

Im Juli 2025 enthüllte Alibaba Qwen3-Coder, das fortschrittlichste Open-Source-KI-Modell, das speziell für komplexe Codierungs-Workflows und agentenbasierte Programmieraufgaben entwickelt wurde. Dieser professionelle Leitfaden führt Sie Schritt für Schritt durch alles, was Sie wissen müssen – vom Verständnis der Kernfunktionen und wichtigsten Innovationen bis hin zur Installation und Nutzung der zugehörigen Qwen-Code CLI-Tool für automatisiertes Coden im Agentenstil. Sie lernen Best Practices, Tipps zur Fehlerbehebung und erfahren, wie Sie Ihre Eingabeaufforderungen und Ressourcenzuweisung optimieren, um Qwen3-Coder optimal zu nutzen.
Was ist Qwen3‑Coder und warum ist es wichtig?
Alibabas Qwen3-Coder ist ein Mixture-of-Experts-Modell (MoE) mit 480 Milliarden Parametern und 35 Milliarden aktiven Parametern, das für großkontextbasierte Codierungsaufgaben entwickelt wurde und nativ 256 Token (und bis zu 1 Million mit Extrapolationsmethoden) verarbeitet. Die Veröffentlichung am 23. Juli 2025 stellt einen großen Fortschritt im „agentischen KI-Coding“ dar. Das Modell generiert nicht nur Code, sondern kann auch komplexe Programmieraufgaben autonom planen, debuggen und iterieren, ohne manuelle Eingriffe.
Wie unterscheidet sich Qwen3‑Coder von seinen Vorgängern?
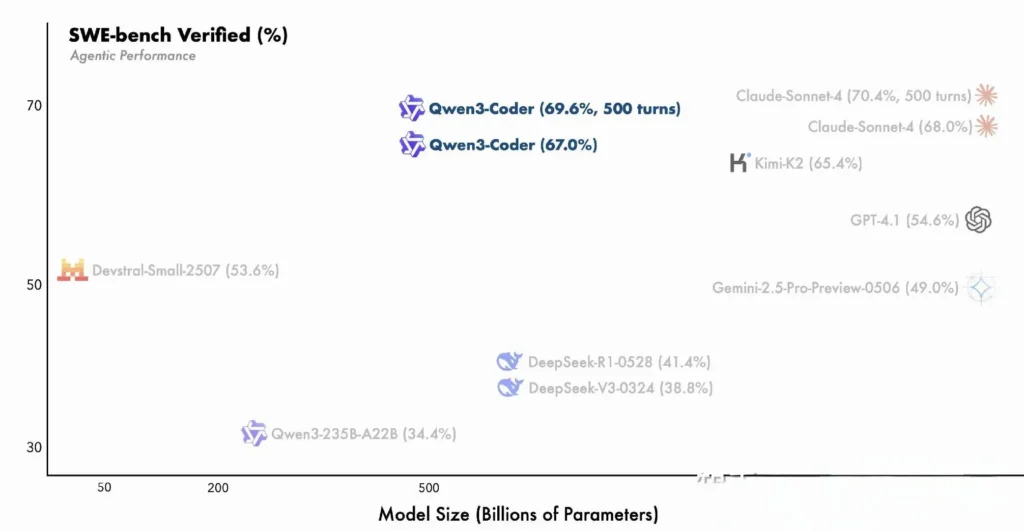
Qwen3-Coder baut auf den Innovationen der Qwen3-Familie auf und integriert sowohl den „Denkmodus“ für mehrstufiges Denken als auch den „Nicht-Denkmodus“ für schnelle Reaktionen in einem einzigen, einheitlichen Framework, das je nach Aufgabenkomplexität dynamisch zwischen den Modi wechselt. Im Gegensatz zum dichten und auf kleinere Kontexte beschränkten Qwen2.5-Coder nutzt Qwen3-Coder eine spärliche „Mixture-of-Experts“-Architektur, um bei Benchmarks wie SWE-Bench Verified und CodeForces ELO-Bewertungen Spitzenleistung zu liefern und Modelle wie Anthropics Claude und OpenAIs GPT-4 in wichtigen Codiermetriken zu erreichen oder zu übertreffen.
Hauptfunktionen von Qwen3‑Coder:
- Riesiges Kontextfenster: 256 Token nativ, bis zu 1 Million durch Extrapolation, wodurch die Verarbeitung ganzer Codebasen oder langer Dokumentationen in einem Durchgang möglich ist.
- Agentenfähigkeiten: Ein dedizierter „Agentenmodus“, der Code autonom planen, generieren, testen und debuggen kann, wodurch der manuelle Entwicklungsaufwand reduziert wird.
- Hoher Durchsatz und Effizienz: Das Mixture-of-Experts-Design aktiviert nur 35 Milliarden Parameter pro Inferenz und sorgt so für ein ausgewogenes Verhältnis zwischen Leistung und Rechenkosten.
- Open‑Source und erweiterbar: Veröffentlicht unter Apache 2.0, mit vollständig dokumentierten APIs und Community-gesteuerten Verbesserungen, die auf GitHub verfügbar sind.
- Mehrsprachig und domänenübergreifend: Trainiert mit 7.5 Billionen Token (70 % Code) in Dutzenden von Programmiersprachen, von Python und JavaScript bis hin zu Go und Rust.
Wie können Entwickler mit Qwen3‑Coder beginnen?
Wo kann ich Qwen3‑Coder herunterladen und installieren?
Sie können die Modellgewichte und Docker-Images von folgender Adresse beziehen:
- GitHub: https://github.com/QwenLM/Qwen3-Coder
- Umarmendes Gesicht: https://huggingface.co/QwenLM/Qwen3-Coder-480B-A35B-Instruct
- Modellumfang: Offizielles Alibaba-Repository
Klonen Sie einfach das Repo und ziehen Sie den vorgefertigten Docker-Container:
git clone https://github.com/QwenLM/Qwen3-Coder.git
cd Qwen3-Coder
docker pull qwenlm/qwen3-coder:latest
Laden des Modells mit Transformatoren
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-480B-A35B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Dieser Code initialisiert das Modell und den Tokenizer und verteilt die Ebenen automatisch auf die verfügbaren GPUs.
Wie konfiguriere ich meine Umgebung?
- Hardware-Anforderungen:
- NVIDIA-GPUs mit ≥ 48 GB VRAM (A100 80 GB empfohlen)
- 128–256 GB System-RAM
-
Abhängigkeiten:
pip install -r requirements.txt # PyTorch, CUDA, tokenizers, etc. -
API-Schlüssel (optional):
Für Cloud‑gehostete Inferenz legen Sie IhreALIYUN_ACCESS_KEYkombiniert mit einem nachhaltigen Materialprofil.ALIYUN_SECRET_KEYals Umgebungsvariablen.
Wie verwenden Sie Qwen Code für die Agentencodierung?
Hier ist eine Schritt-für-Schritt-Anleitung für die Inbetriebnahme von Qwen3‑Coder über das Qwen-Code CLI (einfach aufgerufen als qwen):
1. Voraussetzungen
- Node.js 20+ (Sie können die Installation über das offizielle Installationsprogramm oder über das unten stehende Skript durchführen)
- npm, das im Lieferumfang von Node.js enthalten ist
# (Linux/macOS)
curl -qL https://www.npmjs.com/install.sh | sh
2. Installieren Sie die Qwen Code CLI
npm install -g @qwen-code/qwen-code
Alternativ, um aus der Quelle zu installieren:
git clone https://github.com/QwenLM/qwen-code.git
cd qwen-code
npm install
npm install -g
3. Konfigurieren Sie Ihre Umgebung
Qwen Code verwendet die OpenAI‑kompatibel API-Schnittstelle im Hintergrund. Legen Sie die folgenden Umgebungsvariablen fest:
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
OPENAI_MODEL kann auf einen der folgenden Werte eingestellt werden:
qwen3-coder-plus(Alias zu Qwen3‑Coder-480B-A35B-Instruct)- oder jede andere von Ihnen bereitgestellte Qwen3-Coder-Variante.
4. Grundlegende Verwendung
- Starten Sie ein interaktives Coding-REPL:
qwen
Dadurch gelangen Sie in eine agentenbasierte Codierungssitzung mit Qwen3-Coder.
- Einmalige Eingabeaufforderung von der Shell, um einen Codeausschnitt anzufordern oder eine Funktion abzuschließen:
qwen code complete \
--model qwen3-coder-plus \
--prompt "Write a Python function that reverses a linked list."
- Dateibasierte Codevervollständigung, automatisches Ausfüllen oder Refactoring einer vorhandenen Datei:
qwen code file-complete \
--model qwen3-coder-plus \
--file ./src/utils.js
- Interaktion im Chat-Stil. Verwenden Sie Qwen im „Chat“-Modus, ideal für mehrstufige Codierdialoge:
qwen chat \
--model qwen3-coder-plus \
--system "You are a helpful coding assistant." \
--user "Generate a REST API endpoint in Express.js for user authentication."
Wie rufen Sie Qwen3-Coder über die CometAPI-API auf?
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter – wie die GPT-Reihe von OpenAI, Gemini von Google, Claude von Anthropic, Midjourney, Suno und weitere – in einer einzigen, entwicklerfreundlichen Oberfläche vereint. Durch konsistente Authentifizierung, Anforderungsformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln – CometAPI ermöglicht Ihnen schnellere Iterationen, Kostenkontrolle und Herstellerunabhängigkeit – und gleichzeitig die neuesten Erkenntnisse des KI-Ökosystems zu nutzen.
Wenn Sie ein CometAPI-Benutzer sind, können Sie sich bei Cometapi anmelden, um den Schlüssel und die Basis-URL zu erhalten, und sich bei Cometapi anmelden, um den Schlüssel und die Basis-URL zu erhalten. Weitere Informationen finden Sie unter Qwen3-Coder API.Erkunden Sie zunächst die Fähigkeiten der Modelle in der Spielplatz und konsultieren Sie die API-Leitfaden für detaillierte Anweisungen.
Um Qwen3‑Coder über CometAPI aufzurufen, verwenden Sie dieselben OpenAI‑kompatiblen Endpunkte wie für jedes andere Modell. Richten Sie Ihren Client einfach auf die Basis-URL von CometAPI, präsentieren Sie Ihren CometAPI-Schlüssel als Bearer-Token und geben Sie entweder den qwen3-coder-plus or qwen3-coder-480b-a35b-instruct Modell.
1. Voraussetzungen
- Registrieren at https://cometapi.com und fügen Sie in Ihrem Dashboard ein API-Token hinzu/generieren Sie es.
- Notieren Sie Ihre API-Schlüssel (beginnt mit
sk-…). - Vertrautheit mit dem OpenAI Chat API-Protokoll (Rollen + Nachrichten).
2. Basis-URL und Authentifizierung
Basis-URL:
arduinohttps://api.cometapi.com/v1
Endpunkt:
bashPOST https://api.cometapi.com/v1/chat/completions
3. cURL / REST Beispiel
curl https://api.cometapi.com/v1/chat/completions \
-H "Authorization: Bearer sk-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-coder-plus",
"messages": [
{ "role": "system", "content": "You are a helpful coder." },
{ "role": "user", "content": "Generate a SQL query to find duplicate emails." }
],
"temperature": 0.7,
"max_tokens": 512
}'
- Antwort: JSON mit
choices.message.contententhält den generierten Code.
Wie nutzen Sie die Agentenfunktionen von Qwen3-Coder?
Die agentenbasierten Funktionen von Qwen3-Coder ermöglichen den dynamischen Aufruf von Tools und autonome mehrstufige Arbeitsabläufe, sodass das Modell während der Codegenerierung externe Funktionen oder APIs aufrufen kann.
Toolaufruf und benutzerdefinierte Tools
Definieren Sie benutzerdefinierte Tools wie Linter, Test-Runner oder Formatierer in Ihrer Codebasis und stellen Sie diese dem Modell über Funktionsschemata zur Verfügung. Beispiel:
tools = [
{"name":"run_tests","description":"Execute the test suite and return results","parameters":{}},
{"name":"format_code","description":"Apply black formatter to the code","parameters":{}}
]
response = client.chat.completions.create(
messages=,
functions=tools,
function_call="auto"
)
Qwen3-Coder kann dann in einer Sitzung autonom Code generieren, formatieren und validieren, wodurch der manuelle Integrationsaufwand reduziert wird ().
Verwenden der Qwen Code-CLI
Die qwen-code Das Befehlszeilentool bietet eine interaktive REPL für die agentenbasierte Codierung:
qwen-code --model qwen3-coder-480b-a35b-instruct
> generate: "Create a REST API in Node.js with JWT authentication."
> tool: install_package(express)
> tool: create_file(app.js)
> tool: run_tests
Diese CLI orchestriert komplexe Workflows mit transparenten Protokollen und eignet sich daher ideal für exploratives Prototyping oder die Integration in CI/CD-Pipelines.
Ist Qwen3-Coder für große Codebasen geeignet?
Dank seines erweiterten Kontextfensters kann Qwen3-Coder ganze Repositories – bis zu Hunderttausenden von Codezeilen – verarbeiten, bevor Patches oder Refactorings generiert werden. Diese Funktion ermöglicht globale Refactorings, modulübergreifende Analysen und Architekturvorschläge, die mit kleineren Kontextmodellen einfach nicht möglich sind.
Was sind Best Practices zur Maximierung des Nutzens von Qwen3-Coder?
Die effektive Einführung von Qwen3-Coder erfordert eine durchdachte Konfiguration und Integration in Ihre CI/CD-Pipeline.
Wie sollten Sie die Sampling- und Beam-Einstellungen optimieren?
- Temperatur: 0.6–0.8 für ausgewogene Kreativität; niedriger (0.2–0.4) für deterministische Refactoring-Aufgaben.
- Top‑p: 0.7–0.9, um sich auf die wahrscheinlichsten Fortsetzungen zu konzentrieren und gleichzeitig gelegentlich neue Vorschläge zuzulassen.
- Top‑k: 20–50 für den Standardgebrauch; reduzieren Sie auf 5–10, wenn Sie hochkonzentrierte Ergebnisse wünschen.
- Wiederholungsstrafe: 1.05–1.1, um zu verhindern, dass das Modell Standardmuster wiederholt.
Das Experimentieren mit diesen Parametern im Einklang mit der Abweichungstoleranz Ihres Projekts kann zu erheblichen Produktivitätssteigerungen führen.
Was sind die Best Practices für die effektive Nutzung von Qwen3-Coder?
Schnelles Engineering für Codequalität
- Seien Sie konkret: Geben Sie in Ihrer Eingabeaufforderung Sprache, Stilrichtlinien und gewünschte Komplexität an.
- Iterative Verfeinerung: Verwenden Sie die Agentenfunktionen des Modells, um generierten Code iterativ zu debuggen und zu optimieren.
- Temperaturabstimmung: Senken Sie die Erzeugungstemperatur (zB,
temperature=0.2) für deterministischere Ausgaben in Produktionskontexten.
Verwalten der Ressourcennutzung
- Modellvarianten: Beginnen Sie mit kleineren Qwen3-Coder-Varianten für das Prototyping und skalieren Sie dann nach Bedarf.
- Dynamische Quantisierung: Experimentieren Sie mit quantisierten Prüfpunkten von FP8 und GGUF, um den GPU-Speicherbedarf ohne nennenswerten Leistungsabfall zu reduzieren.
- Asynchrone Generierung: Lagern Sie Codegenerierungen mit langer Laufzeit auf Hintergrundprozesse aus, um die Reaktionsfähigkeit aufrechtzuerhalten.
Durch die Einhaltung dieser Richtlinien stellen Sie sicher, dass Sie den ROI der Integration von Qwen3-Coder in Ihren Softwareentwicklungslebenszyklus maximieren.
Wenn Sie die oben stehenden Anweisungen befolgen, die Architektur verstehen, sowohl das Modell als auch die Qwen Code CLI installieren und konfigurieren und bewährte Methoden anwenden, sind Sie gut gerüstet, um das volle Potenzial von Qwen3‑Coder für alles auszuschöpfen, von einfachen Codeausschnitten bis hin zu vollständig autonomen Programmieragenten.