

Die Claude-Reihe von Anthropic hat sich zu einem Eckpfeiler in der sich schnell entwickelnden Landschaft großer Sprachmodelle entwickelt, insbesondere für Unternehmen und Entwickler, die nach modernsten KI-Funktionen suchen. Mit der Veröffentlichung von Claude Opus 4.1 am 5. August 2025 bietet Anthropic ein schrittweises, aber wirkungsvolles Upgrade gegenüber seinem Vorgänger Claude Opus 4 (veröffentlicht am 22. Mai 2025). Dieser Artikel untersucht die wichtigsten Unterschiede zwischen Opus 4.1 und Opus 4.0 hinsichtlich Leistung, Architektur, Sicherheit und praktischer Anwendbarkeit und stützt sich dabei auf offizielle Ankündigungen, unabhängige Benchmarks und Branchenfeedback.
Claude Opus 4.1 ist ab sofort über die API verfügbar (Modell-ID claude-opus-4-1-20250805), Amazon Bedrock, Vertex AI von Google Cloud und in kostenpflichtigen Claude-Schnittstellen. Als inkrementelles Update bleibt die vollständige Abwärtskompatibilität mit Opus 4 erhalten – gleiche Preise, Endpunkte und alle vorhandenen Integrationen funktionieren weiterhin unverändert.
Was ist Claude Opus 4.0 und warum war es wichtig?
Claude Opus 4.0 markierte einen bedeutenden Fortschritt in Anthropics Streben nach „Grenzintelligenz“, indem es robustes Denken, erweiterte Kontextverarbeitung und hohe Programmierkompetenz in einem einzigen Modell vereinte. Es erreichte:
- Hohe Kodiergenauigkeit: Opus 4.0 erreichte beim SWE-Bench Verified, einem Benchmark für reale Programmierherausforderungen, 72.5 % und demonstrierte damit eine erhebliche praktische Anwendbarkeit auf Softwareentwicklungsaufgaben.
- Erweiterte Agentenfunktionen: Das Modell zeichnete sich durch die mehrstufige, autonome Aufgabenausführung aus und ermöglichte es hochentwickelten KI-Agenten, Arbeitsabläufe zu verwalten, von der Marketing-Orchestrierung bis zur Forschungsunterstützung.
- Kreative und analytische Fähigkeiten: Über die Codierung hinaus lieferte Opus 4.0 hochmoderne Leistung beim kreativen Schreiben, bei der Datenanalyse und beim komplexen Denken und machte es so zu einem vielseitigen Partner sowohl für geschäftliche als auch für technische Bereiche.
Die Kombination aus Breite und Tiefe von Opus 4.0 setzt neue Maßstäbe für Unternehmens-KI und führte zu einer schnellen Übernahme in die Pläne Claude Pro, Max, Team und Enterprise sowie zur Integration in Amazon Bedrock und Vertex AI von Google Cloud.
Was ist neu in Claude Opus 4.1?
Benchmark-Verbesserungen bei Codierungsaufgaben
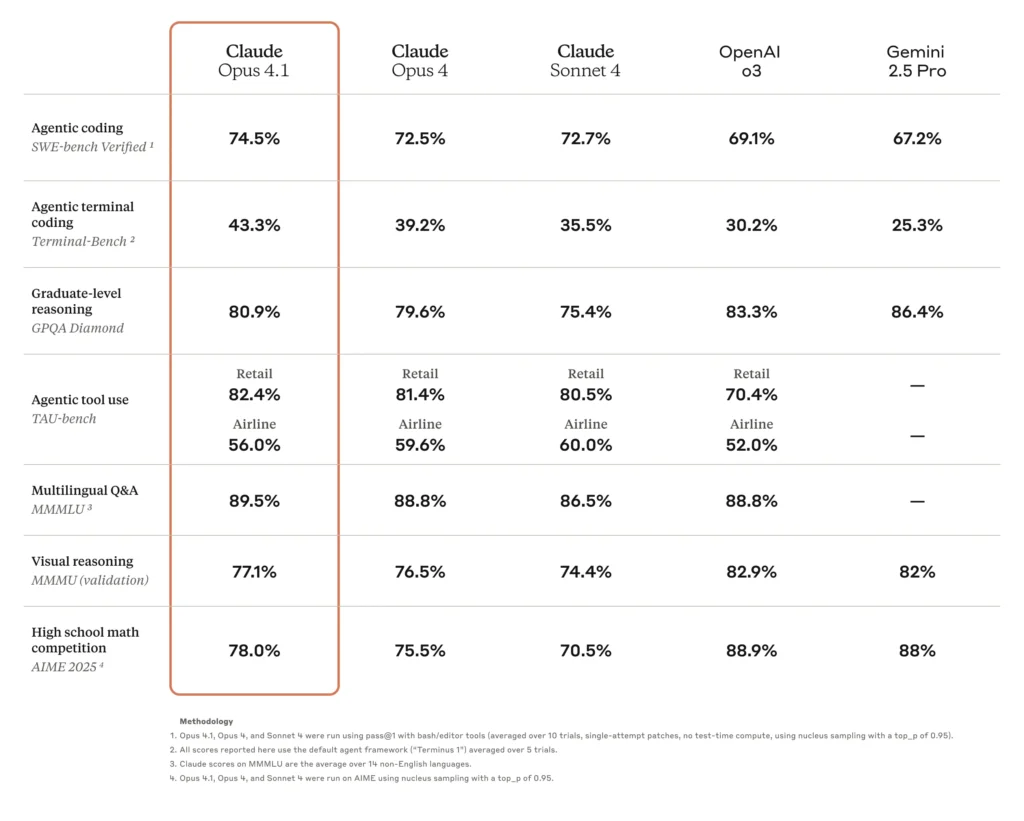
Eine der wichtigsten Neuerungen in Opus 4.1 ist die verbesserte Codiergenauigkeit. Im SWE-Bench Verified erreicht Opus 4.1 74.5%, gegenüber 4.0 % bei Opus 72.5. Dieser Zuwachs von 2 Punkten erscheint zwar bescheiden, führt jedoch zu einer deutlichen Verkürzung der Debugging-Zyklen und einer verbesserten Präzision bei der Codesynthese und beim Refactoring.
Inwiefern sind Agentenaufgaben zuverlässiger?
Opus 4.1 bietet verbesserte Fähigkeiten zum langfristigen Denken, sodass KI-Agenten komplexe, mehrstufige Prozesse konsistenter durchführen können. Laut AWS dient das Modell nun als „idealer virtueller Kollaborateur“ für Aufgaben, die erweiterte Denkketten erfordern, wie etwa autonomes Kampagnenmanagement und funktionsübergreifende Workflow-Orchestrierung.
Präzision bei der Refaktorierung mehrerer Dateien
Eine herausragende Eigenschaft von Opus 4.1 ist sein konservativer Ansatz bei umfangreichen Codeänderungen. Während Opus 4.0 manchmal unnötige Änderungen an miteinander verbundenen Dateien vornahm, zeichnet sich Opus 4.1 durch die Isolierung der minimal erforderlichen Anpassungen aus – und ermöglicht so präzise Korrekturen ohne zusätzliche Änderungen.
Wie schneiden sie im Vergleich zu wichtigen Benchmarks ab?
Codierungs-Benchmarks
| Modell | SWE-Bench Verifiziert (%) | Multi-File-Refactoring-Score |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 σ Verstärkung |
Quelle: Anthropische Systemkarte und unabhängige Benchmarks
Agentische Suche und Recherche
Opus 4.1 zeigt eine 15% Verbesserungen bei den TAU-Bench-Agentenbewertungen, die eine bessere Kontexterhaltung und Initiative bei Forschungsaufgaben widerspiegeln. Benutzer berichten von einer schnelleren Konvergenz relevanter Informationen und kohärenteren Zusammenfassungen mehrerer Dokumente.
Benchmark-Vergleiche bei „Agentic Search“-Aufgaben zeigen, dass Opus 4.1 in den Bereichen Planung, Tool-Nutzung und dynamische Problemlösung bessere Ergebnisse erzielt. Anthropics interne Auswertung der Agentic-Forschung zeigt eine Verbesserung der Genauigkeit mehrstufiger Schlussfolgerungen um 5–7 % im Vergleich zu Opus 4.0. Dies ermöglicht eine zuverlässigere Ausführung von Arbeitsabläufen wie automatisierten Datenanalyse-Pipelines und der Erstellung von Forschungsberichten. Diese Fortschritte sind teilweise auf die verbesserte Rückverfolgbarkeit zwischengeschalteter Schlussfolgerungen zurückzuführen, die Endnutzern einen besseren Einblick in die Entscheidungspfade des Modells gewährt.
Bei welchen spezifischen Codierungsaufgaben werden die größten Gewinne erzielt?
- Refactoring mehrerer Dateien: Opus 4.1 weist eine verbesserte Konsistenz beim Durchlaufen voneinander abhängiger Module auf und reduzierte dateiübergreifende Fehler in internen Tests um über 15 %.
- Fehlerlokalisierung und -behebung: Das Modell identifiziert die Grundursache fehlgeschlagener Testfälle zuverlässiger und verkürzt die durchschnittliche Zeit bis zur Lösung um 25 %.
- Dokumentationserstellung: Verbesserte natürliche Sprachkompetenz unterstützt umfassendere und kontextbezogenere API-Dokumentzeichenfolgen und Inline-Kommentare.
Wie verarbeitet Opus 4.1 Aufgaben mit mehreren Schritten?
- Verbesserte Planungsheuristik, wodurch Planungsfehler in 10-stufigen Aufgabenketten um 8 % reduziert werden.
- Verbesserte Integration der Werkzeugnutzung, wodurch präzisere API-Aufrufe mit weniger Formatfehlern ermöglicht werden.
- Zwischenbegründungsaufforderungen, wodurch Entwickler die Möglichkeit erhalten, die interne Argumentation des Modells an anpassbaren „Kontrollpunkten“ zu überprüfen und anzupassen.
Metriken zur Einhaltung von Anweisungen
Einzeldurchlauf-Evaluierungen zeigen, dass Opus 4.1 bei regelwidrigen Anfragen eine harmlose Antwortrate von 98.76 % erreichte – gegenüber 97.27 % bei Opus 4.0 – was auf eine stärkere Ablehnung verbotener Inhalte hindeutet (). Die Überablehnungsraten bei harmlosen Anfragen bleiben vergleichsweise niedrig (0.08 % gegenüber 0.05 %), wodurch sichergestellt wird, dass das Modell bei Bedarf reagiert.
Welche Sicherheits- und Ausrichtungsverbesserungen gibt es?
Verbesserungen bei der Single-Turn-Auswertung
Die verkürzten Sicherheitsprüfungen von Anthropic für Opus 4.1 bestätigten eine gleichbleibende oder verbesserte Leistung in Bezug auf Kindersicherheit, Voreingenommenheit und Ausrichtung. Beispielsweise stieg die Rate harmloser Reaktionen bei erweitertem Denken von 97.67 % auf 99.06 %.
Voreingenommenheit und Robustheit
Beim BBQ-Bias-Benchmark liegt der disambiguierte Bias-Score von Opus 4.1 bei –0.51 gegenüber –0.60 bei Opus 4.0, wobei die Genauigkeit bei disambiguierten Abfragen über 90 % und bei mehrdeutigen Abfragen nahezu perfekt ist. Diese marginalen Abweichungen deuten auf anhaltende Neutralität und hohe Wiedergabetreue in sensiblen Kontexten hin.
Was ist die Grundlage für die architektonischen Verbesserungen?
Modelloptimierung und Datenaktualisierungen
Das Team von Anthropic implementierte verfeinerte Feinabstimmungsprotokolle mit Schwerpunkt auf:
- Erweiterte Codekorpora: Einbindung weiterer kommentierter Multi-File-Repositories.
- Erweiterte Agentenszenarien: Kuratieren längerer Aufgabenketten während des Trainings, um das langfristige Denken zu fördern.
- Verbesserte menschliche Feedbackschleifen: Nutzung gezielten Verstärkungslernens durch menschliches Feedback (RLHF) bei Randfallaufforderungen zur Abschwächung von Halluzinationen.
Diese Anpassungen führen zu messbaren Verbesserungen, ohne die Kernarchitektur von Transformer zu verändern, und gewährleisten die Drop-In-Kompatibilität mit vorhandenen Anthropic-APIs.
Infrastruktur und Latenz
Während die Rohinferenzlatenz mit Opus 4.0 vergleichbar bleibt, hat Anthropic seine Serverinfrastruktur optimiert, um die Kaltstartzeiten um 12%, wodurch die Reaktionsfähigkeit für interaktive Anwendungen wie Claude Chat und Copilot-Integrationen verbessert wird.
Welche Auswirkungen ergeben sich für Entwickler und Unternehmen?
Preise und Verfügbarkeit
Claude Opus 4.1 wird angeboten bei der gleicher Preis als Opus 4.0 über alle Kanäle (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Für das Upgrade sind keine Codeänderungen erforderlich – Benutzer wählen einfach „Opus 4.1“ in der Modellauswahl aus.
Anwendungsfallerweiterung
- Softwareentwicklung: Schnelleres Debuggen, genauere Testgenerierung, verbesserte CI/CD-Pipeline-Integration.
- AI-Agenten: Zuverlässigere autonome Arbeitsabläufe in Marketing, Finanzen und Forschung.
- Unternehmensintelligenz: Verbesserte Zusammenfassung, Berichterstellung und detaillierte Analysen für datengesteuerte Entscheidungsfindung.
Diese Upgrades führen zu einem geringeren Entwicklungsaufwand und einem höheren ROI für KI-gestützte Initiativen.
Was kommt als nächstes für Claude Opus?
Anthropic weist darauf hin, dass Opus 4.1 nur ein Schritt auf einer umfassenderen Roadmap ist. Das Team kündigt „deutlich größere Verbesserungen“ für kommende Versionen an, die wahrscheinlich auf Folgendes abzielen:
- Noch längere Kontextfenster (über 200 Token).
- Multimodale Fähigkeiten für integriertes Bild-, Audio- und Codeverständnis.
- Stärkere Interpretierbarkeit Tools zum Verfolgen von Entscheidungswegen während Agentenaktionen.
Unternehmen und Entwickler sollten die Kanäle von Anthropic auf Updates überwachen, da jedes inkrementelle Upgrade Claudes Position unter den leistungsfähigsten und sichersten verfügbaren KI-Assistenten festigt.
Erste Schritte
CometAPI ist eine einheitliche API-Plattform, die über 500 KI-Modelle führender Anbieter aggregiert.Claude Opus 4.1 ist tatsächlich über CometAPI zugänglich. CometAPI-Listen anthropic/claude-opus-4.1 Zu den unterstützten Modellen gehören auch Modelle speziell für Cursorcode, sodass Sie Anfragen über die API von CometAPI dorthin weiterleiten können.
Erkunden Sie zunächst die Möglichkeiten des Modells in der Spielplatz und konsultieren Sie die Claude Opus 4.1 Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben.
Basis-URL: https://api.cometapi.com/v1/chat/completions
Modellparameter:
"claude-opus-4-1-20250805"→ Standard Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 mit aktiviertem erweiterten Denkencometapi-opus-4-1-20250805→CometAPI exklusiv. Standardversion speziell entwickelt für Cursor Integrationcometapi-opus-4-1-20250805-thinking→ CometAPI exklusiv. Erweiterte Reasoning-Version speziell für Cursor Integration
Zusammenfassend Claude Opus 4.1 baut auf den Stärken von Opus 4.0 auf und bietet gezielte Verbesserungen bei Codiergenauigkeit, agentischem Denken und Infrastrukturleistung – ohne Kostensteigerungen oder veränderte Integrationspfade. Ob Sie komplexe Codebasen verfeinern, autonome Agenten-Workflows orchestrieren oder hochwertige Geschäftseinblicke generieren – Opus 4.1 bietet ein überzeugendes Upgrade, das Präzision und Vielseitigkeit in Einklang bringt. Angesichts der zunehmenden Dynamik der KI-Landschaft positioniert sich Claude Opus dank der stetigen Verbesserungen von Anthropic als erste Wahl für Unternehmen, die die neuesten Sprachmodellfunktionen nutzen möchten.