

In seinen Oktober-Updates berichtete OpenAI, dass etwa 0.15 % der wöchentlich aktiven Benutzer Gespräche führen, die explizite Hinweise auf mögliche Selbstmordpläne oder -absichten enthalten – ein Anteil, der, wenn man ihn auf die große Nutzerbasis von ChatGPT hochrechnet, entspricht mehr als eine Million Menschen pro Woche Durch die Diskussion von Suizid-bezogenen Themen mit dem Dienst wurde eine heikle Frage in den Mittelpunkt gerückt: Können große Sprachmodelle sinnvoll und sicher reagieren, wenn Menschen in einem Chat schwerwiegende psychische Probleme – darunter Psychosen, Manie, Suizidabsichten und tiefe emotionale Abhängigkeit – zur Sprache bringen?
Daher wurden die Oktober-Updates von OpenAI für GPT-5 – die als gpt-5-oct-3 Update – stellt den deutlichsten und konsequentesten Vorstoß des Unternehmens dar, Large Language Models (LLMs) sicherer und nützlicher zu machen, wenn Nutzer psychische Probleme ansprechen. Die Änderungen sind kein Patentrezept; es handelt sich um eine Reihe technischer, prozessualer und evaluativer Maßnahmen, die schädliche oder nicht hilfreiche Ergebnisse reduzieren, professionelle Ressourcen freisetzen und Nutzer davon abhalten sollen, das Modell als Ersatz für klinische Versorgung zu nutzen. Doch wie viel besser ist das System in der Praxis, was genau hat sich geändert und welche Risiken bleiben bestehen?
Was hat OpenAI in gpt-5 aktualisiert und warum ist das wichtig?
OpenAI hat ein Update für ChatGPTs Standard-GPT-5-Modell bereitgestellt (in der Kommunikation häufig als gpt-5-oct-3), die speziell darauf abzielt, das Verhalten des Modells in sensible Gespräche – solche, die Anzeichen einer Psychose oder Manie, Suizidgedanken oder -planungen oder eine Art emotionaler Abhängigkeit von einer KI aufweisen, die reale Beziehungen verdrängen kann.
Die Änderungen basieren auf Konsultationen mit mehr als 170 Experten für psychische Gesundheit sowie auf neuen internen Taxonomien und automatisierten Bewertungen, die auf konkreten „gewünschten Verhaltensweisen“ basieren. Nach der Optimierung durch Psychologieexperten gilt für das GPT-5-Modell:
- Bei gezielten Herausforderungen im Bereich der psychischen Gesundheit erzielte das neue GPT-5-Modell ~ 92% konform mit der gewünschten Verhaltenstaxonomie des Unternehmens (im Vergleich zu viel niedrigeren Prozentsätzen für frühere Versionen bei schwierigen Testsätzen).
- Bei Selbstverletzungs- und Selbstmordszenarien stiegen die automatisierten Auswertungen auf ~ 91% Einhaltung von 77% auf der vorherigen GPT-5-Variante im beschriebenen spezifischen Benchmark. OpenAI berichtet auch ~ 65% Reduzierung der Anzahl von Antworten, die „nicht vollständig übereinstimmen“ in mehreren Bereichen der psychischen Gesundheit im Produktionsverkehr.
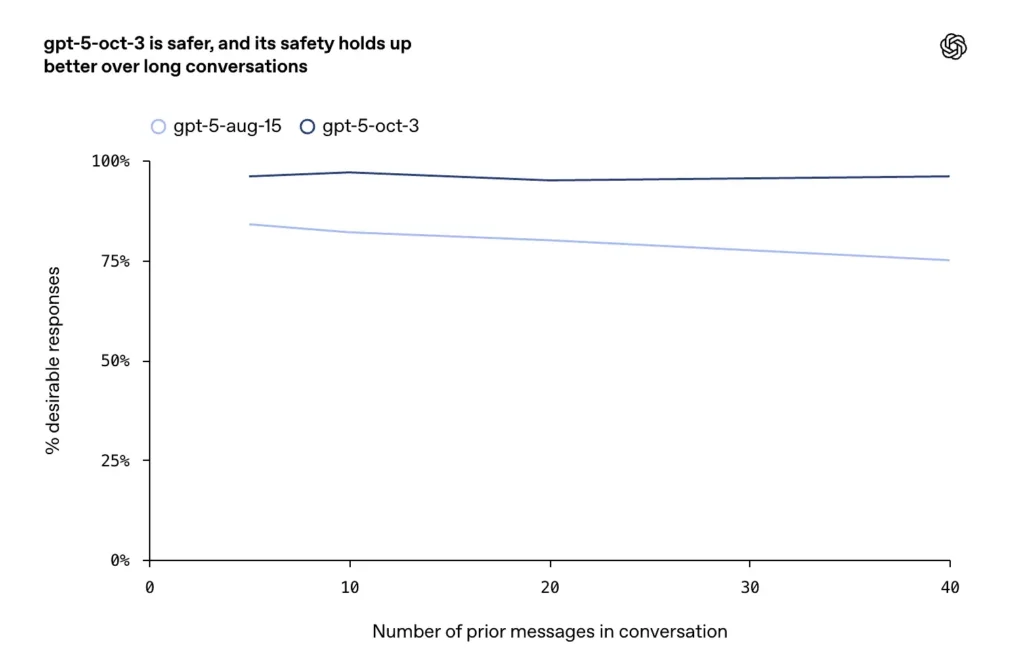
- Es wurden Verbesserungen bei langen, kontroversen oder langwierigen Gesprächen (ein bekannter Fehlermodus für Chat-Modelle) gemeldet. Laut Angaben des Unternehmens sorgen die Oktober-Updates hier für eine höhere Konsistenz und Sicherheit bei längeren Dialogrunden.
warum ist das wichtig
OpenAI erklärte, dass angesichts der aktuellen Größe von ChatGPT selbst sehr kleine Prozentsätze vertraulicher Gespräche einer sehr großen absoluten Personenzahl entsprechen. Das Unternehmen berichtete, dass in einer typischen Woche:
- Über mich 0.07% der aktiven Konsumenten zeigen mögliche Anzeichen einer Psychose oder Manie; und
- Über mich 0.15% der aktiven Nutzer führen Gespräche, die eindeutige Hinweise auf eine mögliche Selbstmordplanung oder -absicht enthalten; und
- rund 0.15% der aktiven Benutzer zeigen eine „erhöhte emotionale Bindung“ zu ChatGPT.
Um diese Prozentsätze konkret zu machen: Der CEO von OpenAI sagte, ChatGPT habe ~800 Millionen wöchentlich aktive BenutzerDurch Multiplikation erhält man die absolute Benutzeranzahl:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Die Kategorien sind unübersichtlich und überlappend (ein einzelnes Gespräch kann in mehreren Kategorien vorkommen) und diese sind Schätzungen abgeleitet aus internen Erkennungstaxonomien und nicht aus klinischen Diagnosen.
Wie hat OpenAI diese Änderungen implementiert – fünfstufiger Verbesserungsmechanismus?
OpenAI beschreibt einen mehrgleisigen, von Experten informierten Prozess. Nachfolgend finden Sie eine destillierte, reproduzierbare Fünf-Stufen-Verbesserungsmechanismus Dies entspricht den Angaben des Unternehmens und der gängigen Praxis im Bereich der Modellsicherheitstechnik.
Fünfstufiger Verbesserungsmechanismus
- Von Experten geleitete Taxonomie und Kennzeichnung. Bringen Sie Psychiater, Psychologen und Hausärzte zusammen, um die Verhaltensweisen und die Sprache zu definieren, die auf Psychose/Manie, Selbstverletzungsabsicht oder ungesunde emotionale Abhängigkeit hinweisen; erstellen Sie beschriftete Datensätze und Beurteilungsregeln.
- Gezielte Datenerfassung und kuratierte Eingabeaufforderungen. Stellen Sie repräsentative Gesprächsausschnitte, Grenzfallbeispiele und kontroverse Beiträge zusammen und ergänzen Sie diese mit kontrollierten Rollenspieltranskripten, die unter Aufsicht eines Klinikers erstellt wurden.
- Modelltuning/Feintuning mit Sicherheitszielen. Trainieren oder optimieren Sie das Basismodell anhand des kuratierten Datensatzes mit Verlusttermen, die die Verstärkung von Wahnvorstellungen bestrafen, Vorlagen für sichere Reaktionen bereitstellen und die Weiterleitung an Krisenressourcen fördern.
- Klassifikator + Leitplankenebene (Laufzeitsicherheit). Setzen Sie einen schnellen Klassifikator oder eine Überwachungsebene ein, die risikoreiche Wendungen in Echtzeit erkennt und entweder die Dekodierungsparameter des Modells ändert, zu einem spezialisierten Responder wechselt oder an menschliche Überprüfungspipelines weiterleitet. (Dies ist entscheidend, um instabiles Verhalten zu vermeiden, wenn die Konversation abdriftet.)
- Bewertung durch menschliche Experten und kontinuierliche Kalibrierung. Lassen Sie Kliniker Modellantworten anhand klinischer Bewertungskriterien blind bewerten. Messen Sie die Häufigkeit unerwünschter Antworten. Iterieren Sie die Taxonomie, die Trainingsdaten und die Systemeingabeaufforderungen. Pflegen Sie die Produktionstelemetrie und führen Sie Benchmarks regelmäßig erneut durch.
Unten sehen Sie eine kompakte Pseudocode-/technische Skizze, die den Laufzeitablauf erfasst, den die meisten Sicherheitsteams implementieren (dies ist illustrativ und nicht proprietär):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Die Produktionspipeline besteht typischerweise aus Kurzzeitklassifizierern (schnell), langsameren, aber qualitativ hochwertigeren Respondern (spezialisierte Eingabeaufforderungen / abgestimmte Kontrollpunkte) und einer menschlichen Überprüfung markierter Fälle. Dies ist nicht rein akademisch: Kliniker überprüften über 1,800 Modellantworten und bewertete sie anhand der Taxonomie, und diese Bewertungen beeinflussten maßgeblich die Art und Weise, wie Eingabeaufforderungen und Fallback-Verhaltensweisen formuliert wurden.
OpenAI gibt in seinen öffentlichen Stellungnahmen an, dass sie Variationen aller fünf Schritte sowie Bewertungen von Klinikern zur Auswertung der Ergebnisse herangezogen haben:
- Experten haben über 1,800 Musterantworten ausgewertet.
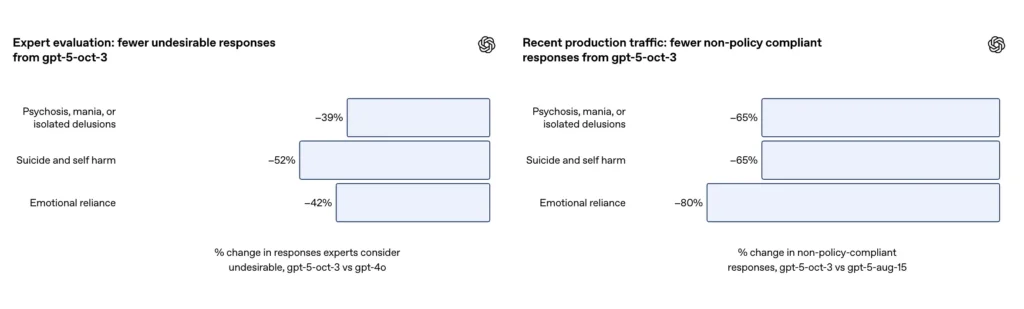
- GPT-5 reduzierte die „unzureichenden Antworten“ in allen Kategorien um 39–52 %.
- Die Interrater-Reliabilität lag zwischen 71 und 77 %, was trotz subjektiver Unterschiede auf einen hohen Grad an allgemeiner Übereinstimmung hinweist.
Wie reagiert GPT-5 nun auf Psychosen oder Manie?
Was OpenAI dem Modell beigebracht hat (und was nicht)
Messen: Die Erkennung und Reaktion des Modells auf schwere Symptome wie Halluzinationen und Manie wurde verbessert. Für Gespräche, die auf mögliche Wahnvorstellungen, Halluzinationen oder Manie hindeuten, hat OpenAI Teile der Modellspezifikation überarbeitet und überwachte Trainingsbeispiele bereitgestellt, sodass GPT-5 reagiert, ohne unbegründete Überzeugungen zu bestätigen oder zu verstärken. Das Modell wird dazu angehalten, empathisch zu sein, Wahnvorstellungen nicht zu bestätigen und den Nutzer gegebenenfalls behutsam auf praktische Sicherheitsmaßnahmen und professionelle Hilfe hinzuweisen.
Was die Auswertung zeigt
OpenAI berichtet, dass das neuere GPT-5 bei einem Testdatensatz mit anspruchsvollen Gesprächen über Psychose/Manie die Anzahl unerwünschter Reaktionen im Vergleich zu früheren Basismodellen erheblich reduziert hat und dass automatisierte Auswertungen dem aktualisierten Modell eine hohe Übereinstimmung mit ihrer Taxonomie bescheinigen.
| Metrisch | GPT-4o | GPT-5 | Verbesserung |
|---|---|---|---|
| Nichtkonformitätsrate | Baseline | ↓ 65% | Deutliche Verbesserung |
| Klinische Expertenbewertung | - | Reduzierung der Nebenwirkungen um 39 % | - |
| Einhaltungsquote der automatischen Bewertung | 27% | 92% | ↑65 Prozentpunkte |
| Nutzerbeteiligungsrate | ~0.07 % wöchentlich aktive Nutzer | Extrem niedrig, aber klar überwacht | - |
Hinweis:
- Unangemessene Reaktionen gingen um 65 % zurück;
- Lediglich 0.07 % der Nutzer und 0.01 % der Nachrichten enthielten solche Inhalte;
- In Expertenbewertungen lieferte GPT-5 39 % weniger unangemessene Antworten als GPT-4o;
- Bei automatisierten Beurteilungen erreichte GPT-5 eine Compliance-Rate von 92 % (gegenüber 27 % beim Vorgängermodell).
Wie geht GPT-5 mit Suizidgedanken und Selbstverletzungen um?
Stärkere Weiterleitung an den Support und Verweigerung der Erteilung von Anweisungen
OpenAI beschreibt ein erweitertes und explizites Training für Fälle von Selbstverletzung und Suizid: Das Modell ist darauf trainiert, direkte und indirekte Anzeichen von Absicht oder Planung zu erkennen, empathische und deeskalierende Sprache zu verwenden, Krisenressourcen (Hotlines, lokale Notfallanweisungen) bereitzustellen und Anweisungen zur Selbstverletzung zu verweigern. Die Aktualisierungen vom Oktober legen Wert auf ein nachhaltigeres Verhalten in längeren Gesprächen, wo frühere Modelle mitunter zu unsicheren oder widersprüchlichen Antworten neigten.
Gemessene Ergebnisse
OpenAI berichtet, dass das aktualisierte GPT-5 in einem sorgfältig zusammengestellten Evaluierungsdatensatz mit anspruchsvollen Gesprächen über Selbstverletzung und Suizid Folgendes erreicht hat: 91 % Konformität mit den von OpenAI gewünschten Verhaltensweisen, verglichen mit 77% für das vorherige GPT-5-Modell. Das Unternehmen gibt außerdem an, dass Fachexperten das aktualisierte Modell als um etwa 100 % reduzierbar für unerwünschte Antworten bewertet haben. 52 % im Vergleich zu GPT-4o auf demselben Aufgabensatz. Darüber hinaus behauptet OpenAI, dass geschätzt 65% Ermäßigung im Produktionsverkehr von Antworten, die nach Einführung der neuen Sicherheitsvorkehrungen „nicht vollständig mit ihrer Taxonomie für Selbstverletzungssituationen übereinstimmen“.
| Metrisch | GPT-4o | GPT-5 | Verbesserung |
|---|---|---|---|
| Unangemessene Antwortrate | Baseline | ↓ 65% | Deutliche Verbesserung |
| Bewertung durch klinische Experten | - | Unangemessene Antworten um 52 % reduziert | - |
| Einhaltungsquote der automatischen Bewertung | 77% | 91% | ↑14 Prozentpunkte |
| Nutzerbeteiligungsrate | 0.15 % wöchentlich (Millionen von Nutzern) | Sehr niedrig, aber gesellschaftlich bedeutsam | - |
Hinweis:
- Unangemessene Reaktionen gingen um 65 % zurück;
- Bei etwa 0.15 % der Nutzer und 0.05 % der Nachrichten bestanden potenzielle Suizidrisiken;
- Expertenbewertungen ergaben, dass GPT-5 unangemessene Reaktionen im Vergleich zu GPT-4o um 52 % reduzierte;
- Die Konformitätsrate bei automatisierten Auswertungen stieg auf 91 % (gegenüber 77 % bei der vorherigen Generation).
- In längeren Gesprächen erreichte GPT-5 eine Stabilität von über 95%.
Was versteht man unter „emotionaler Abhängigkeit“ und wie wurde damit umgegangen?
Die Herausforderung der Bindungsbildung von Nutzern
OpenAI definiert emotionale Abhängigkeit als Verhaltensmuster, bei denen ein Nutzer eine potenziell ungesunde Abhängigkeit von der KI zeigt, die sich nachteilig auf reale Beziehungen, Verantwortlichkeiten oder das eigene Wohlbefinden auswirkt. Dies stellt keine unmittelbare Gefährdung der körperlichen Sicherheit dar, wie etwa Anleitungen zur Selbstverletzung, sondern ist ein Problem der Verhaltenssicherheit, das die sozialen Kontakte und die Resilienz einer Person langfristig schwächen kann. Das Unternehmen hat emotionale Abhängigkeit explizit in die Modellspezifikation aufgenommen und dem Modell beigebracht, reale Kontakte zu fördern, die Kontaktaufnahme zu anderen Menschen zu normalisieren und eine Sprache zu vermeiden, die Exklusivität in der Bindung verstärkt.
In diesen Gesprächen wurde das Modell darauf trainiert:
- Nutzer sollten ermutigt werden, Freunde, Familie oder einen Therapeuten zu kontaktieren;
- Vermeiden Sie es, die Bindung an die KI zu verstärken;
- Reagiere auf Wahnvorstellungen oder falsche Überzeugungen mit Sanftmut und Rationalität.
Ergebnisse gemeldet
Laut OpenAI-Nachtrag führte das Update zu einem ~80 % Reduzierung in der Rate der Modellantworten, die im Produktivverkehr nicht vollständig der Taxonomie der emotionalen Abhängigkeit entsprechen. In kuratierten Bewertungsgesprächen bewertete die automatisierte Auswertung das aktualisierte Modell mit 97 % Konformität Die Trefferquote für erwünschtes Verhalten in Szenarien emotionaler Abhängigkeit lag bei 50 % im Vergleich zum Vorgängermodell GPT-5. Die Zahlen deuten auf eine deutliche Verbesserung der spezifischen Taxonomie und des Testsets hin; allerdings ist die Messung emotionaler Abhängigkeit im Alltag naturgemäß ungenau und anfällig für kulturelle und kontextuelle Unterschiede.
| Metrisch | GPT-4o | GPT-5 | Verbesserung |
|---|---|---|---|
| Nichtkonformitätsrate | 50% | 97% konform | ↓80 % unangemessene Antworten |
| Expertenbewertung | Unangemessene Antworten um 42 % reduziert | - | - |
| Nutzerbeteiligungsrate | 0.15 % Nutzer/Woche, 0.03 % Nachrichten | Selten, aber es existiert | - |
| Modellverhalten | Fördert reale Beziehungen; lehnt „simulierte soziale Romantik“ ab | - | - |
Hinweis:
- Unangemessene Reaktionen gingen um 80 % zurück;
- Bei etwa 0.15 % der Nutzer bzw. 0.03 % der Nachrichten zeigten sich Anzeichen einer möglichen emotionalen Abhängigkeit von der KI;
- Eine Expertenbeurteilung ergab, dass GPT-5 unangemessene Reaktionen im Vergleich zu GPT-4o um 42 % reduzierte;
- Die Einhaltung der automatisierten Bewertungsrichtlinien verbesserte sich signifikant von 50 % auf 97 %.
Welche Grenzen und Risiken bestehen?
Falsch negative und falsch positive Ergebnisse
- Falsch negativeDas Modell erkennt möglicherweise keine subtilen oder kodierten Signale, die auf eine akute Gefahrenlage für den Nutzer hinweisen – insbesondere dann nicht, wenn die Kommunikation indirekt oder verschlüsselt erfolgt.
- FehlalarmDas System könnte in Fällen, die nicht erforderlich sind, eskalieren oder Krisenmeldungen versenden, was das Vertrauen der Nutzer untergraben oder unnötige Beunruhigung auslösen kann. Beide Fehlertypen sind relevant, da sie das Nutzerverhalten und die Wahrnehmung der Fürsorge beeinflussen. OpenAI räumt ein, dass die Erkennung nicht perfekt ist.
Übermäßiges Vertrauen in die Automatisierung
Selbst die besten Modelle können manche Nutzer dazu verleiten, sich auf sofortige, jederzeit verfügbare KI-Antworten zu verlassen, anstatt dauerhafte menschliche Unterstützung zu suchen. OpenAI kennzeichnet emotionale Abhängigkeit aufgrund dieses Risikos ausdrücklich als Sicherheitskategorie; die Updates des Unternehmens versuchen, Nutzer zu menschlicher Interaktion zu bewegen, doch soziale Dynamiken lassen sich allein durch Nachrichtenaufforderungen nur schwer verändern.
Kontextuelle und kulturelle Unterschiede
Sicherheitsformulierungen, die in einer Kultur oder Sprache angemessen erscheinen, können in einer anderen Kultur oder Sprache Nuancen verkennen. Eine sorgfältige Lokalisierung und kultursensible Evaluierung sind daher unerlässlich; die veröffentlichten Ergebnisse von OpenAI liefern noch keine vollständigen Aufschlüsselungen nach Sprache oder Region.
Rechtliche und ethische Verantwortung
Wenn seltene Fehler schwerwiegende Folgen haben, sind Unternehmen rechtlichen und Reputationsrisiken ausgesetzt (wie Medienberichte und Gerichtsverfahren gezeigt haben). OpenAIs Transparenz hinsichtlich des Ausmaßes des Problems und seiner Bemühungen zur Schadensbegrenzung ist ein wichtiger Schritt, zieht aber auch regulatorische und rechtliche Prüfungen nach sich.
Kann GPT-5 also jetzt auch psychische Probleme behandeln?
Kurze Antwort: **Bei vielen eng gefassten, messbaren Aufgaben ist es deutlich besser.**Die von OpenAI veröffentlichten Metriken belegen signifikante Reduzierungen unerwünschter Reaktionen in Testreihen zu Selbstverletzung, Psychose/Manie und emotionaler Abhängigkeit. Dies sind echte Verbesserungen, die durch Expertenwissen, klarere Taxonomien sowie eine konsequente Evaluierung und Überwachung ermöglicht wurden. Die öffentlich zugänglichen Zahlen des Unternehmens – hohe Konformitätsraten und deutliche Reduzierungen nicht konformer Reaktionen in kuratierten Datensätzen – sind der bisher stärkste Beweis dafür, dass gezielte, multidisziplinäre Zusammenarbeit in Entwicklung und Klinik das Verhalten von Modellen grundlegend verändern kann.
Wie erhalte ich Zugriff auf die neueste GPT-5-API?
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter – wie die GPT-Reihe von OpenAI, Gemini von Google, Claude von Anthropic, Midjourney, Suno und weitere – in einer einzigen, entwicklerfreundlichen Oberfläche vereint. Durch konsistente Authentifizierung, Anforderungsformatierung und Antwortverarbeitung vereinfacht CometAPI die Integration von KI-Funktionen in Ihre Anwendungen erheblich. Ob Sie Chatbots, Bildgeneratoren, Musikkomponisten oder datengesteuerte Analyse-Pipelines entwickeln – CometAPI ermöglicht Ihnen schnellere Iterationen, Kostenkontrolle und Herstellerunabhängigkeit – und gleichzeitig die neuesten Erkenntnisse des KI-Ökosystems zu nutzen.
Entwickler können zugreifen GPT-5-API über CometAPI, die neuste Modellversion wird immer mit der offiziellen Website aktualisiert. Erkunden Sie zunächst die Fähigkeiten des Modells in der Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bieten einen Preis weit unter dem offiziellen Preis an, um Ihnen bei der Integration zu helfen.
Bereit loszulegen? → Melden Sie sich noch heute für CometAPI an !
Wenn Sie weitere Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X kombiniert mit einem nachhaltigen Materialprofil. Discord!