
Gemini 2.5 Flash API ist Googles neuestes multimodales KI-Modell, das für schnelle, kosteneffiziente Aufgaben mit steuerbaren Denkfähigkeiten entwickelt wurde und es Entwicklern ermöglicht, erweiterte „Denkfunktionen“ über die Gemini API ein- oder auszuschalten. Neueste Modelle sind gemini-2.5-flash.
Übersicht über Gemini 2.5 Flash
Gemini 2.5 Flash wurde für schnelle Reaktionen ohne Kompromisse bei der Ausgabequalität entwickelt. Es unterstützt multimodale Eingaben, darunter Text, Bilder, Audio und Video, und eignet sich daher für vielfältige Anwendungen. Das Modell ist über Plattformen wie Google AI Studio und Vertex AI zugänglich und bietet Entwicklern die notwendigen Tools für eine nahtlose Integration in verschiedene Systeme.
Grundlegende Informationen (Funktionen)
Gemini 2.5 Flash bietet mehrere herausragende Funktionen die es innerhalb der Gemini 2.5-Familie auszeichnen:
- Hybrides Denken: Entwickler können eine denken_budget Parameter zur genauen Steuerung, wie viele Token das Modell vor der Ausgabe für interne Schlussfolgerungen reserviert.
- Pareto-Grenze: Positioniert am optimaler Preis-Leistungs-PunktFlash bietet das beste Preis-Leistungs-Verhältnis unter den 2.5-Modellen.
- Multimodale Unterstützung: Prozesse Text, Bildern, Video und Audio- nativ und ermöglicht so umfassendere Konversations- und Analysefunktionen.
- 1 Million-Token-Kontext: Unübertroffene Kontextlänge ermöglicht eine gründliche Analyse und das Verständnis langer Dokumente in einer einzigen Anfrage.
Modellversionierung
Gemini 2.5 Flash hat den folgenden Schlüssel durchlaufen Versionen:
- gemini-2.5-flash-lite-preview-09-2025: Verbesserte Benutzerfreundlichkeit des Tools: Verbesserte Leistung bei komplexen, mehrstufigen Aufgaben mit einer 5%igen Steigerung der SWE-Bench-Verified-Werte (von 48.9 % auf 54 %). Verbesserte Effizienz: Durch die Aktivierung des Reasoning wird eine qualitativ hochwertigere Ausgabe mit weniger Tokens erreicht, was Latenz und Kosten reduziert.
- Vorschau 04-17: Early Access Release mit „Denk“-Funktion, verfügbar über Gemini-2.5-Flash-Vorschau-04-17.
- Stabile allgemeine Verfügbarkeit (GA): Ab dem 17. Juni 2025 ist der stabile Endpunkt Gemini-2.5-Flash ersetzt die Vorschau und gewährleistet produktionsreife Zuverlässigkeit ohne API-Änderungen seit der Vorschau vom 20. Mai.
- Abschaffung der Vorschau: Die Abschaltung der Vorschau-Endpunkte war für den 15. Juli 2025 geplant. Benutzer müssen vor diesem Datum zum GA-Endpunkt migrieren.
Ab Juli 2025 ist Gemini 2.5 Flash nun öffentlich verfügbar und stabil (keine Änderungen gegenüber der Gemini-2.5-Flash-Vorschau-05-20 ).Wenn Sie gemini-2.5-flash-preview-04-17Die bestehenden Vorschaupreise bleiben bis zur geplanten Außerdienststellung des Modell-Endpunkts am 15. Juli 2025 bestehen. Danach wird er abgeschaltet. Sie können zum allgemein verfügbaren Modell migrieren.gemini-2.5-flash".
Schneller, günstiger, smarter:
- Designziele: geringe Latenz + hoher Durchsatz + niedrige Kosten;
- Allgemeine Beschleunigung des Schlussfolgerungsprozesses, der multimodalen Verarbeitung und von Aufgaben mit langen Texten;
- Die Token-Nutzung wird um 20–30 % reduziert, wodurch die Argumentationskosten erheblich sinken.
Technische Daten
Eingabekontextfenster: Bis zu 1 Million Token, was eine umfassende Kontextspeicherung ermöglicht.
Ausgabetoken: Kann bis zu 8,192 Token pro Antwort generieren.
Unterstützte Modalitäten: Text, Bilder, Audio und Video.
Integrationsplattformen: Verfügbar über Google AI Studio und Vertex AI.
Preisgestaltung: Wettbewerbsfähiges, tokenbasiertes Preismodell, das eine kostengünstige Bereitstellung ermöglicht.
Technische Daten
Unter der Haube ist Gemini 2.5 Flash ein transformatorbasiert großes Sprachmodell, das auf einer Mischung aus Web-, Code-, Bild- und Videodaten trainiert wurde. Schlüssel technisch Zu den Spezifikationen gehören:
Multimodales Training: Flash ist darauf trainiert, mehrere Modalitäten auszurichten und kann Text nahtlos mit Bildern, Video oder Audio-, nützlich für Aufgaben wie Videozusammenfassung oder Audiountertitelung.
Dynamischer Denkprozess: Implementiert eine interne Argumentationsschleife, in der das Modell Pläne kombiniert mit einem nachhaltigen Materialprofil. zerlegt komplexe Eingabeaufforderungen vor der endgültigen Ausgabe.
Konfigurierbare Denkbudgets: Der denken_budget kann eingestellt werden von 0 (keine Begründung) bis zu 24,576-Token, wodurch Kompromisse zwischen Latenz und Antwortqualität möglich sind.
Werkzeugintegration: Unterstützt Erdung mit der Google-Suche, Codeausführung, URL-Kontext und Funktionsaufruf, wodurch reale Aktionen direkt aus natürlichen Sprachanweisungen heraus ermöglicht werden.
Benchmark-Leistung
In strengen Tests zeigt Gemini 2.5 Flash branchenführend Performance:
- Schwierige Eingabeaufforderungen in LMArena: Erzielt nur übertroffen von 2.5 Pro beim anspruchsvollen Hard Prompts-Benchmark und demonstriert dabei starke Fähigkeiten zum mehrstufigen Denken.
- MMLU-Score von 0.809: Übertrifft die durchschnittliche Modellleistung mit einem 0.809 Die Genauigkeit von MMLU spiegelt das breite Fachwissen und die Argumentationskompetenz wider.
- Latenz und Durchsatz: Erreicht 271.4 Token/Sekunde Dekodiergeschwindigkeit mit einer 0.29 s Zeit bis zum ersten Token, wodurch es ideal für latenzempfindliche Workloads ist.
- Preis-Leistungs-Führer: Auf \0.26 $/1 Mio. TokenFlash unterbietet viele Konkurrenten und erreicht oder übertrifft sie bei wichtigen Benchmarks.
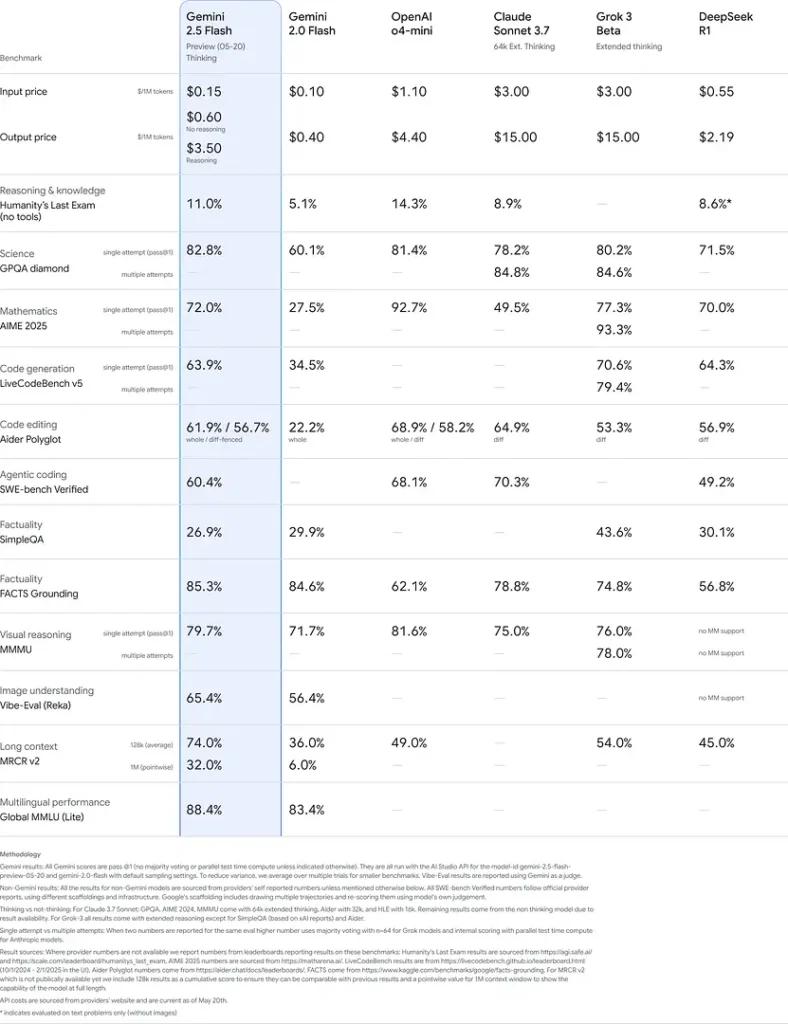
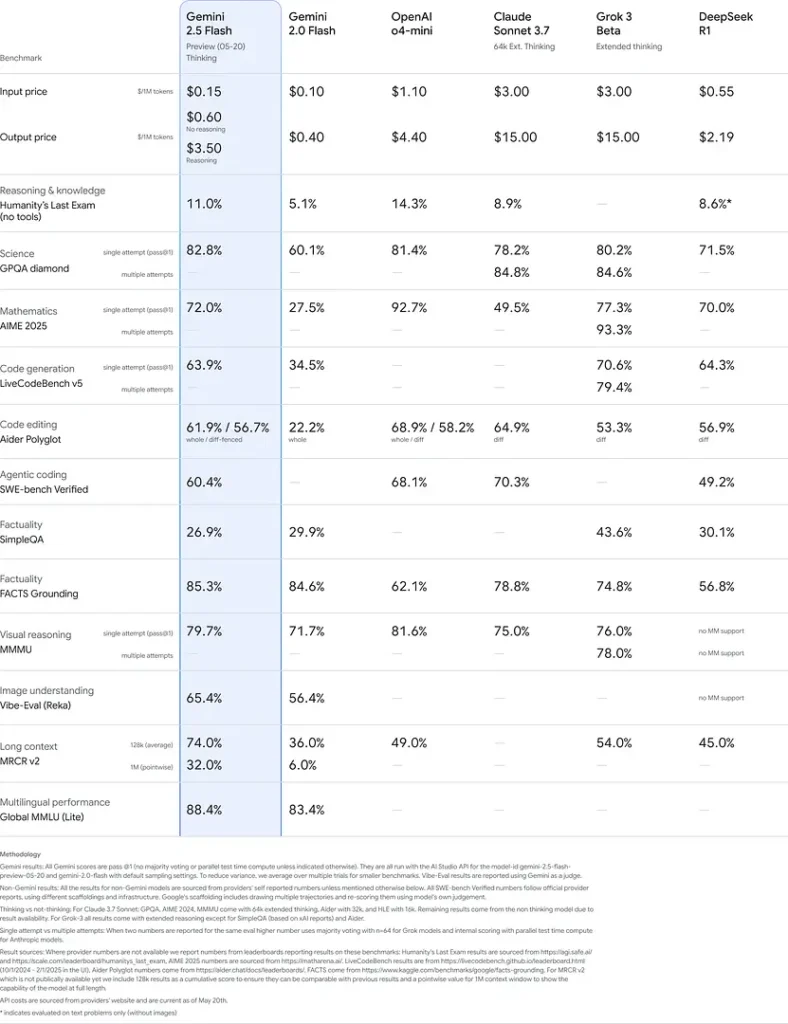
Diese Ergebnisse zeigen den Wettbewerbsvorteil von Gemini 2.5 Flash in den Bereichen logisches Denken, wissenschaftliches Verständnis, mathematische Problemlösung, Codierung, visuelle Interpretation und Mehrsprachigkeit:
Einschränkungen
Obwohl leistungsstark, bietet Gemini 2.5 Flash bestimmte Einschränkungen:
- Sicherheitsrisiken: Das Modell kann eine „predigender“ Ton und kann plausibel klingende, aber falsche oder verzerrte Ergebnisse (Halluzinationen) erzeugen, insbesondere bei Grenzfallabfragen. Eine strenge menschliche Überwachung bleibt unerlässlich.
- Ratenbegrenzungen: Die API-Nutzung wird durch Ratenbegrenzungen (10 RPM, 250,000 TPM, 250 RPD auf Standardebenen) eingeschränkt, was sich auf die Stapelverarbeitung oder Anwendungen mit hohem Volumen auswirken kann.
- Geheimdienst-Etage: Obwohl außergewöhnlich leistungsfähig für eine Blitz Modell, es bleibt weniger genau als 2.5 Pro bei den anspruchsvollsten Agentenaufgaben wie fortgeschrittener Codierung oder Multi-Agenten-Koordination.
- Kostenkompromisse: Obwohl das beste Angebot Preis-Leistungs, umfangreiche Nutzung der Denken Der Modus erhöht den Gesamttokenverbrauch und damit die Kosten für tiefgründige Argumentationsaufforderungen.
Siehe auch Gemini 2.5 Pro API
Fazit
Gemini 2.5 Flash unterstreicht Googles Engagement für die Weiterentwicklung von KI-Technologien. Dank seiner robusten Leistung, multimodalen Funktionen und effizienten Ressourcenverwaltung bietet es eine umfassende Lösung für Entwickler und Unternehmen, die die Leistungsfähigkeit künstlicher Intelligenz in ihren Betrieben nutzen möchten.
Wie man anruft Gemini 2.5 Flash API von CometAPI
Gemini 2.5 Flash API-Preise in CometAPI, 20 % Rabatt auf den offiziellen Preis:
- Eingabe-Token: 0.24 $ / M Token
- Ausgabe-Token: 0.96 $/M Token
Erforderliche Schritte
- Einloggen in cometapi.comWenn Sie noch nicht unser Benutzer sind, registrieren Sie sich bitte zuerst
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.
- Holen Sie sich die URL dieser Site: https://api.cometapi.com/
Verwendungsmethoden
- Wählen Sie das "
gemini-2.5-flash”-Endpunkt, um die API-Anfrage zu senden und den Anfragetext festzulegen. Die Anfragemethode und der Anfragetext stammen aus der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihre Bequemlichkeit. - Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
- Geben Sie Ihre Frage oder Anfrage in das Inhaltsfeld ein – das Modell antwortet darauf.
- . Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
Informationen zum Modellstart in der Comet-API finden Sie unter https://api.cometapi.com/new-model.
Informationen zu Modellpreisen in der Comet-API finden Sie unter https://api.cometapi.com/pricing.
API-Verwendungsbeispiel
Entwickler können interagieren mit Gemini-2.5-Flash über die API von CometAPI, die die Integration in verschiedene Anwendungen ermöglicht. Unten sehen Sie ein Python-Beispiel:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Dieses Skript sendet eine Eingabeaufforderung an den Gemini 2.5 Flash Modell und druckt die generierte Antwort aus und demonstriert, wie man Gemini 2.5 Flash für komplexe Erklärungen.