, at du er logget ind på CometAPI og har fået API-nøglen. CometAPI tilbyder en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at komme i gang?→ Tilmeld dig CometAPI i dag!
Hvis du vil have flere tips, guider og nyheder om AI, så følg os på VK, X og Discord!