

Google und die Forschungssparte DeepMind haben leise (und dann nicht mehr ganz so leise) den nächsten großen Schritt auf der Gemini-Roadmap vorangetrieben: Gemini 3.1 Pro. Der Rollout, über verbraucherorientierte Oberflächen und CometAPI, positioniert sich als Leistungs- und Reasoning-Upgrade für die Gemini-3-Familie — mit deutlich stärkerem Langform-Reasoning, verbesserter multimodaler Verständnisfähigkeit und besserer Skalierbarkeit für reale Anwendungen.
Googles neuestes Modell — was ist Gemini 3.1 Pro?
Gemini 3.1 Pro ist das erste inkrementelle Update in der Gemini-3-Familie, positioniert als „leistungsfähigstes“ Reasoning-Modell, optimiert für mehrstufige, multimodale und agentische Aufgaben. In der öffentlichen Vorschau seit Mitte Februar 2026 verfügbar (Vorschau angekündigt am 19.–20. Feb. 2026), zielt das Modell explizit auf Szenarien ab, die anhaltende Gedankenkettungen, Tool-Nutzung und Verständnis von langem Kontext erfordern — zum Beispiel großangelegte Forschungssynthese, Engineering-Agents, die Tools und Systeme koordinieren, sowie multimodale Analyse von Dokumenten, die Text, Bilder, Audio und Video mischen.
Auf hoher Ebene wird Gemini 3.1 Pro von seinen Entwicklern beschrieben als:
- Nativ multimodal — kann Text, Bilder, Audio und Video aufnehmen und darüber schlussfolgern.
- Für langen Kontext gebaut — unterstützt sehr große Kontextfenster, geeignet für ganze Codebasen, Multi-Dokument-Dossiers oder lange Transkripte.
- Optimiert für zuverlässiges Reasoning und agentische Workflows, d. h. es ist darauf abgestimmt, über mehrstufige Aufgaben zu planen, Tools aufzurufen und Ausgaben zu verifizieren.
Warum das jetzt wichtig ist: Organisationen und Entwickler bewegen sich von „guten Konversationsassistenten“ hin zu „entscheidungsrelevanten Support- und Forschungs-Agents“ (juristische Entwürfe, F&E-Synthese, multimodales Dokumentenverständnis). Gemini 3.1 Pro ist explizit für diesen Korridor ausgelegt — um Halluzinationen zu reduzieren, nachvollziehbares Reasoning zu liefern und sich für Prototyping und Produktion in CometAPI zu integrieren.
Was sind die technischen Highlights und Funktionen von Gemini 3.1 Pro?
Native Multimodalität und extreme Kontextfenster
Gemini 3.1 Pro setzt den Multimodalitätsfokus der Gemini-Linie fort. Laut Model Card und Produktnotizen akzeptiert und verarbeitet das Modell Text, Bilder, Audio und Video in derselben Pipeline — eine Fähigkeit, die Workflows vereinfacht, in denen Datentypen gemischt sind (z. B. juristische Aussagen mit Audio + Transkript + Scans). Besonders hervorzuheben ist, dass das Modell ein 1,000,000-Token-Kontextfenster unterstützt und lange Ausgaben erzeugen kann (veröffentlichte Notizen nennen sehr große Ausgabelimits, passend für Langform-Aufgaben). Diese Skalierung macht es geeignet für Anwendungsfälle wie die Analyse ganzer Code-Repositories, mehrkapiteliger Dokumente oder langer Transkripte ohne Chunking.
„Dynamisches Denken“: verbessertes Reasoning und schrittweise Planung
Google beschreibt 3.1 Pro als mit verbessertem „Denken“ — d. h. besserem internem Chain-of-Thought-Handling und dynamischer Auswahl von Reasoning-Strategien in Abhängigkeit von der Aufgabenkomplexität. Das Modell ist darauf abgestimmt, bei Bedarf explizite Mehrschrittplanung zu aktivieren und dabei token-effizient zu bleiben. In der Praxis bedeutet das weniger Halluzinationen bei komplexen, schrittweisen Problemen und verbesserte faktische Konsistenz in mehrstufigen Reasoning-Benchmarks.
Agentische Workflows und Tool-Nutzung
Ein zentrales Designziel von 3.1 Pro ist agentische Leistungsfähigkeit: Tools koordinieren, Web-Grounding oder Suche aufrufen, Code-Snippets schreiben und ausführen sowie Ausgaben in Zweitdurchgängen verifizieren. Google hat 3.1 Pro in agentenzentrierte Produkte integriert (z. B. die Antigravity-Entwicklungsumgebung), damit Modelle Aufgaben ausführen können, die einen Editor, ein Terminal und einen Browser einbeziehen — und Artefakte wie Screenshots und Browseraufnahmen festhalten, um Fortschritte zu verifizieren. Diese Funktionen zielen darauf ab, die Lücke zwischen „ratgebenden“ Modellen und Modellen zu schließen, die tatsächlich Multi-Tool-Workflows zuverlässig ausführen.
Spezialisierte Submodi (Deep Research, Deep Think)
Google kombiniert 3.1 Pro mit „Deep Research“ und verweist auf eine kommende Variante „Deep Think“. Diese Submodi zielen — respektive — auf Research-Aufgaben mit hohem Recall und maximale Reasoning-Tiefe (bei zusätzlichen Rechenkosten und Latenzen). Sie sollen Analysten, Forschern und Entwicklern dienen, die bewusstere, hochwertigere Ausgaben benötigen, statt der schnellsten und günstigsten Antworten.
Wie performt Gemini 3.1 Pro in Benchmarks?
Gemini 3.1 Pro erzielt starke Zuwächse gegenüber früheren Gemini-3-Pro-Ergebnissen, führt häufig in einem breiten Set an mehrstufigen Reasoning- und multimodalen Messungen — liegt aber bei bestimmten spezialisierten Aufgaben hinter einigen Wettbewerbern (insbesondere bei bestimmten fortgeschrittenen Coding- oder Experten-Frage-Suites). Kurz: breite Verbesserungen mit engen Wettbewerbsvorteilen in Spezialbenchmarks.
Zentrale Benchmark-Aussagen und Kennzahlen
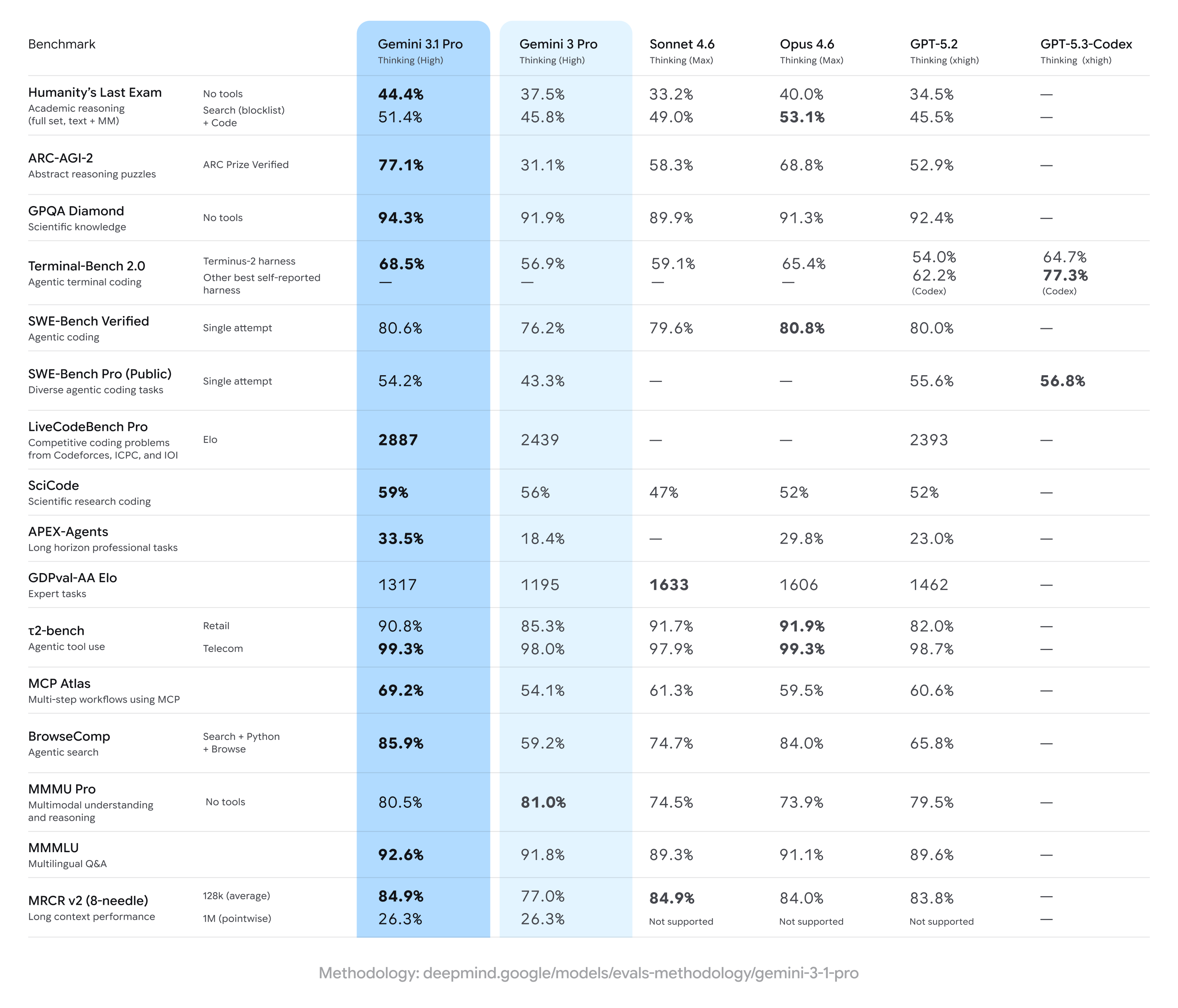
- ARC-AGI-2 (abstraktes Reasoning / mehrstufige Wissenschaftsrätsel): Gemeldete Zuwächse für Gemini 3.1 Pro zeigen erhebliche Verbesserungen gegenüber vorherigen Gemini-3-Pro-Versionen; eine Community-Test-Suite wies in kurzen, fokussierten Tests auf eine mehr als doppelt so hohe Leistung auf ARC-AGI-2 im Vergleich zur vorherigen Gemini-3-Pro-Baseline hin. Spezifische gemeldete Scores (Community-Tests) sehen Gemini 3.1 Pro bei etwa ~77,1% in einigen ARC-ähnlichen Aggregationen (öffentliche Berichte).
- GPQA Diamond und Benchmarks auf Graduiertenniveau in den Naturwissenschaften: Berichte deuten darauf hin, dass Gemini 3.1 Pro auf GPQA Diamond (ein QA-Benchmark auf Graduiertenniveau) Höchstwerte erzielte, frühere Gemini-Modelle übertraf und in unabhängigen Läufen eine neue Bestmarke für die Familie setzte. Diese Zugewinne spiegeln das verbesserte Chain-of-Thought- und schrittweise Reasoning-Finetuning wider.
- „Humanity’s Last Exam“ mit aktivierten Tools (Multi-Tool, Grounded Reasoning): In direkten Vergleichen mit Anthropic’s Claude Opus 4.6 erzielte Claude 53,1% auf diesem komplexen, tool-unterstützten Benchmark, während Gemini 3.1 Pro in derselben Testrunde 51,4% erreichte — Gemini ist damit knapp dahinter, aber nicht an der Spitze in genau dieser Multi-Tool-Prüfung.
- Coding- & Terminal-Benchmarks (Terminal-Bench 2.0, SWE-Bench Pro): Spezialisierte Coding-Benchmarks zeigten größere Divergenzen. Auf Terminal-Bench 2.0 mit spezifischen Harnesses erreichten GPT-5.3-Codex-Varianten rund 77,3% gegenüber ~68,5% für Gemini 3.1 Pro in denselben Vergleichen. Auf SWE-Bench Pro zeigten öffentlich gemeldete Ergebnisse für Gemini 3.1 Pro ~54,2% gegenüber 56,8% für GPT-5.3-Codex — näher beisammen, aber mit einem Vorteil der Codex-Familie bei spezialisierten Programmieraufgaben in diesen Läufen.
- GDPval-AA Elo (Bewertung von Expertenaufgaben): In einem Elo-artigen aggregierten Ranking für Expertenaufgaben erzielten Claude Sonnet/Opus-Varianten höhere Werte (z. B. ~1606–1633 Punkte), während ein öffentlicher Bericht Gemini 3.1 Pro bei ~1317 Punkten in demselben Datensatz sah — was auf Verbesserungspotenzial in bestimmten engen Expertendomänen hindeutet.
Ergebnisse aus Praxistests und Hands-on-Experimente
Praxiserfahrungen und Analystenberichte zeigen, dass Gemini 3.1 Pro besonders stark ist bei:
- Zusammenfassungen mit langem Kontext und Multi-Dokument-Synthese, bei denen das 1M-Token-Fenster artefaktanfälliges Chunking vermeidet.
- Multimodalen Verständnistasks, bei denen Bild- + Text-Grounding die faktische Extraktion verbessert.
- Agentischer Automatisierung (z. B. Koordination einfacher Toolchains) — Antigravity-Tests zeigen, dass die Orchestrierung von Multi-Agent-Aufgaben mit Artefakten, die jeden Schritt aufzeichnen, machbar ist.
Wo Gemini 3.1 Pro noch zurückliegt (was die Zahlen sagen)
Kein Modell ist überall das beste. Unabhängige Kommentare und Community-Tests heben spezifische Lücken hervor:
- Software-Engineering- und Code-Maintenance-Benchmarks (SWE-Bench Pro und ähnliche) — Gemini 3.1 Pro liegt hinter einem Wettbewerber (Anthropic’s Claude Opus 4.6) bei Aufgaben, die praktische Software-Engineering-Fähigkeiten testen: großangelegte Refactorings, Bug-Triage in unübersichtlichen Codebasen und einige Arten der automatischen Programmkorrigierung. Anders gesagt: Für alltägliche Engineering-Maintenance behalten spezialisierte Modelle in bestimmten Testbeds weiterhin einen Vorsprung.
- Latenzempfindliche Mikrotasks — da Gemini 3.1 Pro auf Tiefe abgestimmt ist, sind Aufgaben mit ultraniedriger Latenz und hohem Durchsatz (z. B. Mikro-Inferenz für leichte Konversations-UIs) eventuell besser mit „Flash“ oder anderen optimierten Varianten der Gemini-Familie bedient.
Wie ist die Preisgestaltung für Gemini 3.1 Pro?
Zugang zu Gemini 3.1 Pro ist auf zwei Arten möglich — Verbraucherabonnement oder Entwickler-API — und die Preise unterscheiden sich entsprechend.
- Verbraucher (Gemini-App / Google AI Pro): Der Zugriff auf Gemini 3.1 Pro ist im Google AI Pro-Abonnement enthalten, das in den USA $19.99 / Monat kostet (Google bietet außerdem den günstigeren „AI Plus“- und den höheren „AI Ultra“-Tarif an). Google.
- Entwickler / API (tokenbasiert): Wenn du die Gemini-Modelle über die Gemini/AI-Entwickler-API aufrufst, erfolgt die Abrechnung nach Tokens. Für die Gemini-3.x-Pro-Vorschau liegen die veröffentlichten Entwicklerpreise ungefähr bei: $2.00 pro 1M Input-Tokens und $12.00 pro 1M Output-Tokens für das Standardband (≤200k Prompts) — mit höheren Stufen (z. B. $4/$18 pro 1M) für sehr große Kontexte. (Siehe die Gemini-API-Preistabelle für alle Details und Batch-Preise.)
- Wenn du Gemini 3.1 Pro über CometAPI nutzt:
| Comet-Preis (USD / M Tokens) | Offizieller Preis (USD / M Tokens) |
|---|---|
| Eingabe:$1.6/M; Ausgabe:$9.6/M | Eingabe:$2/M; Ausgabe:$12/M |
Preise für Verbraucherabos (Gemini-App)
Für Endnutzerpläne innerhalb der Gemini-App strukturiert Google Tarife, die den Zugriff auf Modellvarianten und Zusatzfunktionen steuern: Google AI Pro und Google AI Ultra. Die Preise variieren je nach Markt und Währung; veröffentlichte Beispiele zeigen Google AI Pro für $19.99/Monat (mit verfügbaren Promo-Testphasen) und gestaffelte Währungspreise auf der Produktseite (einschließlich Testangebote und kurzfristig reduzierter Tarife). AI Ultra bietet gebündelten höheren Zugriff (z. B. priorisierten Zugang zu neuen Innovationen, höhere Guthaben für Videogenerierung) zu einem höheren Monatsbetrag. Diese Verbraucherpläne sind wettbewerbsfähig mit anderen hochwertigen Consumer-AI-Abos und sollen einzelnen Power-Usern oder kleinen Teams Zugang zu 3.1-Pro-Funktionen ohne API-Integration geben.
Praktische Prompt- und Nutzungstipps (so würde ich vorgehen)
Nutze diese Muster für zuverlässige, reproduzierbare Ergebnisse:
- Expliziter Schrittplaner
Prompt-Muster:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Dies nutzt die stärkere schrittweise Ausführung von 3.1 Pro und schafft Checkpoints. - Strukturierte Ausgabe mit Schemas
Bitte um JSON mit einem Schema undstrict: true. Da 3.1 Pro lange, schema-konforme Ausgaben zuverlässiger erzeugt, erhältst du größere Einzelantworten, die du downstream parsen kannst. - Tool-Check-Sandwich
Beim Aufruf externer Tools (APIs, Code Runner) soll das Modell produzieren: Plan → exakter Toolaufruf (Copy/Paste-freundlich) → Validierungsschritte. Verifiziere die Validierungsschritte außerhalb des Modells, bevor du fortfährst. - Vorsicht vor Single-Step-Vertrauen
Selbst wenn das Modell perfekt aussehenden Code oder Befehle schreibt, führe unabhängige Validierungen durch (Tests, Linter, sandboxed Ausführung) — insbesondere für agentische/autonome Aktionen.
Hands-on mit Gemini 3.1 Pro
Testfall 1: Research-Assistent für langen Kontext (NotebookLM / Deep Research)
Ziel: Die Fähigkeit des Modells bewerten, 10–50 lange Dokumente (z. B. Berichte, Whitepaper) zu einer mehrseitigen Executive Summary mit Zitaten und Handlungsempfehlungen zu synthetisieren.
Setup: Einen Korpus mit insgesamt 200k–800k Tokens einspeisen; das Modell anweisen, eine 2–4-seitige Zusammenfassung mit expliziten Zitaten und „Next Steps“-Empfehlungen zu erstellen. Eine wiederholbare Prompt-Vorlage verwenden und Zeit, Tokenverbrauch (Kosten) sowie faktische Genauigkeit messen.
Ergebnisse: Schnellere End-to-End-Zusammenfassung mit weniger Chunking-Artefakten gegenüber älteren Modellen, höhere Zitationsgenauigkeit in der Zusammenfassung und verbesserte Kohärenz im großen Maßstab — bei beträchtlichem Tokenverbrauch (Budget einplanen). Benchmarks und Praxistests zeigen, dass Gemini 3.1 Pro dank des 1M-Token-Fensters bei Multi-Dokument-Synthese glänzt.
Testfall 2: Agentischer Coding-Assistent (Antigravity + GitHub Copilot)
Ziel: Reduktion der Time-to-Complete für mehrstufige Entwickleraufgaben messen (z. B. Feature über mehrere Dateien implementieren, Tests ausführen, fehlschlagende Tests reparieren).
Setup: Antigravity oder GitHub Copilot in der Vorschau mit ausgewähltem Gemini 3.1 Pro nutzen. Reproduzierbare Aufgaben definieren (Issue-Erstellung → Implementierung → Tests ausführen), Schritte und Agent-Artefakte protokollieren und mit einer rein menschlichen Baseline vergleichen.
Ergebnisse: Verbesserte Orchestrierung mehrstufiger Aufgaben (Artefaktaufzeichnung, automatische Vorschläge für Patch-Kandidaten), besseres Multi-Datei-Reasoning als frühere Gemini 3 Pro-Versionen und messbare Zeitgewinne bei routinemäßiger Feature-Arbeit. Spezielle, niedrigstufige System-Debugging-Aufgaben könnten weiterhin spezialisierte Code-First-Modelle begünstigen (Community-Ergebnisse zeigen eine Lücke gegenüber einigen GPT-Codex-Varianten bei bestimmten Terminal-Benchmarks).
Testfall 3: Multimodale juristische/medizinische Dokumentenprüfung
Ziel: Das Modell verwenden, um einen gemischten Korpus (gescannte PDFs, Bilder, Audiotranskripte) aufzunehmen, Schlüsselfakten zu extrahieren und eine Risikomatrix sowie priorisierte Maßnahmen zu erstellen.
Setup: Einen Datensatz mit gescannten Bildern und OCR-Text sowie unterstützendem Audio bereitstellen. Präzision in der Named-Entity-Extraktion, False-Positive-Rate und die Fähigkeit des Modells messen, auf Quellartefakte zu verweisen.
Ergebnisse: Stärkeres integriertes Reasoning über Modalitäten hinweg und besser nachvollziehbare Ausgaben (Fähigkeit, auf das Bild/die Seite/den Audiozeitstempel zu verweisen, der eine Aussage stützt). Das große Kontextfenster reduziert den Bedarf an manuellem Chunking und Querverweisen. In regulierten Domänen sollten Ausgaben jedoch von Fachexperten validiert und ein Grounding-/Verifizierungspipeline verwendet werden.
Erste Eindrücke (was sich anders anfühlt)
- Tieferes schrittweises Reasoning. Aufgaben, die zuvor mehrere Rückfragen brauchten — z. B. Multi-Dokument-Synthese, mehrstufige Mathematik/Logik — werden tendenziell in weniger Durchläufen und mit klareren, Chain-of-Thought-artigen Ausgaben abgeschlossen (ohne interne Anweisungstexte offenzulegen). Das hat Google hervorgehoben.
- Längere, hochwertigere strukturierte Ausgaben. JSON und Langform-Automatisierungen sind konsistenter und oft deutlich länger (einige Nutzer berichteten von wesentlich größeren Ausgaben als bei 3.0). Das ist ideal für Generatorjobs, bei denen du eine einzelne, große Payload möchtest. Rechne mit größeren Ausgaben und Streaming.
- Effizienterer Umgang mit Tokens/Kontext. Verbesserte Token-Effizienz und ein „geerdeter, faktisch konsistenteres“ Verhalten in Tool-Nutzungsszenarien. Das zeigt sich in weniger Halluzinationen bei kurzen Faktenabfragen.
Abschließende Einschätzung: Lohnt sich die Einführung von Gemini 3.1 Pro jetzt?
Gemini 3.1 Pro stellt einen spürbaren Fortschritt in der Gemini-Familie dar — mit nachweisbaren Verbesserungen bei Reasoning-, Coding- und agentischen Benchmarks — untermauert durch Googles veröffentlichte Model Card und unabhängige Tracker, die große Sprünge auf ausgewählten Bestenlisten anführen. Für Teams, die fortgeschrittenes Reasoning, agentische Tool-Koordination oder langkontextuelle multimodale Fähigkeiten benötigen, ist 3.1 Pro ein überzeugender Kandidat.
Entwickler können Gemini 3.1 Pro jetzt über CometAPI nutzen. Starte damit, die Fähigkeiten des Modells im Playground zu erkunden, und konsultiere den API guide für detaillierte Anleitungen. Bevor du zugreifst, stelle sicher, dass du bei CometAPI eingeloggt bist und einen API-Schlüssel erhalten hast. CometAPI bietet einen deutlich niedrigeren Preis als der offizielle, um dir die Integration zu erleichtern.
Ready to Go?→ Jetzt für Gemini 3.1 Pro registrieren !
Wenn du mehr Tipps, Guides und News zu KI erfahren möchtest, folge uns auf VK, X und Discord!