

I et landskab domineret af "skalering-for-enhver-pris"-filosofien—hvor modeller som Flux.2 og Hunyuan-Image-3.0 skubber antallet af parametre op i det massive 30B til 80B-område—er der opstået en ny udfordrer, der forstyrrer status quo. Z-Image, udviklet af Alibaba’s Tongyi Lab, er officielt lanceret og sprænger forventningerne med en slank arkitektur på 6 milliarder parametre, der matcher outputkvaliteten fra industrigiganter, mens den kører på forbrugerhardware.
Udgivet i slutningen af 2025 fangede Z-Image (og den lynhurtige variant Z-Image-Turbo) øjeblikkeligt AI-fællesskabet og overgik 500,000 downloads inden for 24 timer efter debuten. Ved at levere fotorealistiske billeder på blot 8 inferenstrin er Z-Image ikke bare endnu en model; den er en demokratiserende kraft i generativ AI, der muliggør højfidelitets skabelse på bærbare computere, som ville gå i knæ over for konkurrenterne.
Hvad er Z-Image?
Z-Image er en ny, open-source billedgenererings-fundamentsmodel udviklet af forskerholdet Tongyi-MAI / Alibaba Tongyi Lab. Det er en generativ model med 6 milliarder parametre, bygget på en ny Scalable Single-Stream Diffusion Transformer (S3-DiT)-arkitektur, der sammenkæder teksttokens, visuelle semantiske tokens og VAE-tokens i én enkelt behandlingsstrøm. Designmålet er eksplicit: levere fotorealisme i topklasse og god instruktionsefterlevelse, samtidig med at inferensomkostningen reduceres drastisk og praktisk brug på forbrugerhardware muliggøres. Z-Image-projektet udgiver kode, modelvægte og en online demo under en Apache-2.0-licens.
Z-Image leveres i flere varianter. Den mest omtalte udgivelse er Z-Image-Turbo — en destilleret, få-trins version optimeret til udrulning — samt den ikke-destillerede Z-Image-Base (fundaments-checkpoint, bedre egnet til finjustering) og Z-Image-Edit (instruktions-tunet til billedredigering).
"Turbo"-fordelen: 8-trins inferens
Flagskibsvarianten, Z-Image-Turbo, anvender en progressiv destillationsteknik kaldet Decoupled-DMD (Distribution Matching Distillation). Dette gør det muligt for modellen at komprimere genereringsprocessen fra de standard 30-50 trin ned til blot 8 trin.
Resultat: Genereringstider under et sekund på enterprise-GPU’er (H800) og praktisk talt realtidsydelse på forbrugerkort (RTX 4090), uden det "plastiske" eller "udvaskede" udseende, der er typisk for andre turbo/lightning-modeller.
4 nøglefunktioner ved Z-Image
Z-Image er fyldt med funktioner, der henvender sig til både tekniske udviklere og kreative professionelle.
1. Uovertruffen fotorealisme og æstetik
På trods af kun 6 milliarder parametre producerer Z-Image billeder med forbløffende klarhed. Den excellerer i:
- Hudtekstur: Replikering af porer, imperfektioner og naturlig belysning på menneskelige motiver.
- Materialefysik: Nøjagtig gengivelse af glas-, metal- og stofteksturer.
- Belysning: Overlegen håndtering af cinematisk og volumetrisk lys sammenlignet med SDXL.
2. Indbygget tosproget tekstrendering
En af de største smertepunkter i AI-billedgenerering har været tekstrendering. Z-Image løser dette med indbygget support for både engelsk og kinesisk.
- Den kan generere komplekse plakater, logoer og skiltning med korrekt stavning og kalligrafi på begge sprog, en funktion der ofte mangler i vestligt centrerede modeller.
3. Z-Image-Edit: Instruktionsbaseret redigering
Sammen med basismodellen har teamet udgivet Z-Image-Edit. Denne variant er finjusteret til image-to-image-opgaver og giver brugere mulighed for at ændre eksisterende billeder ved hjælp af naturlige sprog-instruktioner (f.eks. "Få personen til at smile", "Skift baggrunden til et snedækket bjerg"). Den bevarer høj konsistens i identitet og belysning under disse transformationer.
4. Tilgængelighed på forbrugerhardware
- VRAM-effektivitet: Kører komfortabelt på 6GB VRAM (med kvantisering) til 16GB VRAM (fuld præcision).
- Lokal kørsel: Understøtter fuldt lokalt deployment via ComfyUI og
diffusers, så brugere frigøres fra afhængighed af cloud.
Hvordan fungerer Z-Image?
Single-stream diffusion transformer (S3-DiT)
Z-Image afviger fra klassiske dual-stream-designs (separate tekst- og billed-encodere/strømme) og sammenkæder i stedet teksttokens, billed-VAE-tokens og visuelle semantiske tokens i et enkelt transformer-input. Denne single-stream-tilgang forbedrer parameterudnyttelsen og forenkler krydsmodal justering i transformer-rygraden, hvilket ifølge forfatterne giver en fordelagtig effektivitet/kvalitets-afvejning for en 6B-model.
Decoupled-DMD og DMDR (destillation + RL)
For at muliggøre få-trins (8-trins) generering uden den sædvanlige kvalitetsstraf udviklede teamet en Decoupled-DMD-destillationstilgang. Teknikken adskiller CFG (classifier-free guidance)-augmentation fra distributionsmatchning, så hver kan optimeres uafhængigt. De anvender derefter et eftertræningsforstærkningslærings-trin (DMDR) for at forfine semantisk alignment og æstetik. Sammen producerer disse Z-Image-Turbo med langt færre NFE’er end typiske diffusionsmodeller, samtidig med at høj realisme bevares.
Træningsgennemløb og omkostningsoptimering
Z-Image blev trænet med en livscyklus-optimeringsmetode: kuraterede datapipelines, et strømlinet pensum og effektivitetsbevidste implementeringsvalg. Forfatterne rapporterer at have fuldført hele træningsarbejdsgangen på cirka 314K H800 GPU-timer (≈ USD $630K) — en eksplicit, reproducerbar ingeniørmålestok, der positionerer modellen som omkostningseffektiv i forhold til meget store (>20B) alternativer.
Benchmark-resultater for Z-Image-modellen
Z-Image-Turbo rangerede højt på flere moderne leaderboards, inklusive en top open-source-position på Artificial Analysis Text-to-Image-leaderboardet og stærk performance på Alibaba AI Arena’s human-preference-evalueringer.
Men virkelighedens kvalitet afhænger også af promptformulering, opløsning, opskaleringspipeline og yderligere efterbehandling.
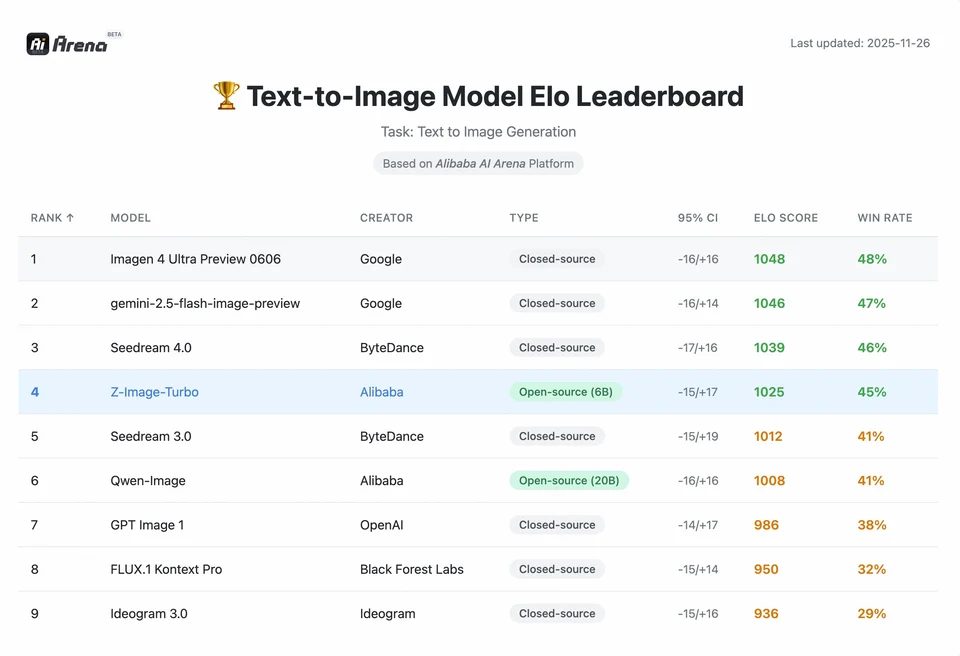
For at forstå størrelsen af Z-Images bedrift må vi se på dataene. Nedenfor er en sammenlignende analyse af Z-Image mod førende open-source- og proprietære modeller.
Sammenlignende benchmark-oversigt
| Feature / Metric | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Architecture | S3-DiT (enkeltstrøm) | MM-DiT (dobbeltstrøm) | U-Net | Diffusions-transformer |
| Parameters | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Inference Steps | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| VRAM Required | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Text Rendering | High (EN + CN) | High (EN) | Moderate (EN) | High (CN + EN) |
| Generation Speed (4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| Photorealism Score | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| License | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
Dataanalyse og performanceindsigter
- Hastighed vs. kvalitet: Mens SDXL Turbo er hurtigere (1-trin), forringes kvaliteten betydeligt ved komplekse prompts. Z-Image-Turbo rammer "sweet spot" ved 8 trin, matcher Flux.2’s kvalitet, mens den er 5x til 10x hurtigere.
- Hardware-demokratisering: Flux.2, selvom den er kraftfuld, er i praksis begrænset til 24GB VRAM-kort (RTX 3090/4090) for rimelig performance. Z-Image gør det muligt for brugere med mid-range-kort (RTX 3060/4060) at generere professionel-grade, 1024x1024-billeder lokalt.
Hvordan kan udviklere tilgå og bruge Z-Image?
Der er tre typiske tilgange:
- Hosted / SaaS (web-UI eller API): Brug tjenester som z-image.ai eller andre udbydere, der deployer modellen og tilbyder en webgrænseflade eller betalt API til billedgenerering. Dette er den hurtigste rute til eksperimenter uden lokal opsætning.
- Hugging Face + diffusers-pipelines: Hugging Face-
diffusers-biblioteket inkludererZImagePipelineogZImageImg2ImgPipelineog giver typiskefrom_pretrained(...).to("cuda")-workflows. Dette er den anbefalede vej for Python-udviklere, der ønsker ligetil integration og reproducerbare eksempler. - Lokal native inferens fra GitHub-repoet: Tongyi-MAI-repoet inkluderer native inferens-scripts, optimeringsmuligheder (FlashAttention, kompilering, CPU-offload) og instruktioner til at installere
diffusersfra kilde for den nyeste integration. Denne rute er nyttig for forskere og teams, der ønsker fuld kontrol eller at køre brugerdefineret træning/finjustering.
Hvordan ser et minimalt Python-eksempel ud?
Nedenfor er et kortfattet Python-snippet, der bruger Hugging Face diffusers og demonstrerer tekst-til-billede-generering med Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Bemærkninger:guidance_scale-defaults og anbefalede indstillinger adskiller sig for Turbo-modeller; dokumentationen foreslår, at guidance kan sættes lavt eller til nul for Turbo afhængigt af den ønskede adfærd.
Hvordan kører du image-to-image (redigering) med Z-Image?
ZImageImg2ImgPipeline understøtter billedredigering. Eksempel:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Dette spejler de officielle brugs-mønstre og er velegnet til kreativ redigering og inpainting-opgaver.
Hvordan bør du gribe prompts og guidance an?
- Vær eksplicit med strukturen: For komplekse scener, strukturer prompts til at inkludere scenekomposition, fokusobjekt, kamera/linse, belysning, stemning og eventuelle tekstlige elementer. Z-Image drager fordel af detaljerede prompts og kan håndtere positionelle/narrative cues godt.
- Tuning af guidance_scale omhyggeligt: Turbo-modeller kan anbefale lavere guidance-værdier; eksperimentation er nødvendig. For mange Turbo-workflows giver
guidance_scale=0.0–1.0med et seed og faste trin konsistente resultater. - Brug image-to-image til kontrollerede ændringer: Når du skal bevare komposition men ændre stil/farvelægning/objekter, start fra et init-billede og brug
strengthtil at styre ændringens størrelse.
Bedste anvendelser og bedste praksis
1. Hurtig prototyping og storyboardning
Use Case: Filminstruktører og gamedesignere skal visualisere scener øjeblikkeligt.
Hvorfor Z-Image? Med generering under 3 sekunder kan skabere iterere gennem hundreder af koncepter i en enkelt session, finjustere belysning og komposition i realtid uden at vente minutter på en render.
2. E-handel og reklame
Use Case: Generering af produktbaggrunde eller lifestyle-billeder til merchandise.
Bedste praksis: Brug Z-Image-Edit.
Upload et råt produktfoto og brug en instruktionsprompt som "Placér denne parfume-flaske på et træbord i en solbeskinnet have." Modellen bevarer produktets integritet og hallucinerer en fotorealistisk baggrund.
3. Tosproget indholdsproduktion
Use Case: Globale marketingkampagner, der kræver assets til både vestlige og asiatiske markeder.
Bedste praksis: Udnyt tekstrenderingskapaciteten.
- Prompt: "A neon sign that says 'OPEN' and '营业中' glowing in a dark alley."
- Z-Image vil korrekt rendere både de engelske og kinesiske tegn, en bedrift som de fleste andre modeller fejler på.
4. Lavressource-miljøer
Use Case: Kørsel af AI-generering på edge-enheder eller almindelige kontor-laptops.
Optimeringstip: Brug INT8-kvantiseringen af Z-Image. Dette reducerer VRAM-forbruget til under 6GB med ubetydeligt kvalitetstab, hvilket gør det muligt for lokale apps på ikke-gaming-bærbare.
Bundlinjen: hvem bør bruge Z-Image?
Z-Image er designet til organisationer og udviklere, der ønsker fotorealisme i høj kvalitet med praktisk latenstid og omkostning, og som foretrækker åben licensering samt on-premises eller brugerdefineret hosting. Den er særligt attraktiv for teams, der har brug for hurtig iteration (kreative værktøjer, produktmockups, realtidsservices) og for forskere/community-medlemmer interesseret i at finjustere en kompakt men kraftfuld billedmodel.
CometAPI tilbyder tilsvarende mindre restriktive Grok Image-modeller, samt modeller som Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) osv.—forudsat at du har de rette NSFW tips og tricks til at omgå restriktionerne og begynde at skabe frit. Før adgang, sørg venligst for, at du er logget ind på CometAPI og har fået API-nøglen. CometAPI tilbyder en pris, der er langt under den officielle pris, for at hjælpe dig med integrationen.
Klar til at gå i gang?→ Free trial for Creating !