

Kimi K2 Thinking er Moonshot AI's nye "tænkende" variant af Kimi K2-familien: en billionparameter-baseret, sparsom Mixture-of-Experts (MoE)-model, der er eksplicit konstrueret til at tænke mens man handler — dvs. at sammenflette dyb tankekæde-ræsonnement med pålidelige værktøjskald, langsigtet planlægning og automatiserede selvtjek. Det kombinerer en stor, sparsom rygrad (≈1T samlede parametre, ~32B aktiveret pr. token), en native INT4-kvantiseringspipeline og et design, der skalerer. inferens-tid ræsonnement (flere "tænketokens" og flere værktøjsopkaldsrunder) i stedet for blot at øge antallet af statiske parametre.
Kort sagt: K2 Thinking behandler modellen som en problemløsningsmetode agent i stedet for en engangssproggenerator. Det skift – fra "sprogmodel" til "tænkemodel" – er det, der gør denne udgivelse bemærkelsesværdig, og hvorfor mange praktikere ser den som en milepæl inden for open source-agentisk AI.
Hvad er "Kimi K2 Thinking" præcist?
Arkitektur og nøglespecifikationer
K2 Thinking er bygget som en sparsom MoE-model (384 eksperter, 8 eksperter udvalgt pr. token) med ca. 1 billion parametre i alt og ~32 milliarder aktiverede parametre pr. inferens. Den bruger hybride arkitektoniske valg (MLA-opmærksomhed, SwiGLU-aktivering) og blev trænet med Moonshots Muon/MuonClip-optimerer på store token-budgetter, som beskrevet i deres tekniske rapport. Thinking-varianten udvider basismodellen med kvantisering efter træning (native INT4-understøttelse), et 256k kontekstvindue og engineering til at eksponere og stabilisere modellens interne ræsonnementspor under reel brug.
Hvad "tænkning" betyder i praksis
"Tænkning" er her et ingeniørmæssigt mål: at gøre det muligt for modellen at (1) generere lange, strukturerede kæder af intern ræsonnement (chain-of-thought tokens), (2) kalde eksterne værktøjer (søgning, python-sandkasser, browsere, databaser) som en del af denne ræsonnement, (3) evaluere og selvverificere mellemliggende påstande, og (4) iterere på tværs af mange sådanne cyklusser uden at forstyrre sammenhængen. Moonshots dokumentation og modelkort viser, at K2 Thinking er eksplicit trænet og indstillet til at sammenflette ræsonnement og funktionskald og til at opretholde stabil agentisk adfærd på tværs af hundredvis af trin.
Hvad er det centrale mål
Begrænsningerne ved traditionelle storskalamodeller er:
- Genereringsprocessen er kortsynet og mangler tværgående logik;
- Værktøjsbrugen er begrænset (normalt kan kun eksterne værktøjer kaldes én eller to gange);
- De kan ikke selvkorrigere i komplekse problemer.
K2 Thinkings kernedesignmål er at løse disse tre problemer. I praksis kan K2 Thinking, uden menneskelig indgriben: udføre 200-300 på hinanden følgende værktøjskald; opretholde hundredvis af trin med logisk sammenhængende ræsonnement; løse komplekse problemer gennem kontekstuel selvkontrol.
Repositionering: sprogmodel → tænkemodel
K2 Thinking-projektet illustrerer et bredere strategisk skift inden for feltet: at bevæge sig ud over betinget tekstgenerering mod agentiske problemløsereHovedformålet er ikke primært at forbedre forvirring eller forudsigelser af næste token, men at lave modeller, der kan:
- Plan deres egne flertrinsstrategier;
- Koordinere eksterne værktøjer og effektorer (søgning, kodeudførelse, vidensbaser);
- Bekræft mellemresultater og korrektion af fejl;
- Sustain sammenhæng på tværs af lange kontekster og lange værktøjskæder.
Denne omformulering ændrer både evaluering (benchmarks lægger vægt på processer og resultater, ikke kun tekstkvalitet) og ingeniørarbejde (strukturer for værktøjsrouting, trintælling, selvkritik osv.).
Arbejdsmetoder: hvordan tankemodeller fungerer
I praksis demonstrerer K2 Thinking adskillige arbejdsmetoder, der kendetegner "tænkemodel"-tilgangen:
- Vedvarende interne spor: Modellen producerer strukturerede mellemtrin (ræsonnementsspor), der holdes i kontekst og kan genbruges eller revideres senere.
- Dynamisk værktøjsfræsning: Baseret på hvert internt trin beslutter K2, hvilket værktøj der skal kaldes (søgning, kodefortolker, webbrowser), og hvornår det skal kaldes.
- Skalering på testtidspunktet: Under inferens kan systemet udvide sin "tænkedybde" (flere interne ræsonnementstokens) og øge antallet af værktøjskald for bedre at udforske løsninger.
- Selvverifikation og gendannelse: Modellen kontrollerer eksplicit resultater, kører sundhedstests og genplanlægger, når kontrollerne fejler.
Disse metoder kombinerer modelarkitektur (MoE + lang kontekst) med systemudvikling (værktøjsorkestrering, sikkerhedstjek).
Hvilke teknologiske innovationer muliggør Kimi K2 Thinking?
Kimi K2 Thinkings ræsonnementsmekanisme understøtter sammenflettet tænkning og brug af værktøjer. K2 Thinkings ræsonnementsløjfe:
- Forståelse af problemet (parse og abstract)
- Generering af en flertrins ræsonnementsplan (plankæde)
- Brug af eksterne værktøjer (kode, browser, matematikprogram)
- Verifikation og revision af resultaterne (verificering og revision)
- Konkluder argumentation (konkluder argumentation)
Nedenfor vil jeg introducere tre nøgleteknikker, der muliggør ræsonnementsløkkerne i xx.
1) Skalering på testtidspunktet
Hvad er det: Traditionelle "skaleringslove" fokuserer på at øge antallet af parametre eller data under træning. K2 Thinkings innovation ligger i: Dynamisk udvidelse af antallet af tokens (dvs. tankedybde) i "ræsonnementsfasen"; Samtidig udvidelse af antallet af værktøjskald (dvs. handlingsbredde). Denne metode kaldes testtidsskalering, og dens kerneantagelse er: "En længere ræsonnementskæde + flere interaktive værktøjer = et kvalitativt spring i faktisk intelligens."
Hvorfor det er vigtigt: K2 Thinking optimerer eksplicit til dette: Moonshot viser, at udvidelse af "tænketokens" og antallet/dybden af værktøjskald giver målbare forbedringer i agentiske benchmarks, hvilket gør det muligt for modellen at overgå andre modeller af lignende eller større størrelse i FLOP-matchede scenarier.
2) Værktøjsbaseret ræsonnement
Hvad er det: K2 Thinking blev udviklet til indbygget at analysere værktøjsskemaer, autonomt bestemme, hvornår et værktøj skal kaldes, og inkorporere værktøjsresultater tilbage i den løbende ræsonnementsstrøm. Moonshot trænede og justerede modellen til at sammenflette tankekæden med funktionskald og stabiliserede derefter denne adfærd på tværs af hundredvis af sekventielle værktøjstrin.
Hvorfor det er vigtigt: Den kombination – pålidelig parsing + stabil intern tilstand + API-værktøjer – er det, der gør det muligt for modellen at surfe på nettet, køre kode og orkestrere flertrinsarbejdsgange som en del af en enkelt session.
Inden for sin interne arkitektur danner modellen en udførelsestrajektorie for en "visualiseret tankeproces": prompt → ræsonnementstokens → værktøjskald → observation → næste ræsonnement → endeligt svar
3) Langsigtet kohærens og selvverifikation
Hvad er det: Langhorisontkohærens er modellens evne til at opretholde en sammenhængende plan og intern tilstand på tværs af mange trin og over meget lange kontekster. Selvverifikation betyder, at modellen proaktivt kontrollerer sine mellemliggende output og gentager eller reviderer trin, når en verifikation mislykkes. Lange opgaver får ofte modeller til at drive eller hallucinere. K2 Thinking tackler dette med flere teknikker: meget lange kontekstvinduer (256k), træningsstrategier, der bevarer tilstand på tværs af lange CoT-sekvenser, og eksplicitte sætningsniveau-trofastheds-/bedømningsmodeller for at opdage uunderstøttede påstande.
Hvorfor det er vigtigt: Mekanismen "Recurrent Reasoning Memory" opretholder ræsonnementets vedvarende tilstand og giver den menneskelignende "tænkestabilitet" og "kontekstuel selvovervågning"-karakteristika. Da opgaver strækker sig over mange trin (f.eks. forskningsprojekter, kodningsopgaver med flere filer, lange redaktionelle processer), bliver det afgørende at opretholde en enkelt sammenhængende tråd. Selvverifikation reducerer tavse fejl; i stedet for at returnere et plausibelt, men forkert svar, kan modellen opdage uoverensstemmelser og genkonsultere værktøjer eller omplanlægge.
Capabilities:
- Kontekstuel konsistens: Opretholder semantisk kontinuitet på tværs af 10+ tokens;
- Fejldetektion og tilbagerulning: Identificerer og korrigerer logiske afvigelser i tidlige tankeprocesser;
- Selvverifikationsløkke: Verificerer automatisk svarets rimelighed, når ræsonnementet er færdigt;
- Flervejsræsonnement sammenlægning: Vælger den optimale sti fra flere logiske kæder.
Hvad er de fire kernekompetencer i K2 Thinking?
Dyb og struktureret ræsonnement
K2 Thinking er indstillet til at generere eksplicitte, flertrins ræsonnementsspor og bruge dem til at nå frem til robuste konklusioner. Modellen viser stærke scorer på matematiske og rigorøse ræsonnementsbenchmarks (GSM8K, AIME, IMO-stil benchmarks) og demonstrerer en evne til at holde ræsonnement intakt over lange sekvenser - et grundlæggende krav til problemløsning på forskningsniveau. Dens fremragende præstation på Humanity's Last Exam (44.9%) demonstrerer analytiske evner på ekspertniveau. Den kan udtrække logiske rammer fra fuzzy semantiske beskrivelser og generere ræsonnementsgrafer.
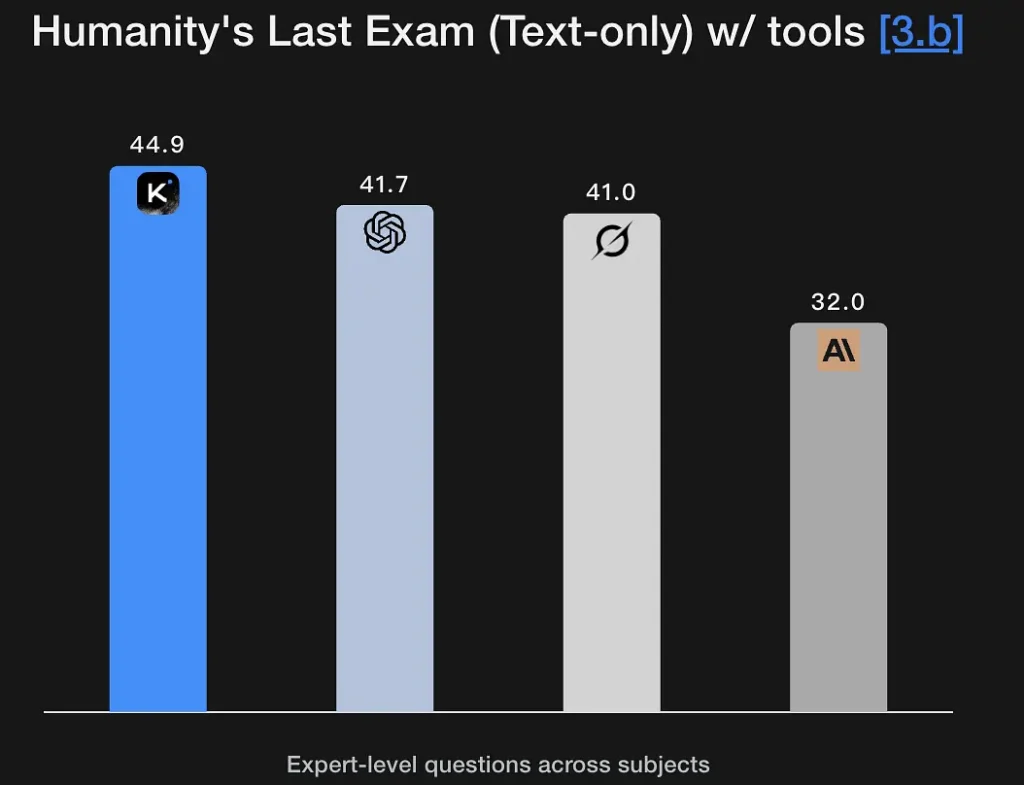
Nøglefunktioner:
- Understøtter symbolsk ræsonnement: Forstår og arbejder med matematiske, logiske og programmeringsstrukturer.
- Besidder hypotesetestningsevner: Kan spontant fremsætte og verificere hypoteser.
- Kan udføre problemnedbrydning i flere trin: Opdeler komplekse mål i flere underopgaver.
Agentsøgning
I stedet for et enkelt hentningstrin lader agentisk søgning modellen planlægge en søgestrategi (hvad man skal kigge efter), udføre den via gentagne web-/værktøjskald, syntetisere de indgående resultater og forfine forespørgslen. K2 Thinkings BrowseComp- og Seal-0-værktøjsaktiverede scorer indikerer stærk ydeevne på denne funktion; modellen er eksplicit designet til at understøtte websøgninger i flere runder med stateful planning.
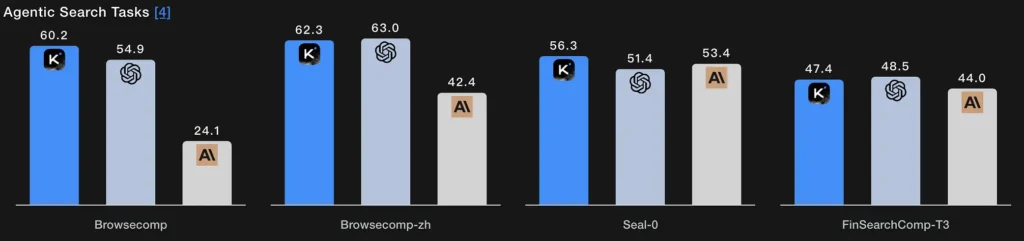
Teknisk essens:
- Søgemodulet og sprogmodellen danner et lukket kredsløb: forespørgselsgenerering → hentning af websider → semantisk filtrering → fusion af ræsonnement.
- Modellen kan adaptivt justere sin søgestrategi, for eksempel ved først at søge efter definitioner, derefter data og til sidst verificere hypoteser.
- Det er i bund og grund en sammensat intelligens af "informationssøgning + forståelse + argumentation".
Agentisk kodning
Dette er evnen til at skrive, udføre, teste og iterere på kode som en del af en ræsonnementsløjfe. K2 Thinking leverer konkurrencedygtige resultater på live-kodnings- og kodeverifikationsbenchmarks, understøtter Python-værktøjskæder i sine værktøjskald og kan køre flertrins-debugging-løkker ved at kalde en sandkasse, læse fejl og reparere kode på tværs af gentagne gennemløb. Dens EvalPlus/LiveCodeBench-scorer afspejler disse styrker. En score på 71.3% i SWE-Bench Verified-testen betyder, at den korrekt kan udføre over 70% af softwarereparationsopgaver i den virkelige verden.
Den demonstrerer også stabil ydeevne i LiveCodeBench V6-konkurrencemiljøet og fremviser dens algoritmeimplementerings- og optimeringsfunktioner.

Teknisk essens:
- Den anvender en proces med "semantisk parsing + AST-niveau refactoring + automatisk verifikation";
- Kodeudførelse og testning opnås via værktøjskald på udførelseslaget;
- Det realiserer en lukket automatiseret udviklingsproces lige fra forståelse af kode → diagnosticering af fejl → generering af patches → verificering af succes.
Agentskrivning
Ud over kreativ prosa er agentisk skrivning struktureret, målrettet dokumentproduktion, der kan kræve ekstern research, citering, tabelgenerering og iterativ forfining (f.eks. producere et udkast → faktatjek → revidere). K2 Thinkings lange kontekst og værktøjsorkestrering gør den velegnet til flertrinsskriveworkflows (research briefs, regelresuméer, indhold med flere kapitler). Modellens åbne sejrsrater på Arena-stil tests og longform-skrivningsmålinger understøtter denne påstand.
Teknisk essens:
- Genererer automatisk tekstsegmenter ved hjælp af agentisk tankeplanlægning;
- Styrer internt tekstlogik gennem ræsonnementstokens;
- Kan samtidig aktivere værktøjer som søgning, beregning og diagramgenerering for at opnå "multimodal skrivning".
Hvordan kan du bruge K2 Thinking i dag?
Adgangsmåder
K2 Thinking er tilgængelig som en open source-udgivelse (modelvægte og kontrolpunkter) og via platformens slutpunkter og community hubs (Hugging Face, Moonshot platform). Du kan selv være vært, hvis du har tilstrækkelig beregningsevne, eller bruge CometAPIs API/hostede brugergrænseflade for hurtigere onboarding. Den dokumenterer også en reasoning_content felt, der viser de interne tanketokens for den, der ringer, når det er aktiveret.
Praktiske tips til brug
- Start med agentbyggesteneneUdfør først et lille sæt deterministiske værktøjer (søgning, Python-sandkasse og en troværdig faktadatabase). Sørg for klare værktøjsskemaer, så modellen kan analysere/validere kald.
- Juster testtidsberegningTil løsning af vanskelige problemer, tillad længere budgetter og flere værktøjsopkaldsrunder; mål hvordan kvaliteten forbedres i forhold til latenstid/omkostninger. Moonshot er fortalere for skalering på testtid som en primær løftestang.
- Brug INT4-tilstande for omkostningseffektivitetK2 Thinking understøtter INT4-kvantisering, som tilbyder meningsfulde hastighedsforøgelser; men validerer edge-case-adfærd på dine opgaver.
- Overfladisk ræsonnementindhold omhyggeligt: afsløring af interne kæder kan hjælpe med fejlfinding, men øger også eksponeringen for fejl i rå modeller. Behandl intern ræsonnement som diagnostisk ikke autoritativ; par det med automatisk verifikation.
Konklusion
Kimi K2 Thinking er et bevidst konstrueret svar på den næste æra af AI: ikke bare større modeller, men agenter der tænker, handler og verificererDet samler MoE-skalering, testtidsberegningsstrategier, native lavpræcisionsinferenser og eksplicit værktøjsorkestrering for at muliggøre vedvarende problemløsning i flere trin. For teams, der har brug for problemløsning i flere trin og har den ingeniørdisciplin, der skal til for at integrere, sandboxe og overvåge agentiske systemer, er K2 Thinking et stort, brugbart skridt fremad – og en vigtig stresstest for, hvordan industri og samfund vil styre stadig mere kapabel, handlingsorienteret AI.
Udviklere kan få adgang Kimi K2 Thinking API gennem Comet API, den nyeste modelversion opdateres altid med den officielle hjemmeside. For at begynde, udforsk modellens muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!