

Anthropics neue Claude 4-Familie – Claude Opus 4 kombiniert mit einem nachhaltigen Materialprofil. Claude Sonnet 4 – wurden im Mai 2025 als KI-Assistenten der nächsten Generation angekündigt, die für fortgeschrittenes Denken und Kodieren optimiert sind. Opus 4 wird als Anthropics „das bisher leistungsstärkste Modell“, hervorragend geeignet für komplexe, mehrstufige Codierungs- und Denkaufgaben. Sonnet 4 ist ein leistungsstarkes Upgrade des Vorgängers Sonnet 3.7 und bietet starke allgemeine Denkfähigkeiten, präzises Befolgen von Anweisungen und wettbewerbsfähige Codierfähigkeiten.
Im Folgenden vergleichen wir diese Modelle anhand wichtiger technischer Aspekte für Entwickler: Argumentations- und Codierleistung, Latenz und Effizienz, Qualität der Codegenerierung, Transparenz, Tool-Nutzung, Integrationen, Kosten-Leistungs-Verhältnis, Sicherheit und Anwendungsfälle für die Bereitstellung. Die Analyse basiert auf Ankündigungen und Dokumentationen von Anthropic, unabhängigen Benchmarks und Branchenberichten, um einen umfassenden und aktuellen Überblick zu bieten.
Was sind Claude Opus 4 und Claude Sonett 4?
Claude Opus 4 und Claude Sonnet 4 sind die neuesten Mitglieder der Claude 4-Familie von Anthropics. Sie wurden als hybride Sprachmodelle konzipiert, die interne Denkprozesse mit dynamischem Werkzeugeinsatz verbinden. Beide Modelle zeichnen sich durch zwei wesentliche Neuerungen aus:
- Zusammenfassungen zum Nachdenken: Automatisch generierte Übersichten über die Denkschritte des Modells, die die Transparenz verbessern und Entwicklern helfen, Entscheidungswege zu verstehen.
- Erweitertes Denken (Beta): Ein Modus, der internes Denken mit externen Toolaufrufen – wie Websuche oder Codeausführung – ausgleicht, um die Aufgabenleistung bei längeren, komplexen Arbeitsabläufen zu optimieren.
Ursprünge und Positionierung
- Claude Opus 4 ist Anthropics Flaggschiff unter den Reasoning Engines. Sie ermöglicht die autonome Aufgabenausführung bis zu sieben Stunden lang und übertrifft große Konkurrenzmodelle – darunter Googles Gemini 2.5 Pro, OpenAIs o3-Reasoning-Modell und GPT-4.1 – bei Benchmark-Codierungs- und Tool-Use-Aufgaben.
- Claude Sonnet 4 ist der Nachfolger von Claude Sonnet 3.7 und ein kostengünstiges, für den universellen Einsatz optimiertes Arbeitsgerät. Es bietet im Vergleich zum Vorgängermodell eine bessere Anweisungsverfolgung, Werkzeugauswahl und Fehlerkorrektur und bietet gleichzeitig einen hohen Durchsatz für kundenorientierte Agenten und KI-Workflows.
Verfügbarkeit und Preisgestaltung
- API- und Cloud-Plattformen: Beide Modelle sind über die Anthropic API sowie über die großen Cloud-Marktplätze zugänglich – Amazon Bedrock, Google Cloud Vertex AI, Databricks, Snowflake Cortex AI und GitHub Copilot.
- Kostenlose vs. kostenpflichtige Stufen: Benutzer der kostenlosen Stufe können auf Claude Sonnet 4 zugreifen, während für Claude Opus 4 und erweiterte Denkfunktionen ein kostenpflichtiges Abonnement erforderlich ist.
Wie schneiden die Kernfunktionen von Opus 4 und Sonnet 4 im Vergleich ab?
Beide Modelle basieren auf derselben Architektur und denselben Sicherheitsgrundlagen, ihre Abstimmungs- und Leistungsgrenzen sind jedoch auf unterschiedliche Anwendungsfälle zugeschnitten.
Codierungs- und Entwicklungs-Workflows
Claude Opus 4 setzt neue Maßstäbe für KI-gestützte Softwareentwicklung und erreicht Bestwerte bei Branchen-Benchmarks wie SWE-Bench (72.5 %) und Terminal-Bench (43.2 %). Zudem ermöglicht es die autonome Codegenerierung für tagelange Refactoring-Pipelines. Die Unterstützung von über 32 Token-Kontexten und die Ausführung von Hintergrundaufgaben („Claude Code“) ermöglicht es Entwicklern, komplexe Bearbeitungen mehrerer Dateien und iteratives Debugging an das Modell auszulagern. Claude Sonnet 4 hingegen erreicht zwar nicht die absolute Spitzenleistung von Opus 4, ist aber in entwicklerorientierten Workflows im Durchschnitt immer noch 20 % präziser als Sonnet 3.7 und überzeugt durch schnelles Prototyping, Code-Review und interaktive Chat-Unterstützung.
Argumentation, Gedächtnis und Planung
Beide Modelle verfügen über erweiterte Speicherfenster, die den Kontext über Sitzungen von bis zu sieben Stunden hinweg speichern – ein Durchbruch für Anwendungen, die anhaltende Dialoge oder lang andauernde Agentenprozesse erfordern. Ihre „Denkzusammenfassungen“ bieten prägnante Übersichten über interne Denkprozesse und erhöhen so die Transparenz komplexer Entscheidungsprozesse. Die Zusammenfassungen von Opus 4 sind besonders detailliert und eignen sich für forschungsorientierte Analysen. Die schlankeren Zusammenfassungen von Sonnet 4 hingegen legen Wert auf Klarheit und Geschwindigkeit, um Kundensupport-Bots und Chat-Schnittstellen mit hohem Datenaufkommen zu unterstützen.
Sicherheits- und ethische Überlegungen
Angesichts der Leistungsfähigkeit von Claude Opus 4 – die sich in seiner Fähigkeit zeigt, mehrstufige Aufgaben zu steuern, die ein Risiko für die Biosicherheit bergen könnten – hat Anthropic seine Responsible Scaling Policy auf AI Safety Level 3 (ASL-3) angewendet und Anti-Jailbreak-Klassifikatoren, die Stärkung der Cybersicherheit und ein externes Bounty-Programm zur Erkennung von Schwachstellen eingeführt. Sonnet 4 wird zwar weiterhin durch robuste Filter- und Red-Teaming-Protokolle gesteuert, ist jedoch mit ASL-2 bewertet, was ein geringeres Risikoprofil widerspiegelt, das auf seine weniger autonomen Nutzungsszenarien abgestimmt ist. Die freiwillige Selbstregulierung von Anthropic soll zeigen, dass strenge Sicherheitsvorschriften den kommerziellen Einsatz nicht behindern müssen.
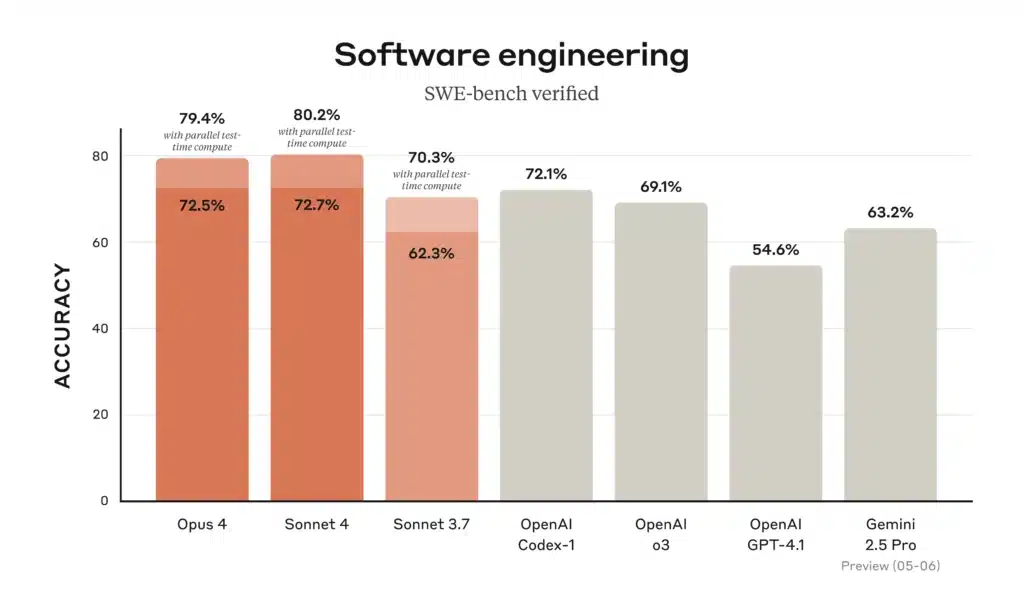
Leistungsbenchmarks
Abbildung: Software-Engineering-Genauigkeit (SWE-Bench-verifiziert) für Claude 4-Modelle im Vergleich zu früheren Modellen (höher ist besser). Opus 4 und Sonnet 4 liegen beide an der Spitze der Standard-Benchmarks. Auf Anthropics SWE-Bench (Softwareentwicklung) Im Test erreicht Opus 4 ca. 72.5 % und Sonnet 4 ca. 72.7 % (weit über den ca. 3.7 % von Claude Sonnet 62). Die obige Abbildung (von Anthropic) zeigt, dass beide neuen Modelle (orangefarbene Balken) bei echten Programmieraufgaben die Leistung früherer Claude-Versionen und sogar von GPT-4.1 übertreffen.
- Kodierung (SWE-Bench): Opus 4 = 72.5 %; Sonett 4 = 72.7 %. Beide übertreffen ältere Modelle bei weitem (Sonett 3.7 = 62.3 %, GPT-4.1 ≈54.6 %). Dies bestätigt Anthropics Behauptung, dass beide Claude 4-Modelle sind führend bei Codierungs-Benchmarks.
- Argumentation auf Hochschulniveau (GPQA Diamond): Anthropic meldet für Opus 4 eine Quote von 74.9 % gegenüber 4 % für Sonnet 70.0. Dies ist ein interner Maßstab für komplexe wissenschaftliche Argumentation; Opus hat hier einen leichten Vorsprung.
- Wissen (MMLU): Opus 4: 87.4 % vs. Sonett 4: 85.4 % auf MMLU. Auch hier liegt Opus etwas höher, aber beide schneiden gut ab (Anthropic merkt an, dass Sonett 4 gegenüber 3.7 auf MMLU eine „deutliche Verbesserung“ darstellt).
- Unabhängige Codiertests: In öffentlichen Evaluierungen schneiden beide Modelle hervorragend ab. Beispielsweise ergab ein Drittanbietertest einer Next.js-Codierungsaufgabe für Opus 4 eine Bewertung von 9.5/10 und für Sonnet 4 eine Bewertung von 9.25/10 (beide erreichten bei dieser Herausforderung mindestens die gleiche Punktzahl wie GPT-4.1). Beide Modelle produzierten präzisen, korrekten Code zuverlässiger als andere LLMs.
- Weitere Benchmarks: Beim High-School-Mathematikwettbewerb (AIME) schneiden beide Modelle schlecht ab (~33 %, eine bekannte Schwierigkeit für alle LLMs). Bei Tool- und Agentenaufgaben (TAU-Bench-Varianten) meldet Anthropic für beide Modelle gute Ergebnisse (>80 % bei einigen Teilaufgaben). Zusammenfassend lässt sich sagen, dass Opus 4 bei schwierigen Benchmarks meist einen leichten Leistungsvorteil hat, Sonnet 4 jedoch weiterhin äußerst leistungsfähig ist; oft geht es dabei um Kosten und Geschwindigkeit.
Insgesamt Claude Opus 4 ist das Spitzenmodell (am besten für extrem anspruchsvolle Aufgaben), während Claude Sonnet 4 liefert nahezu die gleiche Leistung bei deutlich höherer Effizienz. Preis und Verfügbarkeit spiegeln dies wider: Sonnet 4 ist ideal für skalierte Anwendungen (und kostenlose Nutzer), während Opus 4 für Teams reserviert ist, die jedes bisschen Leistung benötigen.
AnzeigenPreise
Token-Kosten (API): Opus 4 kostet 15 $ pro Million Input-Token und 75 $ pro Million Output-Token, Sonnet 4 hingegen nur 3 $/15 $ (Input/Output). Diese Preise entsprechen den bisherigen Preisen von Anthropics Claude v4.
Rabatte: Anthropic bietet hohe Rabatte auf Opus 4: Prompt-Caching kann die Token-Kosten um bis zu 90 % und die Stapelverarbeitung um bis zu 50 % senken. (Die niedrigeren Grundkosten von Sonnet 4 machen es auch ohne diese Funktionen günstiger.)
Abonnement-Inklusive: Sonett 4 ist sogar auf der kostenlos Claude-Plan, während Opus 4 ein kostenpflichtiges Claude Pro/Team/Enterprise-Abonnement erfordert. In der Praxis bedeutet dies, dass die gesamte Nutzung von Sonnet 4 (im Claude Chat oder in der API) sehr kostengünstig ist, Opus 4 jedoch nur für zahlende Kunden verfügbar ist.
Wie schneidet Sonnet 4 im Vergleich zu Claude Opus 4 in Anwendungsfällen ab?
Während Opus 4 das Flaggschiffmodell von Anthropic in Sachen Spitzenleistung ist, erobert Sonnet 4 seine Nische in Sachen Zweckmäßigkeit und Zugänglichkeit.
Leistung vs. Praktikabilität
- Rohe Leistungsfähigkeit: In direkten Vergleichsbenchmarks übertrifft Opus 4 Sonnet 4 hinsichtlich komplexer Argumentation, Genauigkeit der Codegenerierung und nachhaltiger mehrstufiger Arbeitsabläufe und unterstreicht damit seinen Status als „Best-in-Class“-Produkt.
- Wirkungsgrad: Sonnet 4 bietet etwa 80 Prozent der Leistung von Opus 4 bei der Hälfte der Rechenkosten und ist damit eine attraktive Option für Routineaufgaben und budgetsensible Projekte.
Anwendungsszenarien
| Luftüberwachung | Claude Sonnet 4 | Claude Opus 4 |
|---|---|---|
| Tägliches Codieren | ✔️ Ausgewogene Geschwindigkeit und Genauigkeit | ✔️ Maximale Genauigkeit |
| Forschung und wissenschaftliche KI | ✔️ Gut für Zusammenfassungen und Prototyping | ✔️ Überlegenes Deep-Dive-Argumentation |
| Autonome Agenten-Workflows | ✔️ Agenten auf Einstiegsniveau | ✔️ Hohe Komplexität, langfristiger Horizont |
| Kostensensitive Bereitstellungen | ✔️ Optimiert für Ressourceneffizienz | ❌ Nur Premium-Stufe |
Verfügbarkeit und Integration mit Entwicklertools
Claude Chat & Apps: Beide Modelle sind über die Claude-Oberfläche von Anthropic (Web und Apps) zugänglich. Sonnet 4 ist für alle Nutzer verfügbar, auch in der kostenlosen Version, während Opus 4 nur in kostenpflichtigen Tarifen (Pro/Max/Team/Enterprise) genutzt werden kann.
Anthropische API- und Cloud-Plattformen: Beide Claude-Modelle sind über die REST-API von Anthropic zugänglich und auf den wichtigsten Cloud-Plattformen gelistet. Laut Anthropic ermöglicht dies Entwicklern sofortigen Zugriff auf die Modelle und ihre Argumentations- und Handlungsfähigkeiten.
IDEs und Editor-Plugins: Anthropic hat Claude 4 tief in die Kodierungsabläufe integriert. Das neue Claude Code Das Produkt integriert Claude direkt in Entwicklerumgebungen. Beta-Erweiterungen für VS Code und JetBrains IDEs ermöglichen es dem Modell, Codeänderungen direkt in Ihren Dateien vorzuschlagen. Außerdem gibt es eine GitHub Actions-Integration: Sie können Claude Code in einem Pull Request taggen, um einen fehlgeschlagenen CI-Test automatisch zu beheben oder auf Reviewer-Kommentare zu reagieren. Ein Claude Code SDK ermöglicht die Ausführung von Claude als Unterprozess auf lokalen Rechnern. Kurz gesagt: Sonnet 4 und Opus 4 können nun als Paarprogrammierer in vertrauten Tools arbeiten. Anthropic weist darauf hin, dass GitHub Sonnet 4 als Modell für seinen neuen KI-gestützten Coding-Agenten verwenden wird und Konnektoren bereits für VS Code, JetBrains und GitHub existieren. Dieses Ökosystem ermöglicht es Entwicklern, die Funktionen von Claude zu nutzen, ohne ihre gewohnte Umgebung zu verlassen.
APIs und Workflow-Automatisierung: Beide Modelle unterstützen die programmatische Nutzung vollständig. Die API von Anthropic (v1) wurde aktualisiert, sodass Sie nun zwischen Denkmodi wechseln, Sicherheitsstufen festlegen und Tool-Konnektoren anhängen können. In der Praxis kann ein Python-Client-Aufruf bis auf den Modellnamen identisch aussehen (claude-opus-4-20250514 vs claude-sonnet-4-20250514). Auf CometAPIDie API bietet eine einheitliche Schnittstelle zum Aufrufen beider Modelle. Entwickler können sie mithilfe ihrer bevorzugten Sprache oder REST-Clients in automatisierte Workflows (CI/CD, Überwachung, Datenpipelines) integrieren.
Vergleichstabelle
| Merkmal | Claude Opus 4 | Claude Sonnet 4 |
|---|---|---|
| Modelltyp | Größtes „Opus“-Modell – auf maximale Denkleistung ausgerichtet. | Mittelgroßes Modell – ausgewogenes Verhältnis von Geschwindigkeit, Kosten und Leistungsfähigkeit. |
| Kontextfenster | 200 Token (riesiger Kontext); extrem lange Dokumente oder Code mit mehreren Dateien. | 200 Token (derselbe sehr große Kontext). |
| Ausgabelänge | Bis zu 32 Token pro Antwort (geeignet für komplexe Codeausgaben). | Bis zu 64 Token pro Antwort (längere Ausgaben). |
| Leistung (SWE-Benchmark) | ~72.5–79 % (führender Codierungs-Benchmark). | ~72.7–80 % (sehr ähnlicher Codierungsscore). |
| Leistung (Allgemeiner IQ) | Starkes fortgeschrittenes logisches Denken (MMLU ~87 %). Übertrifft Sonnet leicht. | Starkes logisches Denken (MMLU ~85 %); bei schwierigen Aufgaben etwas niedriger als bei Opus. |
| Anwendungsbeispiele | Am besten geeignet, langlaufende Codeprojekte, gründliche Recherche und Agentenplanung (z. B. Refactoring von Projekten mit mehreren Dateien, stundenlange Simulationen). | Am besten geeignet, Aufgaben mit hohem Volumen und interaktive Agenten (z. B. Live-Chatbots, Code-Reviews, CI-Automatisierung). |
| Erweitertes Denken | Ja (64K-Token-Denkmodus; ideal für tiefgründiges Denken in mehreren Schritten). Ideal für Aufgaben, die von längeren „Gedanken“ profitieren. | Ja (64K-Token-Denkmodus). Unterstützt dies auch mit für den Benutzer sichtbaren Zusammenfassungen der Argumentation. |
| Werkzeugunterstützung | Vollständige Toolnutzung (parallele Websuche, Codeausführung, Datei-E/A usw.). | Vollständiger Werkzeuggebrauch (gleiche Leistungsfähigkeit). |
| Speicher und „Dateien“ | Erweiterter Langzeitspeicher über die Files-API; eignet sich hervorragend zur Verfolgung des Projektstatus. | Gleiche Gedächtnisfunktionen; kann auch Fakten speichern und abrufen. |
| Multimodale Eingabe | Starker Code+Text; kann Bilder über Tools verarbeiten (Sehanalyse). Hauptsächlich Text-/Codierungsaufgaben. | Beinhaltet Vision- und UI-Funktionen; kann Bilder/Screenshots analysieren und sogar Software-UIs „verwenden“. |
| Latenz und Durchsatz | Höhere Latenz (höherer Rechenaufwand). Am besten für Batch-/automatisierte Workflows geeignet, bei denen es auf die Tiefe ankommt. | Geringere Latenz (schnellere Reaktionen). Optimiert für interaktive und Streaming-Nutzung. |
| Verfügbarkeit | Anthropic API (Pro/Enterprise), AWS Bedrock, GCP Vertex. Nur kostenpflichtige Version. | Anthropic API (alle Ebenen), AWS Bedrock, GCP Vertex. Auch kostenlos auf Claude. |
| Preise (Token) | $15 pro M-Eingang, $75 pro M-Ausgabe. | $3 pro M-Eingang, $15 pro M-Ausgabe. |
| Sicherheit/Ausrichtung | Höchste Sicherheitsstufe (ASL-3+-Maßnahmen), „geringste Wahrscheinlichkeit“ einer Abkürzung. | Dieselben robusten Sicherheitsmaßnahmen (ASL-3). Etwas effizienter, gleiche Ausrichtung. |
Fazit
Im Jahr 2025 stellen Claude Opus 4 und Sonnet 4 von Anthropic einen bedeutenden Fortschritt für entwicklerorientierte KI dar. Sie führen erweitertes multimodales Reasoning, eine tiefere Tool-Integration und beispiellose Kontextlängen ein, die die Herausforderungen moderner Entwicklungsabläufe direkt angehen. Durch die Einbettung dieser Modelle über API oder Cloud-Plattformen können Teams einen deutlich größeren Teil des Software-Lebenszyklus – vom Code-Design bis zur Bereitstellung – automatisieren, ohne an Genauigkeit oder Ausrichtung einzubüßen. Opus 4 ermöglicht bahnbrechendes KI-Reasoning für komplexe, offene Aufgaben, während Sonnet 4 schnelle und kostengünstige Leistung für alltägliche Programmier- und Agentenanforderungen bietet.
Diese Verbesserungen – erweitertes Denken, Speicherdateien, parallele Tools und optimierte IDE-Integration – sind nicht nur inkrementell. Sie verändern die Art und Weise, wie Entwickler mit KI interagieren: Von schnellen Einzelaufgaben hin zu nachhaltiger, stundenlanger Zusammenarbeit. Das Ergebnis: Routinemäßige Entwicklungsaufgaben werden schneller und zuverlässiger, sodass sich Ingenieure auf Kreativität und Übersicht konzentrieren können. Wie Anthropic sagt: Mit Claude 4 „können Sie Opus 4 nutzen, um Code für ganze Projekte zu schreiben und zu refaktorieren“ und Sonnet 4 für „alltägliche Entwicklungsaufgaben“.
Erste Schritte
CometAPI bietet eine einheitliche REST-Schnittstelle, die Hunderte von KI-Modellen – einschließlich der Claude-Familie – unter einem konsistenten Endpunkt aggregiert, mit integrierter API-Schlüsselverwaltung, Nutzungskontingenten und Abrechnungs-Dashboards. Anstatt mit mehreren Anbieter-URLs und Anmeldeinformationen zu jonglieren.
Entwickler können zugreifen Claude Sonnet 4 API (Modell: claude-sonnet-4-20250514 ; claude-sonnet-4-20250514-thinking) und Claude Opus 4 API (Modell: claude-opus-4-20250514; claude-opus-4-20250514-thinking)usw. durch CometAPI. . Erkunden Sie zunächst die Fähigkeiten des Modells in der Spielplatz und konsultieren Sie die API-Leitfaden Für detaillierte Anweisungen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI hat außerdem hinzugefügt cometapi-sonnet-4-20250514kombiniert mit einem nachhaltigen Materialprofil.cometapi-sonnet-4-20250514-thinking speziell für die Verwendung im Cursor.
Neu bei CometAPI? Starten Sie eine kostenlose 1$-Testversion und entfesseln Sie Sonnet 4 für Ihre schwierigsten Aufgaben.
Wir sind gespannt, was Sie bauen. Wenn Sie etwas nicht mögen, klicken Sie auf den Feedback-Button. So können wir es am schnellsten verbessern.