

I den hastigt udviklende verden af kunstig intelligens repræsenterer udgivelsen af hver ny stor sprogmodel (LLM) mere end et numerisk versionsløft – den signalerer fremskridt inden for ræsonnement, kodningsevner og samarbejde mellem menneske og maskine. I slutningen af september 2025, Zhipu AI (Z.ai) afsløret GLM-4.6, det nyeste medlem af dens General Language Model-familie. Byggende på den robuste arkitektur og det stærke ræsonnement i GLM-4.5, forfiner denne opdatering modellens muligheder i agentisk ræsonnement, kodningsintelligens og forståelse af lang kontekst, samtidig med at den forbliver åben og tilgængelig for både udviklere og virksomheder.
Hvad er GLM-4.6?
GLM-4.6 er en større udgivelse i GLM-serien (General Language Model), der er designet til at balancere højkapacitets ræsonnement med praktiske udvikler-arbejdsgange. På et overordnet niveau er udgivelsen rettet mod tre tæt forbundne use cases: (1) avanceret kodegenerering og ræsonnement om kode, (2) udvidede kontekstopgaver, der kræver modelforståelse på tværs af meget lange input, og (3) agentiske arbejdsgange, hvor modellen skal planlægge, kalde værktøjer og orkestrere flertrinsprocesser. Modellen leveres i varianter beregnet til cloud-API'er og community model hubs, hvilket muliggør både hostede og selvhostede implementeringsmønstre.
Rent praktisk er GLM-4.6 positioneret som et "udvikler-først" flagskib: dets forbedringer handler ikke kun om rå benchmark-tal, men om funktioner, der væsentligt ændrer, hvordan udviklere bygger assistenter, kodecopiloter og dokument- eller vidensdrevne agenter. Forvent en udgivelse, der lægger vægt på instruktionsjustering til værktøjsbrug, finjusterede forbedringer af kodekvalitet og fejlfinding samt infrastrukturvalg, der muliggør meget lange kontekster uden lineær degeneration i ydeevne.
Hvad har GLM-4.6 til formål at løse?
- Reducer friktionen ved at arbejde med lange kodebaser og store dokumenter ved at understøtte længere effektive kontekstvinduer.
- Forbedr pålideligheden af kodegenerering og fejlfinding, hvilket producerer mere idiomatiske, testbare output.
- Øg robustheden af agentisk adfærd — planlægning, brug af værktøjer og udførelse af opgaver i flere trin — gennem målrettet instruktion og justering af forstærkningsstil.
Fra GLM-4.5 til GLM-4.6, hvad ændrede sig i praksis?
- Kontekstskalering: 128K spring til 200 tokens er den største enkeltstående ændring i brugeroplevelsen/arkitekturen for brugerne: lange dokumenter, hele kodebaser eller udvidede agenttranskripter kan nu behandles som et enkelt kontekstvindue. Dette reducerer behovet for ad hoc chunking eller dyre hentningsløkker for mange arbejdsgange.
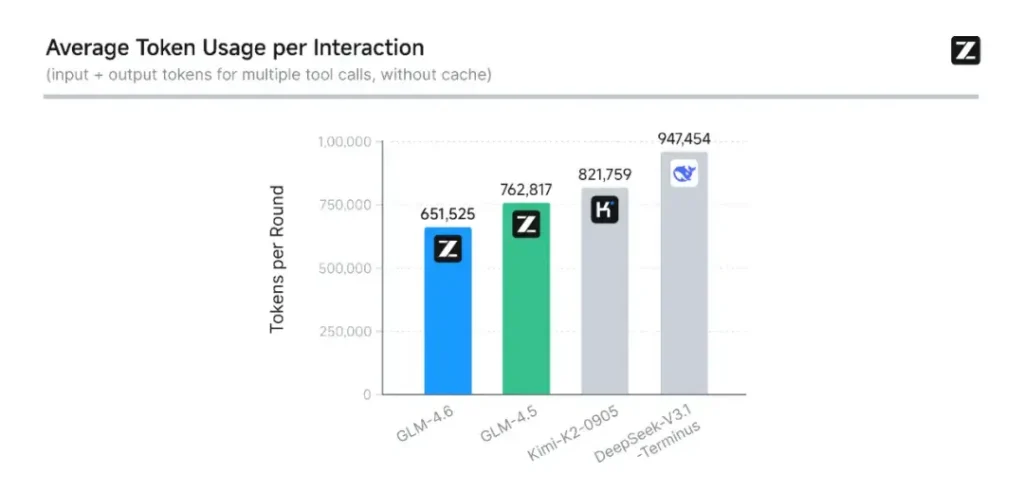
- Kodning og evaluering i den virkelige verden: Z.ai udvidede CC-Bench (deres benchmark for kodning og færdiggørelse) med sværere, reelle opgavebaner og rapporterer, at GLM-4.6 afslutter opgaver med ~15% færre tokens end GLM-4.5, samtidig med at succesraterne i komplekse multi-turn engineering-opgaver forbedres. Dette signalerer bedre token-effektivitet samt forbedringer af rå kapacitet i anvendte kodningsscenarier. Z.ai
- Agent- og værktøjsintegration: GLM-4.6 inkluderer bedre supportmønstre til værktøjskald og søgeagenter – vigtigt for produkter, der er afhængige af modellen til at orkestrere websøgning, kodeudførelse eller andre mikrotjenester.
Hvad er de vigtigste funktioner i GLM-4.6?
1. Udvidet kontekstvindue til 200 tokens
En af de mest opsigtsvækkende funktioner ved GLM-4.6 er dens massivt udvidet kontekstvindueUdvidelse fra 128K i den forrige generation til 200 tokensGLM-4.6 kan behandle hele bøger, komplekse datasæt med flere dokumenter eller timevis af dialog i en enkelt session. Denne udvidelse forbedrer ikke kun forståelsen, men muliggør også konsistent ræsonnement over lange input — et stort spring for arbejdsgange inden for dokumentopsummering, juridisk analyse og softwareudvikling.
2. Forbedret kodningsintelligens
Zhipu AI's interne CC-Bænk benchmark, en række programmeringsopgaver fra den virkelige verden, viser, at GLM-4.6 opnår bemærkelsesværdige forbedringer i kodningsnøjagtighed og effektivitetModellen kan producere syntaktisk korrekt, logisk forsvarlig kode, mens den bruger cirka 15% færre tokens end GLM-4.5 til tilsvarende opgaver. Denne token-effektivitet betyder hurtigere og billigere gennemførelser uden at gå på kompromis med kvaliteten – en afgørende faktor for implementering i virksomheder.
3. Avanceret ræsonnement og værktøjsintegration
Ud over generering af rå tekst skinner GLM-4.6 også ind værktøjsudvidet ræsonnementDen er blevet trænet og justeret til flertrinsplanlægning og til at orkestrere eksterne systemer — fra databaser til søgeværktøjer til udførelsesmiljøer. I praksis betyder det, at GLM-4.6 kan fungere som "hjernen" i en autonom AI-agent, beslutte, hvornår eksterne API'er skal kaldes, hvordan resultater skal fortolkes, og hvordan opgavekontinuitet skal opretholdes på tværs af sessioner.
4. Forbedret justering af naturligt sprog
Gennem fortsat forstærkningslæring og præferenceoptimering leverer GLM-4.6 mere jævn samtale, bedre stilmatchning og stærkere sikkerhedstilpasningModellen tilpasser sin tone og struktur til konteksten – uanset om det er formel dokumentation, pædagogisk vejledning eller kreativ skrivning – hvilket forbedrer brugertilliden og læsbarheden.
Hvilken arkitektur driver GLM-4.6?
Er GLM-4.6 en model med en blanding af eksperter?
Kontinuitet i inferensmetode: GLM-teamet angiver, at GLM-4.5 og GLM-4.6 deler den samme grundlæggende inferens-pipeline, hvilket gør det muligt at opgradere eksisterende implementeringsopsætninger med minimal friktion. Dette reducerer den operationelle risiko for teams, der allerede bruger GLM-4.x. – skaleringsparametre og modeldesignvalg, der understreger specialisering til agentisk ræsonnement, kodning og effektiv inferens. GLM-4.5-rapporten giver den klareste offentlige beskrivelse af familiens MoE-strategi og træningsprogram (flertrins prætræning, ekspertmodel-iteration, forstærkningslæring til justering); GLM-4.6 anvender disse erfaringer, samtidig med at kontekstlængde og opgavespecifikke funktioner justeres.
Praktiske arkitekturnoter for ingeniører
- Parameterfodaftryk vs. aktiveret beregning: Store parametertotaler (hundredvis af milliarder) kan ikke direkte omsættes til tilsvarende aktiveringsomkostninger for hver anmodning – MoE betyder, at kun en delmængde af eksperter aktiveres pr. tokensekvens, hvilket giver en mere fordelagtig afvejning mellem omkostninger og gennemløb for mange arbejdsbelastninger.
- Tokenpræcision og formater: De offentlige vægte er fordelt i BF16- og F32-formater, og fællesskabskvantiseringer (GGUF, 4-/8-/bits) dukker hurtigt op; disse giver teams mulighed for at køre GLM-4.6 på forskellige hardwareprofiler.
- Inferensstakkompatibilitet: Z.ai dokumenterer vLLM og andre moderne LLM-runtimes som kompatible inferens-backends, hvilket gør GLM-4.6 mulig til både cloud- og on-prem-implementeringer.
Benchmark-ydeevne: hvordan klarer GLM-4.6 sig?
Hvilke benchmarks blev rapporteret?
Z.ai evaluerede GLM-4.6 på tværs af en række otte offentlige benchmarks spænder over agentopgaver, ræsonnement og kodning. De udvidede også CC-Bench (et menneskeevalueret benchmark for reel kodning, der kører i Docker-isolerede miljøer) for bedre at simulere produktionstekniske opgaver (frontend-udvikling, test, algoritmisk problemløsning). På disse opgaver viste GLM-4.6 konsistente forbedringer i forhold til GLM-4.5.
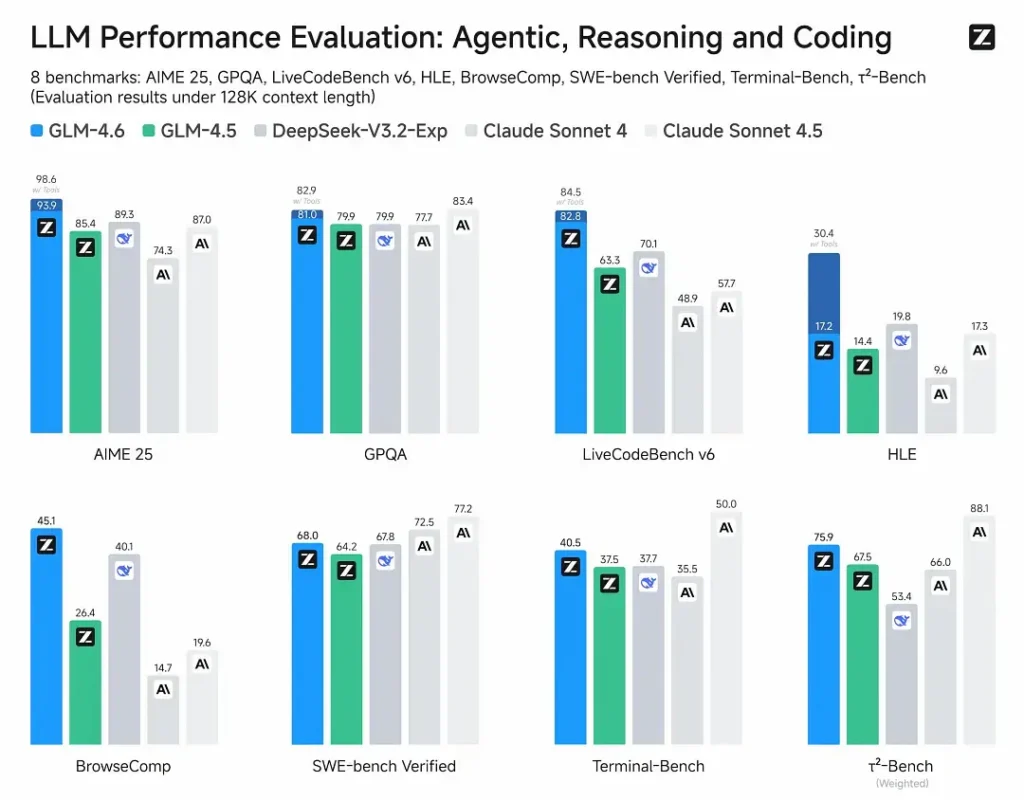
Kodningsydelse
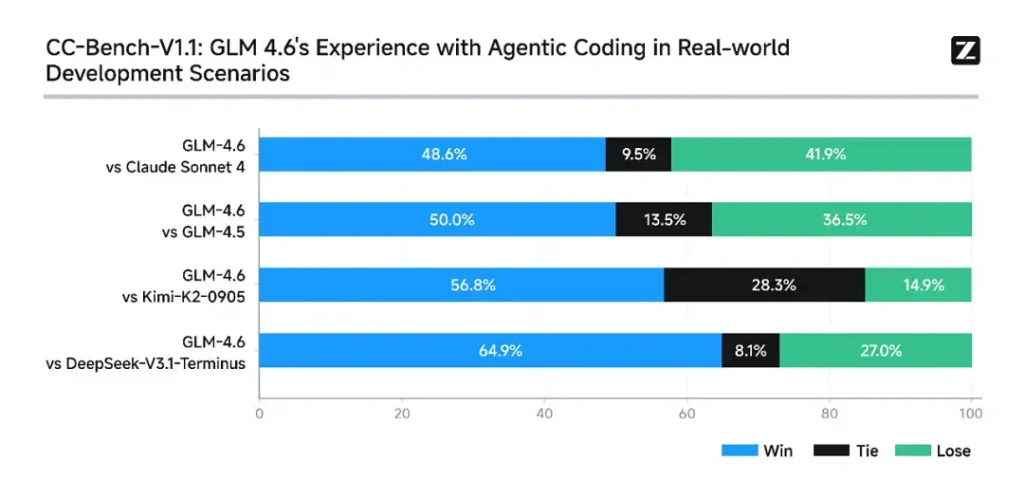
- Sejre ved den virkelige opgave: I CC-Bench humane evalueringer nåede GLM-4.6 nær paritet med Anthropics Claude Sonnet 4 i direkte, flertrinsopgaver – Z.ai rapporterer en 48.6% win sats i deres Docker-isolerede, menneskebedømte evalueringer (fortolkning: næsten 50/50 med Claude Sonnet 4 på deres kuraterede sæt). Samtidig overgik GLM-4.6 en række indenlandske åbne modeller (f.eks. DeepSeek-varianter) på deres opgaver.
- Token-effektivitet: Z.ai rapporterer ~15% færre tokens bruges til at afslutte opgaver sammenlignet med GLM-4.5 i CC-Bench-baner – dette har betydning for både latenstid og omkostninger.
Ræsonnement og matematik
GLM-4.6 hævder forbedret ræsonnementsevne og stærkere værktøjsbrugsevne sammenlignet med GLM-4.5. Hvor GLM-4.5 understregede hybrid "tænkning" og direkte svartilstande, øger GLM-4.6 robustheden for flertrinsræsonnement - især når det integreres med søge- eller udførelsesværktøjer.
Z.ais offentlige meddelelser positionerer GLM-4.6 som konkurrencedygtig med førende internationale og indenlandske modeller på deres valgte benchmarks – specifikt konkurrencedygtige med Claude Sonnet 4 og overgåede visse indenlandske alternativer som DeepSeek-varianter i kode-/agentopgaver. Men i nogle kodningsspecifikke underbenchmarks** halter GLM-4.6 stadig efter Claude Sonnet 4.5 (en nyere Anthropic-udgivelse), hvilket gør landskabet til et landskab præget af tæt konkurrence snarere end direkte dominans.
Sådan får du adgang til GLM-4.6
- 1. Gennem Z.ai-platformen: Udviklere kan få direkte adgang til GLM-4.6 via Z.ais API or **chatgrænseflade (chat.z.ai)**Disse hostede tjenester muliggør hurtig eksperimentering og integration uden lokal implementering. API'en understøtter både standard tekstfuldførelse og strukturerede værktøjskaldstilstande – afgørende for agentworkflows.
- 2. Åbne vægte på det omsluttende ansigt og modelskop: For dem, der foretrækker lokal kontrol, har Zhipu AI udgivet GLM-4.6 modelfiler på Knusende ansigt og ModelScope, inklusive safetensors-versioner i BF16 og F32 præcision. Community-udviklere har allerede produceret kvantiserede GGUF-versioner, hvilket muliggør inferens på forbrugervenlige GPU'er.
- 3. Integrationsrammer: GLM-4.6 integreres problemfrit med større inferensmotorer som f.eks. vLLM, SGLangog LMDeploy, hvilket gør den tilpasningsdygtig til moderne serveringsstabler. Denne alsidighed giver virksomheder mulighed for at vælge mellem cloud, kantog implementering på stedet afhængigt af overholdelse af eller latenstidskrav.
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere – såsom OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i en enkelt, udviklervenlig grænseflade. Ved at tilbyde ensartet godkendelse, formatering af anmodninger og svarhåndtering forenkler CometAPI dramatisk integrationen af AI-funktioner i dine applikationer. Uanset om du bygger chatbots, billedgeneratorer, musikkomponister eller datadrevne analysepipelines, giver CometAPI dig mulighed for at iterere hurtigere, kontrollere omkostninger og forblive leverandøruafhængig – alt imens du udnytter de seneste gennembrud på tværs af AI-økosystemet.
Den seneste integration med GLM-4.6 vil snart blive vist på CometAPI, så følg med! Mens vi færdiggør uploaden af GLM 4.6-modellen, kan du udforske vores andre modeller på siden Models eller prøve dem i AI Playground.
Udviklere kan få adgang GLM-4.5 API gennem Comet API, den nyeste modelversion opdateres altid med den officielle hjemmeside. For at begynde, udforsk modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Konklusion — Hvorfor GLM-4.6 er vigtig nu
GLM-4.6 er en vigtig milepæl i GLM-serien, fordi den kombinerer praktiske forbedringer for udviklere – længere kontekstvinduer, målrettet kodning og agentoptimeringer samt håndgribelige benchmark-gevinster – med den åbenhed og økosystemfleksibilitet, som mange organisationer ønsker. For teams, der bygger kodeassistenter, agenter i langformat til dokumenter eller værktøjsbaserede automatiseringer, er GLM-4.6 værd at evaluere som en topkandidat.