

GPT-5.2 er OpenAIs punktudgivelse fra december 2025 i GPT-5-familien: en flagskibs-multimodal modelfamilie (tekst + vision + værktøjer) finjusteret til professionelt vidensarbejde, langkontekst-ræsonnement, agentisk værktøjsbrug og software engineering. OpenAI positionerer GPT-5.2 som den mest kapable model i GPT-5-serien til dato og siger, at den er udviklet med vægt på pålideligt flertrinsræsonnement, håndtering af meget store dokumenter og forbedret sikkerhed/politikoverholdelse; udgivelsen omfatter tre brugerrettede varianter — Instant, Thinking og Pro — og rulles først ud til betalende ChatGPT-abonnenter og API-kunder.
Hvad er GPT-5.2, og hvorfor er det vigtigt?
GPT-5.2 er det nyeste medlem af OpenAIs GPT-5-familie — en ny “frontier”-modelserie designet specifikt til at lukke hullet mellem enkeltturs samtaleassistenter og systemer, der skal ræsonnere på tværs af lange dokumenter, kalde værktøjer, fortolke billeder og udføre flertrins-workflows pålideligt. OpenAI positionerer 5.2 som deres mest kapable udgivelse til dato til professionelt vidensarbejde: den sætter nye state-of-the-art-resultater på interne benchmarks (især en ny GDPval-benchmark for vidensarbejde), demonstrerer stærkere kodepræstation på software-engineering-benchmarks og tilbyder markant forbedrede langkontekst- og visionskapabiliteter.
I praktiske termer er GPT-5.2 mere end blot “en større chatmodel.” Det er en familie af tre finjusterede varianter (Instant, Thinking, Pro), der afvejer latenstid, dybde af ræsonnement og omkostning — og som, sammen med OpenAIs API og ChatGPT-routing, kan bruges til at køre lange forskningsjobs, bygge agenter der kalder eksterne værktøjer, fortolke komplekse billeder og diagrammer og generere produktionsklar kode med højere fidelitet end tidligere udgivelser. Modellen understøtter meget store kontekstvinduer (OpenAIs dokumenter angiver et kontekstvindue på 400.000 tokens og en maksimal outputgrænse på 128.000 for flagskibsmodellerne), nye API-funktioner til eksplicitte niveauer for ræsonneringsindsats og “agentisk” værktøjsinvokering.
5 kernekapabiliteter opgraderet i GPT-5.2
1) er GPT-5.2 bedre til flertrinslogik og matematik?
GPT-5.2 bringer skarpere flertrinsræsonnement og mærkbart stærkere præstation på matematik og struktureret problemløsning. OpenAI siger, at de har tilføjet mere granulær kontrol over ræsonneringsindsats (nye niveauer såsom xhigh), konstrueret støtte til “reasoning tokens” og finjusteret modellen til at opretholde tankekæde over længere interne ræsonneringsspor. Benchmarks som FrontierMath og ARC-AGI-stil tests viser substantielle gevinster i forhold til GPT-5.1; den har større marginer på domænespecifikke benchmarks brugt i videnskabelige og finansielle workflows. Kort sagt: GPT-5.2 “tænker længere”, når man beder den om det, og kan udføre mere kompliceret symbolsk/matematisk arbejde med bedre konsistens.

| RC-AGI-1 (Verified) Abstrakt ræsonnement | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) Abstrakt ræsonnement | 52.9% | 17.6% |
GPT-5.2 Thinking sætter rekorder i flere avancerede test af videnskabeligt og matematisk ræsonnement:
- GPQA Diamond Science Quiz: 92.4% (Pro-versionen 93.2%)
- ARC-AGI-1 Abstrakt ræsonnement: 86.2% (første model til at bryde 90%-grænsen)
- ARC-AGI-2 Højereordensræsonnement: 52.9%, en ny rekord for Thinking Chain-modellen
- FrontierMath Avanceret matematiktest: 40.3%, langt over sin forgænger;
- HMMT Matematik-konkurrenceopgaver: 99.4%
- AIME Matematiktest: 100% fuld løsning
Desuden er GPT-5.2 Pro (High) state-of-the-art på ARC-AGI-2 med en score på 54.2% til en pris på $15.72 pr. opgave! Overgår alle andre modeller.
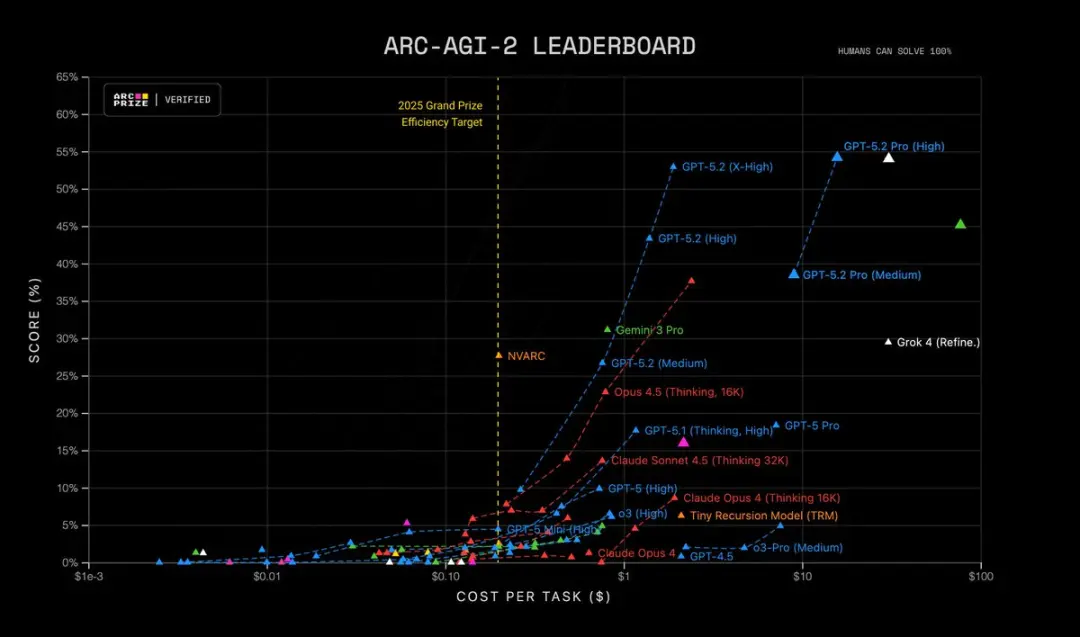
Hvorfor det er vigtigt: mange opgaver i den virkelige verden — finansiel modellering, forsøgsdesign, programsyntese der kræver formelt ræsonnement — er flaskehalsede af en models evne til at kæde mange korrekte trin sammen. GPT-5.2 reducerer “hallucinerede trin” og producerer mere stabile mellemregninger, når du beder den vise sin fremgangsmåde.
2) Hvordan er forståelsen af lange tekster og tværdokument-ræsonnement forbedret?
Langkontekstforståelse er en af de profilbærende forbedringer. GPT-5.2’s underliggende model understøtter et kontekstvindue på 400k tokens og — vigtigt — opretholder højere nøjagtighed, efterhånden som relevant indhold forskydes dybt ind i den kontekst. GDPval, en opgavesuite for “velspecificeret vidensarbejde” på tværs af 44 professioner, hvor GPT-5.2 Thinking når paritet med eller bedre end menneskelige ekspert-dommere på en stor andel af opgaver. Uafhængig rapportering bekræfter, at modellen fastholder og syntetiserer information på tværs af mange dokumenter langt bedre end tidligere modeller. Dette er et reelt praktisk fremskridt for opgaver som due diligence, juridisk opsummering, litteraturgennemgange og forståelse af kodebaser.
GPT-5.2 kan håndtere kontekster op til 256.000 tokens (omtrent 200+ sider dokumenter). Desuden opnåede GPT-5.2 Thinking en nøjagtighed tæt på 100% i “OpenAI MRCRv2”-testen for forståelse af lange tekster.
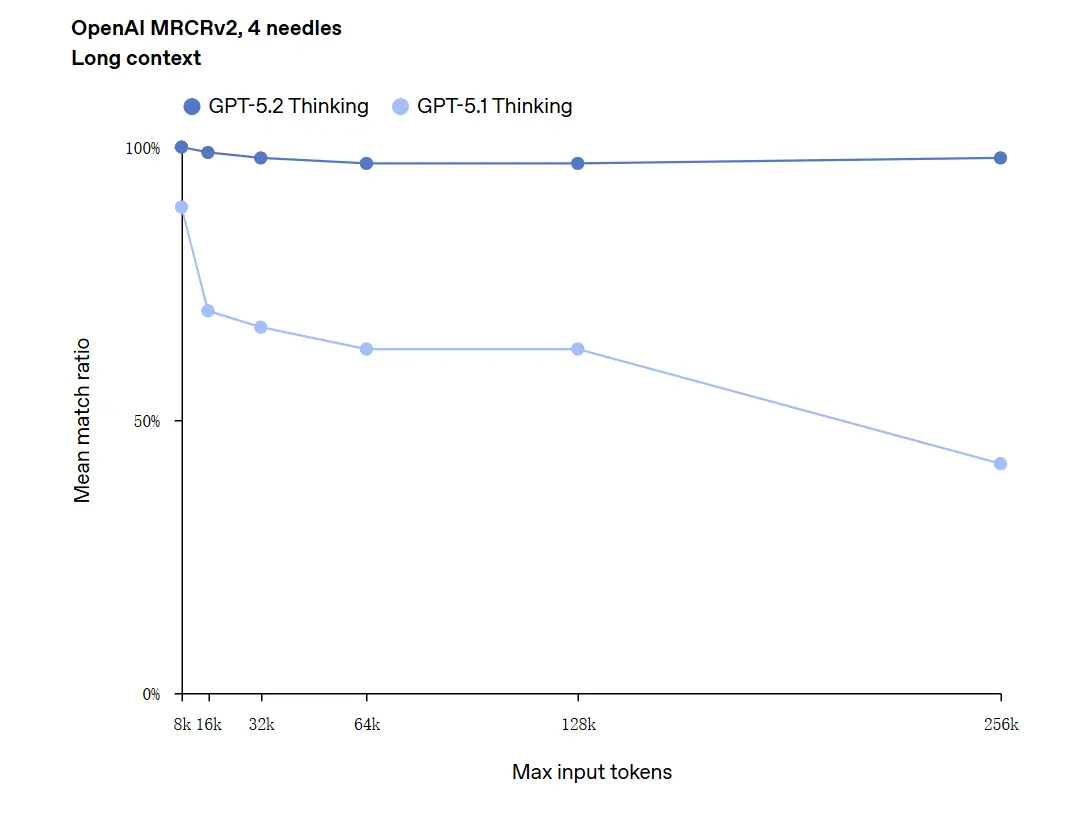
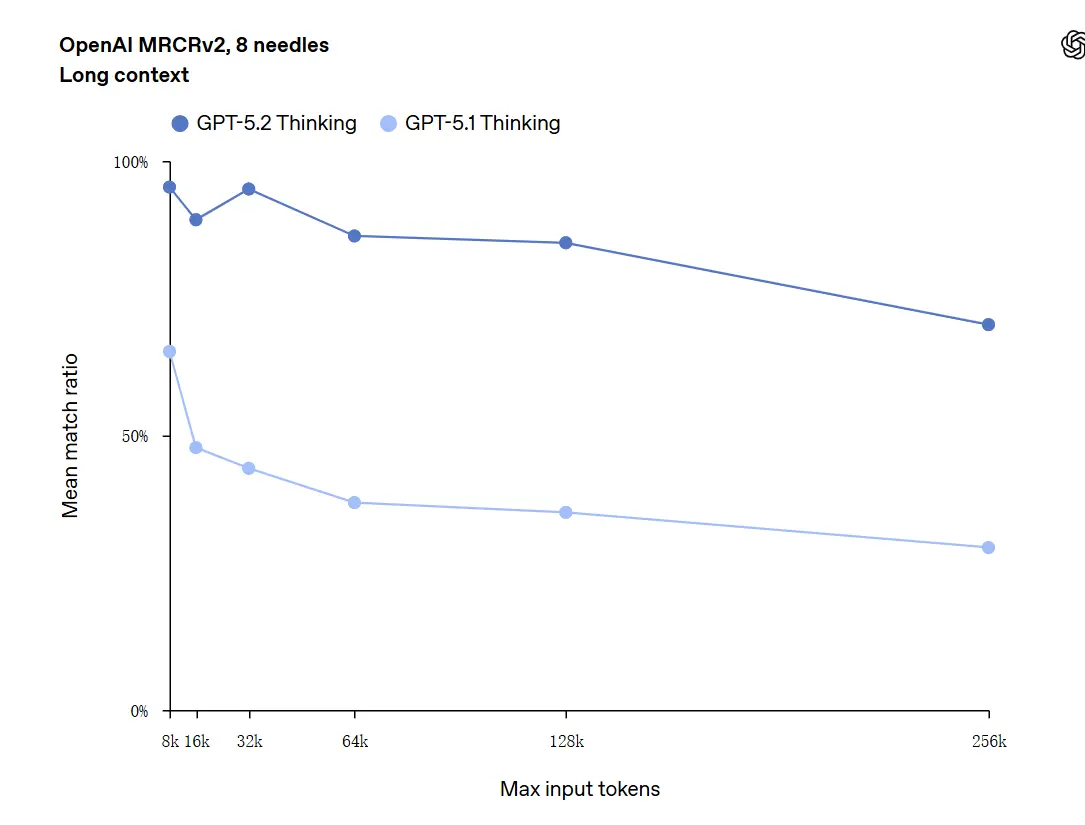
Forbehold ved “100% nøjagtighed”: Forbedringerne blev beskrevet som “nærmer sig 100%” for snævre mikroopgaver; OpenAIs data beskrives bedre som “state-of-the-art og i mange tilfælde på eller over menneskeligt ekspertniveau på de evaluerede opgaver,” ikke bogstaveligt talt fejlfri på alle anvendelser. Benchmarks viser store fremskridt men ikke universel perfektion.
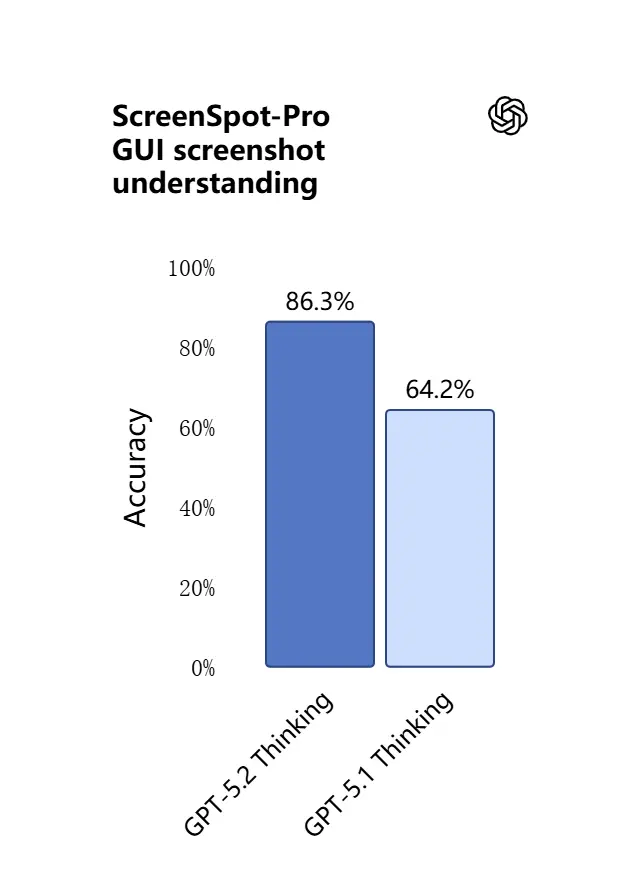
3) Hvad er nyt i visuel forståelse og multimodalt ræsonnement?
Visionsevnerne i GPT-5.2 er skarpere og mere praktiske. Modellen er bedre til at fortolke skærmbilleder, læse diagrammer og tabeller, genkende UI-elementer og kombinere visuelle input med lang tekstlig kontekst. Det er ikke bare billedtekster: GPT-5.2 kan udtrække strukturerede data fra billeder (f.eks. tabeller i en PDF), forklare grafer og ræsonnere om diagrammer på måder, der understøtter nedstrøms værktøjshandlinger (f.eks. generere et regneark fra en fotograferet rapport).
.webp)
Praktisk effekt: Teams kan sende hele slidedecks, scannede forskningsrapporter eller dokumenter med mange billeder direkte ind i modellen og bede om synteser på tværs af dokumenter — hvilket i høj grad reducerer manuelt ekstraheringsarbejde.
4) Hvordan har værktøjsinvokering og opgaveudførelse ændret sig?
GPT-5.2 skubber videre i retning af agentisk adfærd: den er bedre til at planlægge flertrinsopgaver, beslutte hvornår der skal kaldes eksterne værktøjer, og udføre sekvenser af API-/værktøjskald for at færdiggøre et job end-to-end. Forbedringer i “agentiske værktøjskald” — modellen vil foreslå en plan, kalde værktøjer (databaser, compute, filsystemer, browser, koderunnere) og syntetisere resultater til en endelig leverance mere pålideligt end tidligere modeller. API’et introducerer routing- og sikkerhedskontroller (lister over tilladte værktøjer, værktøjsskabeloner), og ChatGPT-UI’en kan autoroute forespørgsler til den passende 5.2-variant (Instant vs Thinking).
GPT-5.2 scorede 98.7% i Tau2-Bench Telecom-benchmarket, hvilket demonstrerer modne værktøjskaldsevner i komplekse fleromgangsopgaver.
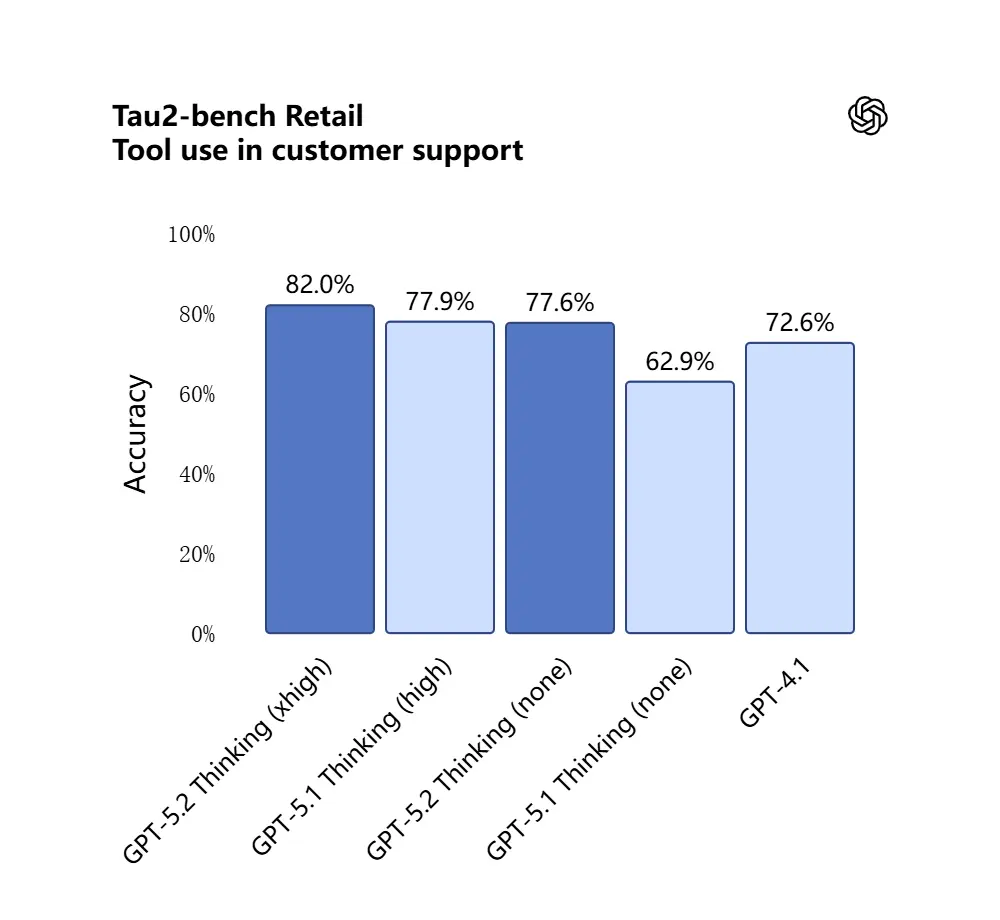
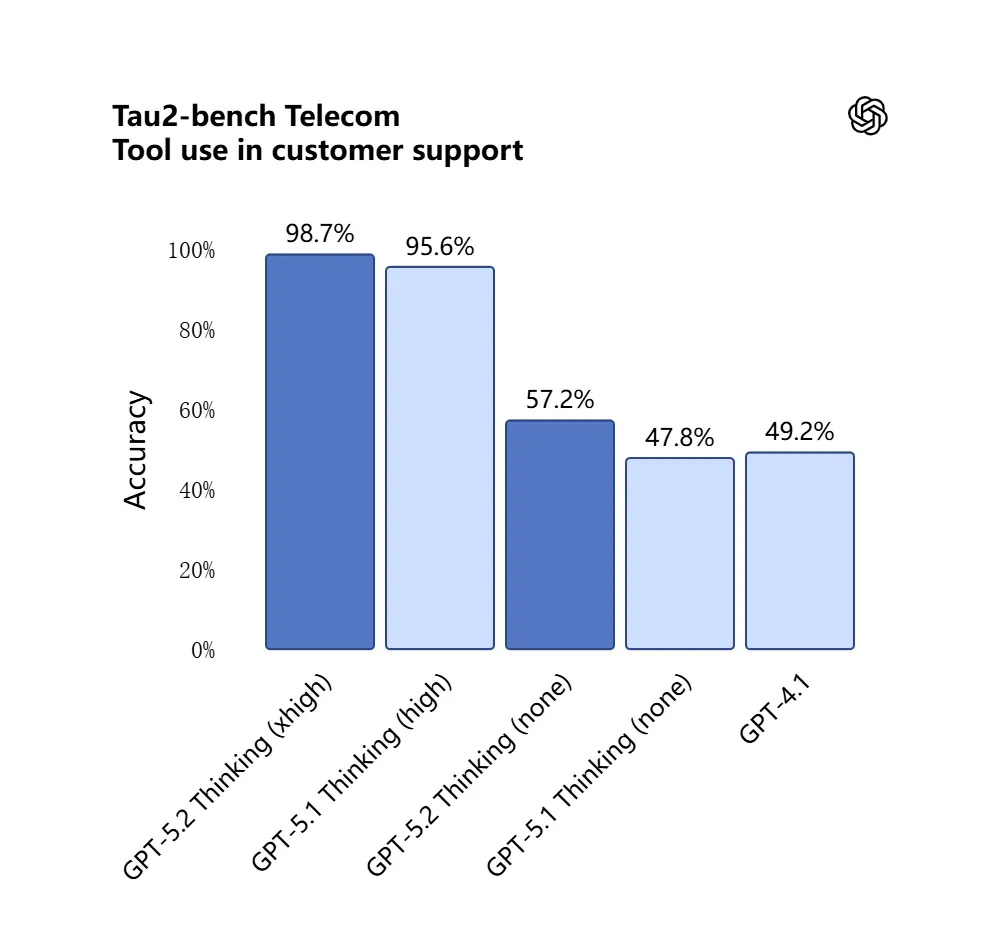
Hvorfor det er vigtigt: dette gør GPT-5.2 mere nyttig som en autonom assistent til workflows som “indlæs disse kontrakter, udtræk klausuler, opdater et regneark og skriv en opsummerende e-mail” — opgaver der tidligere krævede omhyggelig orkestrering.
5) Programmeringsevner udviklet
GPT-5.2 er markant bedre til software engineering-opgaver: den skriver mere komplette moduler, genererer og kører tests mere pålideligt, forstår komplekse projektafhængighedsgrafer og er mindre tilbøjelig til “doven kodning” (at springe boilerplate over eller undlade at forbinde moduler). På branchegrad-benchmarks for kodning (SWE-bench Pro m.fl.) sætter GPT-5.2 nye rekorder. For teams, der bruger LLM’er som makkerprogrammører, kan denne forbedring reducere den manuelle verifikation og efterfølgende omarbejde, der kræves efter generering.
I SWE-Bench Pro-testen (real-world industrielt software engineering-arbejde) steg GPT-5.2 Thinkings score til 55.6%, mens den også opnåede et nyt højdepunkt på 80% i SWE-Bench Verified-testen.
_Software%20engineering.webp)
I praktiske anvendelser betyder det:
- Automatisk debugging af kode i produktionsmiljø giver større stabilitet;
- Understøttelse af programmering på flere sprog (ikke begrænset til Python);
- Evne til selvstændigt at fuldføre end-to-end-reparationsopgaver.
Hvad er forskellene mellem GPT-5.2 og GPT-5.1?
Kort svar: GPT-5.2 er en iterativ men væsentlig forbedring. Den bevarer GPT-5-familiens arkitektur og multimodale fundament, men rykker fire praktiske dimensioner:
- Dybde og konsistens i ræsonnement. 5.2 introducerer højere niveauer for ræsonneringsindsats og bedre kædning for flertrinsproblemer; 5.1 forbedrede ræsonnement tidligere, men 5.2 hæver loftet for kompleks matematik og flertrinslogik.
- Pålidelighed i lang kontekst. Begge versioner udvidede konteksten, men 5.2 er finjusteret til at opretholde nøjagtighed dybt inde i meget lange input (OpenAI hævder forbedret retention op til hundredtusinder af tokens).
- Vision + multimodal fidelitet. 5.2 forbedrer krydsreferencer mellem billeder og tekst — f.eks. at læse et diagram og integrere dataene i et regneark — og viser højere opgaveniveau-nøjagtighed.
- Agentisk værktøjsadfærd og API-funktioner. 5.2 eksponerer nye parametre for ræsonneringsindsats (
xhigh) og kontekstkomprimeringsfunktioner i API’et, og OpenAI har forfinet routing-logikken i ChatGPT, så UI’en automatisk kan vælge den bedste variant. - Færre fejl, større stabilitet: GPT-5.2 reducerer sin “illusion rate” (falsk-svar-rate) med 38%. Den besvarer forsknings-, skrive- og analytiske spørgsmål mere pålideligt og reducerer tilfælde af “fabrikerede fakta.” I komplekse opgaver er dens strukturerede output klarere og dens logik mere stabil. Samtidig er modellens svart sikkerhed markant forbedret i opgaver relateret til mental sundhed. Den præsterer mere robust i følsomme scenarier såsom mental sundhed, selvskade, selvmord og følelsesmæssig afhængighed.
I systemevalueringer scorede GPT-5.2 Instant 0.995 (ud af 1.0) på opgaven “Mental Health Support”, markant højere end GPT-5.1 (0.883).
Kvantitativt viser OpenAIs publicerede benchmarks målbare gevinster på GDPval, matematikbenchmarks (FrontierMath) og software engineering-evalueringer. GPT-5.2 overgår GPT-5.1 i junior-investmentbanking-regnearkopgaver med flere procentpoint.
Er GPT-5.2 gratis — hvad koster det?
Kan jeg bruge GPT-5.2 gratis?
OpenAI rullede GPT-5.2 ud med start på betalte ChatGPT-planer og API-adgang. Historisk har OpenAI holdt de hurtigste/dybeste modeller bag betalingsniveauer, mens lettere varianter gøres bredere tilgængelige senere; med 5.2 sagde virksomheden, at udrulningen ville begynde på betalte planer (Plus, Pro, Business, Enterprise), og at API’et er tilgængeligt for udviklere. Det betyder, at øjeblikkelig gratis adgang er begrænset: det gratis niveau kan senere modtage nedgraderet eller routet adgang (f.eks. til lettere undervarianter), efterhånden som OpenAI skalerer udrulningen.
Den gode nyhed er, at CometAPI nu integrerer med GPT-5.2, og der er i øjeblikket julesalg. Du kan nu bruge GPT-5.2 via CometAPI; playgrounden lader dig frit interagere med GPT-5.2, og udviklere kan bruge GPT-5.2 API’et (CometAPI er prissat til 20% af OpenAIs) til at bygge workflows.
Hvad koster det via API’et (udvikler/produktionsbrug)?
API-brug afregnes pr. token. OpenAIs publicerede platformpriser ved lancering viser (CometAPI er prissat til 20% af OpenAIs):
- GPT-5.2 (standard chat) — $1.75 pr. 1M input-tokens og $14 pr. 1M output-tokens (rabatter for cachet input gælder).
- GPT-5.2 Pro (flagskib) — $21 pr. 1M input-tokens og $168 pr. 1M output-tokens (væsentligt dyrere, fordi den er tiltænkt høj-nøjagtige, compute-tunge workloads).
- Til sammenligning var GPT-5.1 billigere (f.eks. $1.25 ind / $10 ud pr. 1M tokens).
Fortolkning: API-omkostningerne steg i forhold til tidligere generationer; prisen signalerer, at 5.2’s premium-ræsonnement og langkontekst-præstation prissættes som et særskilt produkttier. For produktionssystemer afhænger omkostningerne kraftigt af, hvor mange tokens du inputter/outputter, og hvor ofte du genbruger cachede input (cachede input får store rabatter).
Hvad det betyder i praksis
- For uformel brug via ChatGPT’s UI er månedlige abonnementsplaner (Plus, Pro, Business, Enterprise) hovedvejen. Priserne for ChatGPT-abonnementer ændrede sig ikke med 5.2-udgivelsen (OpenAI holder planpriserne stabile, selv hvis modeltilbuddene ændres).
- For produktion og udviklere: budgetter for token-omkostninger. Hvis din app streamer mange lange svar eller behandler lange dokumenter, vil prissætning for output-tokens ($14 / 1M tokens for Thinking) dominere omkostningerne, medmindre du nøje cacher input og genbruger output.
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI lancerede GPT-5.2 med tre formålsbestemte varianter til at matche brugsscenarier: Instant, Thinking og Pro:
- GPT-5.2 Instant: Hurtig, omkostningseffektiv, finjusteret til hverdagsarbejde — FAQs, how-tos, oversættelser, hurtige udkast. Lav latenstid; gode første udkast og simple workflows.
- GPT-5.2 Thinking: Dybere, højere kvalitet i svar til vedvarende arbejde — langdokumentsammenfatning, flertrinsplanlægning, detaljerede kodegennemgange. Afbalanceret latenstid og kvalitet; standardarbejdshesten til professionelle opgaver.
- GPT-5.2 Pro: Højeste kvalitet og troværdighed. Langsommere og dyrere; bedst til vanskelige, højtstående opgaver (kompleks ingeniørkunst, juridisk syntese, beslutninger med høj værdi) og hvor en ‘xhigh’ ræsonneringsindsats kræves.
Sammenligningstabel
| Egenskab / Metric | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Tiltænkt brug | Hverdagsopgaver, hurtige udkast | Dyb analyse, lange dokumenter | Højeste kvalitet, komplekse problemer |
| Latenstid | Lavest | Moderat | Højest |
| Ræsonneringsindsats | Standard | Høj | xHigh tilgængelig |
| Bedst til | FAQ, tutorials, oversættelser, korte prompt | Resuméer, planlægning, regneark, kodeopgaver | Kompleks ingeniørkunst, juridisk syntese, research |
| API-navneeksempler | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Input-tokenpris (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Output-tokenpris (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Tilgængelighed (ChatGPT) | Rulles ud; betalte planer, derefter bredere | Rulles ud til betalte planer | Pro-brugere / Enterprise (betalt) |
| Typisk brugseksempel | Udkast til e-mail, mindre kodeudsnit | Bygge flerark-regnearksmodeller, Q&A på lang rapport | Auditere kodebase, generere produktionsklar systemdesign |
Hvem egner sig til at bruge GPT-5.2?
GPT-5.2 er designet med en bred vifte af målbrugere i tankerne. Nedenfor er rollebaserede anbefalinger:
Virksomheder og produktteams
Hvis du bygger produkter til vidensarbejde (forskningsassistenter, kontraktgennemgang, analytics-pipelines eller udviklerværktøjer), kan GPT-5.2’s langkontekst og agentiske kapabiliteter reducere integrationskompleksiteten markant. Virksomheder, der har brug for robust dokumentforståelse, automatiseret rapportering eller intelligente copilots, vil finde Thinking/Pro nyttige. Microsoft og andre platformpartnere integrerer allerede 5.2 i produktivitetsstakke (f.eks. Microsoft 365 Copilot).
Udviklere og engineering-teams
Teams, der vil bruge LLM’er som makkerprogrammører eller til at automatisere kodegenerering/testning, vil drage fordel af den forbedrede programmeringsfidelitet i 5.2. API-adgang (med thinking- eller pro-tilstande) muliggør dybere synteser af store kodebaser takket være kontekstvinduet på 400k tokens. Forvent højere API-omkostninger med Pro, men reduktionen i manuel debugging og review kan retfærdiggøre den omkostning for komplekse systemer.
Forskere og data-tunge analytikere
Hvis du regelmæssigt syntetiserer litteratur, parser lange tekniske rapporter eller ønsker modelassisteret forsøgsdesign, hjælper GPT-5.2’s langkontekst og matematikforbedringer med at accelerere workflows. For reproducerbar research bør modellen kobles med omhyggelig prompt engineering og verifikationsskridt.
Små virksomheder og power users
ChatGPT Plus (og Pro for power users) får routet adgang til 5.2-varianter; dette gør avanceret automatisering og høj-kvalitets output tilgængelig for mindre teams uden at bygge en API-integration. For ikke-tekniske brugere, der har brug for bedre dokumentopsummering eller slide-opbygning, leverer GPT-5.2 mærkbar praktisk værdi.
Praktiske noter for udviklere og drift
API-funktioner at holde øje med
reasoning.effort-niveauer (f.eks.medium,high,xhigh) lader dig fortælle modellen, hvor meget compute der skal bruges på internt ræsonnement; brug dette til at afveje latenstid mod nøjagtighed pr. forespørgsel.- Kontekstkomprimering: API’et inkluderer værktøjer til at komprimere og compact’e historik, så reelt relevant indhold bevares i lange kæder. Dette er kritisk, når du skal holde det effektive tokenforbrug håndterbart.
- Værktøjsskabeloner og kontroller for tilladte værktøjer: produktionssystemer bør eksplicit whitelist’e, hvad modellen kan invokere, og logge værktøjskald til revision.
Tips til omkostningskontrol
- Cache ofte brugte dokumentembeds og brug cachede input (som modtager store rabatter) til gentagne forespørgsler mod samme korpus. OpenAIs platformpriser inkluderer betydelige rabatter for cachede input.
- Rute eksplorative/lavværdi-forespørgsler til Instant og brug Thinking/Pro til batch-jobs eller sidste gennemløb.
- Estimér omhyggeligt tokenforbrug (input + output), når du projekterer API-omkostninger, fordi lange outputs multiplicerer omkostningen.
Bundlinje — bør du opgradere til GPT-5.2?
Hvis dit arbejde afhænger af ræsonnement over lange dokumenter, syntese på tværs af dokumenter, multimodal fortolkning (billeder + tekst) eller at bygge agenter der kalder værktøjer, er GPT-5.2 en klar opgradering: den øger den praktiske nøjagtighed og reducerer manuelt integrationsarbejde. Hvis du primært kører højvolumen-chatbots med lav latenstid eller strikt budgetbegrænsede applikationer, kan Instant (eller tidligere modeller) stadig være et fornuftigt valg.
GPT-5.2 repræsenterer et bevidst skift fra “bedre chat” til “bedre professionel assistent”: mere compute, mere kapabilitet og højere pristiers — men også reelle produktivitetsgevinster for teams, der kan udnytte pålidelig langkontekst, forbedret matematik/ræsonnement, billedforståelse og agentisk værktøjsudførelse.
For at komme i gang kan du udforske GPT-5.2;GPT-5.2 pro, GPT-5.2 chat )-modellers kapabiliteter i Playground og konsultere API guide for detaljerede instruktioner. Før adgang, skal du sikre, at du er logget ind på CometAPI og har modtaget API-nøglen. CometAPI tilbyder en pris, der er langt lavere end den officielle, for at hjælpe dig med at integrere.
Klar til at gå i gang?→ Free trial of gpt-5.2 models !