
.webp&w=3840&q=75)
GLM-5.1 repræsenterer et afgørende skift i AI-landskabet. I takt med at kinesiske AI-virksomheder accelererer kommercialiseringen og samtidig open-sourcer frontkapabiliteter, mindsker denne model afstanden til proprietære frontløbere som OpenAI’s GPT-5.4, Anthropics Claude Opus 4.6 og Googles Gemini 3.1 Pro—særligt inden for virkeligt softwareingeniørarbejde. Trænet på den samme MoE-arkitektur med 744B parametre som GLM-5, men kraftigt optimeret til agent-baserede arbejdsgange, excellerer den dér, hvor de fleste LLM’er vakler: lange, tvetydige, iterative opgaver, der kræver planlægning, eksperimentering, fejlfinding og selvkorrektion over tusindvis af værktøjskald.
Nu integrerer CometAPI GLM-5.1 og GLM-5, og udviklere kan også se andre førende vestlige modeller og få adgang til dem til en meget lav API-pris (hvilket også er en fordel ved CometAPI sammenlignet med andre konkurrenter).
Hvad er GLM-5.1?
GLM-5.1 er Z.ai’s nyeste flagskibs-sprogsmodel og virksomhedens seneste satsning på softwarearbejde i agent-stil med lang tidshorisont. Ifølge Z.ai er den designet til opgaver, der kræver kontinuerlig udførelse frem for enkeltstående svar, og den er positioneret som en model, der kan planlægge, eksekvere, forfine og levere i ét udvidet forløb. Z.ai’s udgivelsesnoter siger, at GLM-5.1 er bygget med multi-turn superviseret finjustering, forstærkningslæring og en ramme for evaluering af proceskvalitet, og at den forbedrer stabilitet, konsistens og værktøjsbrug over længerevarende opgaver.
Denne positionering er vigtig, fordi GLM-5.1 ikke sælges som “endnu en chatmodel.” Den er rettet mod ingeniør-arbejdsgange, hvor modeller skal holde et mål for øje, håndtere mellemtrin og komme sig over fejl uden at miste tråden—som en model til autonom planlægning, vedvarende udførelse, fejlfiksning og strategi-iteration, hvilket er en helt anden produktfortælling end en uformel assistent eller en kort-kontekst kodningscopilot.
En nyttig praktisk detalje: GLM-5.1 er kun tekstbaseret, den understøttes i GLM Coding Plan og kan bruges i populære kodeagenter som Claude Code og OpenClaw, hvilket gør den særligt relevant for teams, der vil have en model integreret i en eksisterende udvikler-arbejdsgang frem for at erstatte den.
Kerne-tekniske specifikationer (arvet og forfinet fra GLM-5):
- Arkitektur: Mixture-of-Experts (MoE) med i alt 744 milliarder parametre og cirka 40 milliarder aktive parametre pr. inferens.
- Kontekstvindue: 203K–204.8K tokens (med støtte for op til 131K output-tokens).
- Nøgleforbedringer: DeepSeek Sparse Attention (DSA) for effektiv håndtering af lang kontekst og reducerede deploymentsomkostninger; avanceret asynkron forstærkningslæringsinfrastruktur (via Z.ai’s “slime”-framework) for mere effektiv eftertræning.
- Tilgængelighed: Åbne vægte (MIT-licens på Hugging Face via zai-org/GLM-5.1), API-adgang via Z.ai’s platform og aggregatorer som CometAPI, og integreret i GLM Coding Plan-værktøjer (kompatibel med Claude Code / OpenClaw).
I modsætning til tidligere GLM-modeller, der fokuserede på generel intelligens eller kort “vibe coding,” sigter GLM-5.1 mod produktionsklare autonome agenter. Den kan selvstændigt planlægge, eksekvere, benchmarke, debugge og iterere på komplekse ingeniørprojekter i timevis uden menneskelig indgriben—kapabiliteter, der positionerer den som en direkte konkurrent til specialiserede kodeagenter fra Anthropic og OpenAI.
Udgivelsen faldt sammen med en ~10% API-prisstigning (input tokens ~$0.54/M, output ~$4.40/M), men forbliver dramatisk billigere end ækvivalenter som Anthropics Opus 4.6 (250–470% dyrere).
GLM-5.1 benchmark-ydelse
Z.ai positionerer GLM-5.1 som verdens stærkeste open source-model og en global top-3 performer i agent-baseret kodning. Ydelsesdata stammer fra officielle evalueringer på SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 og brugerdefinerede scenarier med lang tidshorisont.
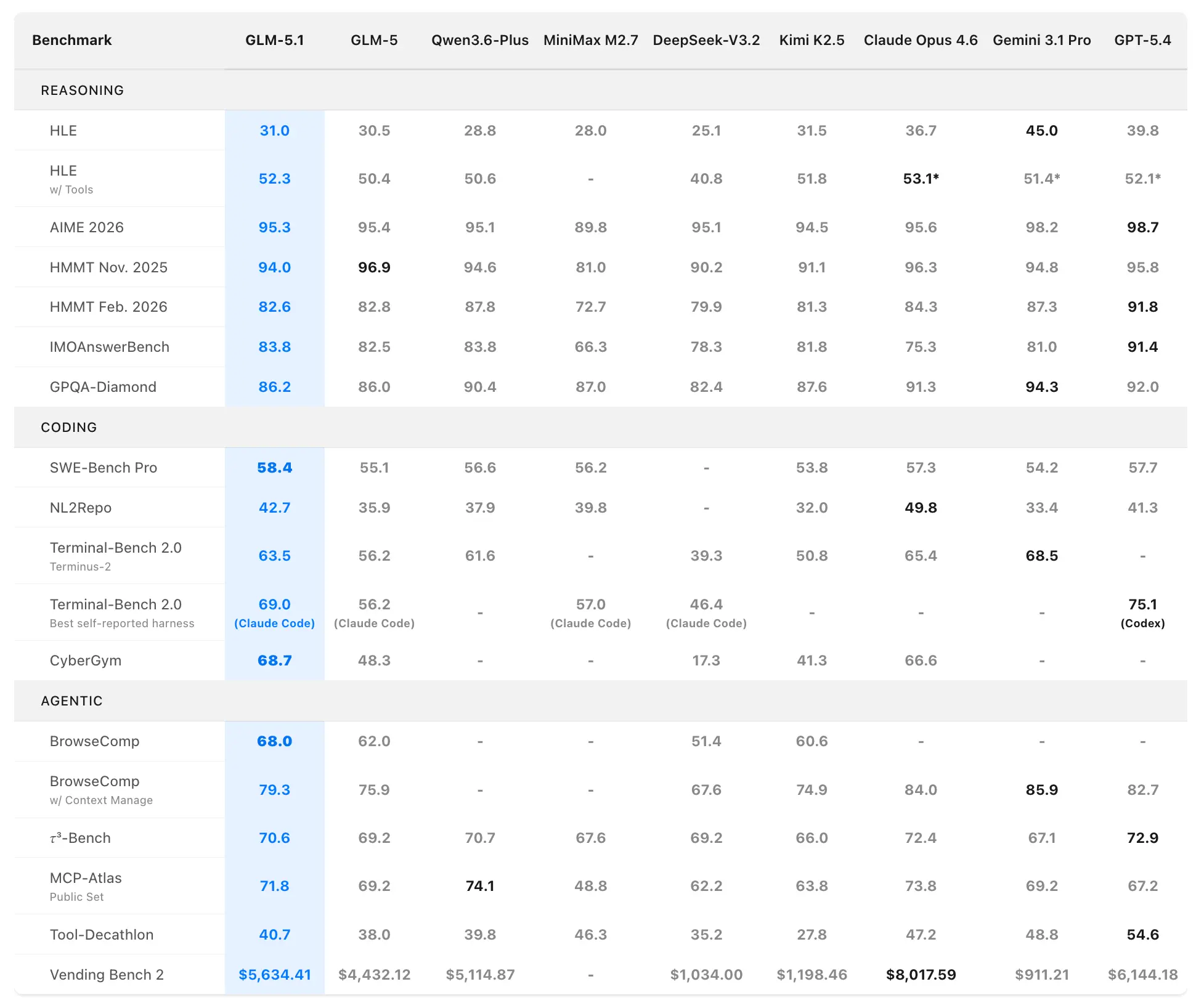
Kodnings- og agent-benchmarks
SWE-Bench Pro (realistiske softwareingeniøropgaver, der kræver repository-navigation, kodeændringer og funktionel verifikation):
- GLM-5.1: 58.4 (ny state of the art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 er den første indenlandske (kinesiske) og open source-model, der indtager førstepladsen på denne krævende benchmark, som ligger tæt op ad professionelle udvikler-arbejdsgange.
NL2Repo (fra naturligt sprog til fuld repository-generering):
- GLM-5.1: 42.7 (bred føring over GLM-5’s 35.9)
- Konkurrerende modeller ligger 32.0–49.8 (konkrete førere varierer efter harness).
Terminal-Bench 2.0 (reelle terminal- og systemopgaver):
- Terminus-2-harness: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Bedste selvrapporterede (Claude Code): Op til 69.0.
I en separat coding harness-evaluering (Claude Code-stil) scorede GLM-5.1 45.3—og nåede 94.6% af Claude Opus 4.6’s 47.9 og en 28% forbedring over GLM-5’s 35.4.
Samlet rangering: #1 open source, #1 kinesisk model, #3 globalt på tværs af SWE-Bench Pro + NL2Repo + Terminal-Bench.
Ydelse på opgaver med lang tidshorisont: Den afgørende differentiering
Standardbenchmarks måler one-shot- eller kort-sessions-ydelse. GLM-5.1 skinner i udvidede autonome forløb:
- VectorDBBench-optimering (600+ iterationer, 6.000+ værktøjskald): Med udgangspunkt i et Rust-skelet redesignede GLM-5.1 iterativt indeksering, komprimering, routing og pruning og opnåede 21.5k QPS (6× den tidligere 50-turn bedste på 3.547 QPS af Claude Opus 4.6) med ≥95% recall på SIFT-1M. Den udviste “trappevis” fremgang med strukturelle gennembrud hver 100–200 iterationer.
- KernelBench Level 3 (fuld ML-modeloptimering, 1.000+ ture): Geometrisk gennemsnitlig hastighedsforøgelse på 3.6× på tværs af 50 komplekse problemer (overgår torch.compile max-autotune’s 1.49×). GLM-5.1 fortsatte med at forbedre sig længe efter, at GLM-5 havde plateauet; kun Claude Opus 4.6 slog den med 4.2×.
- Linux-desktop-webapp-bygning (8+ timer, åbent): Med kun en naturlig sprogprompt og ingen startkode byggede GLM-5.1 autonomt et funktionsdygtigt Linux-lignende skrivebordsmiljø—komplet med proceslinje, vinduer, interaktioner og finish—hvor tidligere modeller kun producerede basale skeletter.
Disse resultater demonstrerer GLM-5.1’s evne til at opretholde kohærens, selvevaluere, revidere strategier og undslippe lokale optima over ekstremt lange horisonter—kapabiliteter, som Z.ai eksplicit har udviklet til virkelige agent-systemer.
Hvordan adskiller GLM-5.1 sig fra GLM-5?
GLM-5 og GLM-5.1 er nært beslægtede, men de er ikke positioneret ens. GLM-5 er Z.AI’s tidligere fundamentmodel for Agentic Engineering. Den er designet til kompleks systemengineering og agent-opgaver med lang rækkevidde, med open-weight SOTA-kodning og agent-kapabilitet, og kodningsydelse, der nærmer sig Claude Opus 4.5 i virkelige programmeringsscenarier. Den scorer 77.8 på SWE-bench Verified og 56.2 på Terminal Bench 2.0.
GLM-5.1 er derimod præsenteret som det næste skridt mod opgaver med lang tidshorisont og mere pålidelig vedvarende udførelse, forbedrer stabilitet, konsistens og værktøjsbrug over længerevarende opgaver, og er samlet set bedre afstemt med Claude Opus 4.6. Med andre ord er GLM-5 den tidligere ingeniør-centriske fundamentmodel, mens GLM-5.1 er det mere udholdenhedsorienterede flagskib.
Der er også arkitekturmæssige og træningsmæssige forskelle i GLM-5-generationen, der hjælper med at forklare springet. GLM-5 udvidede fra 355B parametre (32B aktiveret) til 744B parametre (40B aktiveret), øgede prætræningsdata fra 23T til 28.5T, tilføjede et asynkront forstærkningslærings-framework og integrerede DeepSeek Sparse Attention for at bevare kvaliteten på lange tekster samtidig med forbedret effektivitet. Disse detaljer er knyttet til GLM-5, men de udgør basen, som GLM-5.1 ser ud til at bygge videre på.
GLM-5.1 vs andre førende modeller
GLM-5.1 skiller sig ud som den stærkeste open source-udfordrer samtidig med at tilbyde overbevisende pris/ydelse.
Sammenligningstabel: Vigtigste kodnings- og agent-benchmarks (april 2026)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Lang-horisont vedvarende? | Open source? | Ca. API-pris (input/output pr. M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% af Opus) | Ja (600+ iter, 8 hrs) | Ja | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Begrænset | Ja | Lavere (før prisstigning) |
| GPT-5.4 | 57.7 | — | — | — | Stærk | Nej | Højere |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Stærkest | Nej | ~250–470% dyrere |
| Gemini 3.1 Pro | 54.2 | — | — | — | God | Nej | Højere |
Vurdering: GLM-5.1 vinder på open source-tilgængelighed, pris og specifikke lang-horisont kodningsmetriker. Den tager kampen op med lukkede frontløbere i agent-scenarier og demokratiserer samtidig frontkapabiliteter.
Anvendelsesscenarier for GLM-5.1
1) Autonom software engineering
GLM-5.1 er mest overbevisende, når opgaven ligner et rigtigt udviklingssprint: læs kodebasen, planlæg ændringen, implementér den, test, fix regressioner og bliv ved med at iterere, indtil resultatet er stabilt. Z.ai’s udgivelsesnoter fremhæver eksplicit autonom planlægning, vedvarende udførelse, bug-fiksning og strategi-iteration, hvilket får denne model til at føles skræddersyet til kodeagenter og softwareleverance-pipelines.
2) Langvarige agent-arbejdsgange
Hvis din brugssag involverer mange værktøjskald, lange multitrins-arbejdsgange eller gentagen selvkorrektion, er GLM-5.1’s design et stærkt match. Dokumentationen fremhæver værktøjsinvokation, struktureret output, MCP-integration og tool-streaming-understøttelse, som alle er nyttige, når en model ikke bare svarer, men opererer inde i et større system.
3) Videnarbejde og rapportering i virksomheder
GLM-5.1 er også positioneret til kontorproduktivitet som PowerPoint-, Word-, PDF- og Excel-arbejdsgange. Z.ai siger, at den forbedrer kompleks indholdsorganisering, layoutdesign, struktureret output og visuel finish, hvilket gør den plausibel til rapportgenerering, undervisningsmateriale, forskningsresuméer og andet dokumenttungt arbejde.
4) Front-end prototyping og artefakter
Z.ai siger, at GLM-5.1 er velegnet til websidegenerering, interaktive sider og front-end-prototyping, med mindre skabelonpræg og bedre opgavegennemførelse. Det antyder et godt match for produktteams, der har brug for en hurtig bro fra brief til prototype—særligt når prototypen skal være brugbar og ikke bare pæn.
5) Kompleks samtale og instruktionsefterlevelse
Selvom overskriften er kodning, beskrives GLM-5.1 også som stærkere i åbne spørgsmål/svar, komplekse instruktioner og multi-turn-interaktion. Det gør den nyttig til assistent-lignende arbejdsgange, hvor modellen skal holde styr på begrænsninger, revidere outputs og bevare konteksten på tværs af længere samtaler.
Konklusion: Hvorfor GLM-5.1 betyder noget i 2026
GLM-5.1 er ikke bare endnu en inkrementel udgivelse—den signalerer ankomsten af virkelig kapable open source agent-AI’er. Ved at excellere i de sværeste virkelige ingeniørbenchmarks og samtidig forblive overkommelig og åben, har Z.ai hævet barren for hele branchen. Uanset om du er solo-udvikler, virksomhedsteam eller forsker, tilbyder GLM-5.1 uovertruffen autonomi til lang-horisont kodningsopgaver til en brøkdel af prisen for proprietære alternativer.
Klar til at prøve det? Tjek CometAPI GLM-5.1-modellen, Hugging Face-repoet eller GLM Coding Plan for øjeblikkelig adgang.