

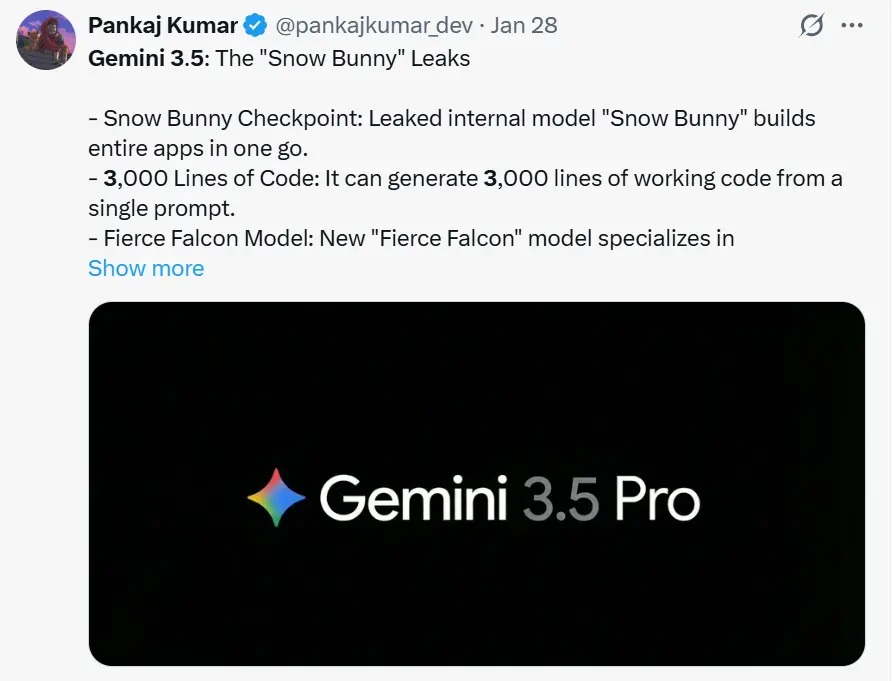
Google testet still und leise eine neue interne Iteration seiner Gemini-Familie — verschiedentlich als „Gemini 3.5“ und unter dem faszinierenden internen Codenamen „Snow Bunny.“ gemeldet. Unter dem Codenamen „Snow Bunny,“ soll dieser interne Checkpoint bestehende Benchmarks pulverisiert haben und eine beispiellose Fähigkeit demonstrieren, komplette Software-Anwendungen — mit bis zu 3.000 Zeilen funktionalem Code — in einem einzigen Prompt zu generieren.
Während sich Silicon Valley bemüht, die Daten zu verifizieren, deuten frühe Berichte darauf hin, dass Google einen Durchbruch im „System 2“-Reasoning erzielt hat, der es Gemini 3.5 ermöglicht, innezuhalten, nachzudenken und komplexe Systeme zu entwerfen – mit einer Kompetenz, die aktuelle Spitzenreiter wie GPT-5.2 und Claude Opus 4.5 in den Schatten stellt.
Was ist Gemini 3.5 „Snow Bunny“?
Gemini 3.5, intern unter dem Codenamen „Snow Bunny“ geführt, scheint Googles direkte Antwort auf die Stagnation der Reasoning-Fähigkeiten von Modellen zu sein, die Ende 2025 beobachtet wurde. Anders als seine Vorgänger, die stark auf multimodales Verständnis und die Größe des Kontextfensters fokussierten, steht Gemini 3.5 für einen Paradigmenwechsel hin zu erweiterten kognitiven Horizonten und autonomer Software-Architektur.
Die „Snow Bunny“-Architektur
Die Bezeichnung „Snow Bunny“ bezieht sich Berichten zufolge auf einen spezifischen, hochperformanten Checkpoint des Modells, der derzeit auf Googles Vertex AI- und AI Studio-Plattformen einem A/B-Test unterzogen wird. Der Leak deutet darauf hin, dass es sich nicht lediglich um ein „Pro“- oder „Ultra“-Refresh handelt, sondern um ein grundlegendes Architektur-Upgrade mit integrierten „Deep Think“-Fähigkeiten.
Spezialisierte Modellvarianten
Leaks deuten darauf hin, dass „Snow Bunny“ eher eine Familie spezialisierter Modelle als ein einzelner Monolith sein könnte. In den geleakten Dokumenten wurden zwei spezifische Varianten identifiziert:
- Fierce Falcon: Eine Variante, die auf rohe Rechengeschwindigkeit und logische Deduktion optimiert ist, vermutlich ausgerichtet auf Competitive Programming und schnelle Datenanalyse.
- Ghost Falcon: Ein kreatives Kraftpaket, konzipiert für „Vibe Coding“, das UI/UX-Design, SVG-Erzeugung, Audio-Synthese und visuelle Effekte mit hoher Qualitätstreue bewältigt.
System-2-Reasoning: Der „Deep Think“-Modus
Das herausragende Merkmal von Gemini 3.5 ist die mutmaßliche „System 2“-Reasoning-Engine. Inspiriert von der menschlichen Kognitionspsychologie ermöglicht dieses System dem Modell, vor der Antwort auf komplexe Anfragen zu „pausieren“. Anstatt sofort das nächste Token vorherzusagen, tritt das Modell in einen verborgenen Chain-of-Thought-Prozess ein und bewertet mehrere Ausführungspfade für Code- oder Logikaufgaben. Dieser „Deep Think“-Schalter soll seine Benchmark-Werte in unbekannte Höhen katapultiert haben.
Wer hat die Nachricht veröffentlicht?
Die Existenz von Gemini 3.5 wurde Ende Januar 2026 durch eine Reihe koordinierter Leaks auf der Social-Media-Plattform X (ehemals Twitter) und in technischen Blogs bekannt.
- Primärquelle: Die erste Bombe ließ der Tech-Blogger und Insider Pankaj Kumar platzen, der Screenshots und Logs des „Snow Bunny“-Modells in Aktion teilte. Seine Posts beschrieben detailliert die Fähigkeit des Modells, komplexe Engineering-Aufgaben „One-Shot“ zu lösen.
- Benchmark-Validierung: Ein Nutzer namens „Leo“, der den Hieroglyph-Benchmark für laterales Denken pflegt, bestätigte die Leaks. Er veröffentlichte Ergebnisse, die zeigen, dass eine „Snow Bunny“-Variante bei Aufgaben zum lateralen Denken eine Erfolgsquote von 80–88 % erreicht — ein Test, bei dem die meisten Modelle, einschließlich GPT-5.2, Mühe haben, über 55 % hinauszukommen.
- Technische Bestätigung: Zusätzliche Glaubwürdigkeit verliehen Hinweise auf „gemini-for-google-3.5“-Variablen im Backend-Code von Googles API-Diensten, was darauf hindeutet, dass die Infrastruktur für einen öffentlichen Launch bereits steht.
Was unterscheidet 3.5 von 3.0 / 3 Flash?
Basierend auf den Leak-Berichten sind die Hauptunterscheidungsmerkmale:
- Großskalige Codesynthese auf Systemebene: Fähigkeit, globalen Zustand und Architektur über Tausende Zeilen hinweg aufrechtzuerhalten (nicht nur isolierte Funktionsgenerierung).
- Vereinheitlichte multimodale Artefakt-Erzeugung: dieselbe Session produziert Code, Vektorgrafiken und natives Audio in einem einzigen kohärenten Workflow.
- Fein granulierte Reasoning-Steuerung: experimentelle Schalter (z. B. „Deep Think“ / „System2“), um Latenz gegen eine tiefere interne Chain-of-Thought-Suche zu tauschen.
Das klingt eher nach iterativen Engineering-Fortschritten als nach einer radikal anderen Architektur, doch falls dies im großen Maßstab validiert wird, könnte es die Art und Weise verändern, wie Teams Produktartefakte prototypen und ausliefern.
Wie schneiden Funktionen und Leistung im Vergleich ab?
Die geleakten Metriken zeichnen das Bild eines Modells, das deutlich leistungsfähiger und schneller ist als seine Zeitgenossen.
Das 3.000-Zeilen-Coding-Wunder
Die viralste Behauptung aus dem Leak ist die Fähigkeit von Gemini 3.5, 3.000 Zeilen ausführbaren Code aus einem einzigen, hochgradig abstrakten Prompt zu generieren. Das angeführte konkrete Beispiel betraf einen Nutzer, der das Modell bat, einen Nintendo Game Boy-Emulator zu bauen.
In einem Standard-Workflow mit GPT-4 oder Gemini 1.5 würde diese Aufgabe Dutzende Prompts erfordern: die Zerlegung der CPU-Architektur, die Definition der Speicherkarte, die Behandlung des Grafik-Renderings und iteratives Debugging. Gemini 3.5 „Snow Bunny“ soll hingegen die gesamte Codebasis — einschließlich CPU-Befehlssatz, GPU-Emulation und Speicherverwaltung — in einem kontinuierlichen Stream ausgegeben haben und lediglich geringe manuelle Korrekturen benötigt haben, um echte ROMs zu booten.
Performance-Benchmarks: Gemini 3.5 vs GPT-5.2 vs Claude Opus 4.5
| Benchmark | Gemini 3.5 "Snow Bunny" | GPT-5.2 (Schätzung) | Claude Opus 4.5 |
|---|---|---|---|
| Hieroglyph (laterales Denken) | 80% - 88% | 55% | ~50% |
| GPQA Diamond (Wissenschaft auf PhD-Niveau) | >90% | ~85% | ~80% |
| Token-Generierungsgeschwindigkeit | ~218 Tokens/Sek. | ~80 Tokens/Sek. | ~60 Tokens/Sek. |
Die Geschwindigkeit von ~218 Tokens pro Sekunde ist für Wettbewerber besonders alarmierend.
Dass ein Modell mit dieser Reasoning-Tiefe mit einer derart hohen Geschwindigkeit läuft, deutet auf massive Optimierungen in Googles TPU-v6-Infrastruktur oder auf einen Durchbruch in sparsamen Modellarchitekturen hin.
Codebeispiel: Die „One-Shot“-Fähigkeit
Um die Komplexität dessen zu veranschaulichen, was „3.000 Zeilen Code“ bedeuten, bedenken Sie, dass das Modell nicht einfach ein simples Skript schreibt. Es entwirft ein System.
Unten folgt ein konzeptioneller Ausschnitt, wie Gemini 3.5 die Memory Management Unit (MMU) des geleakten Game Boy-Emulators in einem einzigen Durchlauf strukturieren könnte.
Hinweis: Das Folgende ist ein repräsentativer Auszug aus der Art von Low-Level-Logik, die „Snow Bunny“ autonom generiert.
python
class GameBoyMMU:
def __init__(self, bios_path):
self.bios = self.load_bios(bios_path)
self.rom = bytearray(0x8000) # 32k Cartridge
self.vram = bytearray(0x2000) # 8k Video RAM
self.wram = bytearray(0x2000) # 8k Working RAM
self.zram = bytearray(0x80) # Zero-page RAM
self.in_bios = True
def load_bios(self, path):
try:
with open(path, 'rb') as f:
return bytearray(f.read())
except FileNotFoundError:
return bytearray(256)
def read_byte(self, address):
# BIOS Mapping
if self.in_bios and address < 0x0100:
return self.bios[address]
elif address == 0x0100:
self.in_bios = False
# Memory Map Routing
if 0x0000 <= address < 0x8000:
return self.rom[address]
elif 0x8000 <= address < 0xA000:
return self.vram[address - 0x8000]
elif 0xC000 <= address < 0xE000:
return self.wram[address - 0xC000]
elif 0xFF80 <= address < 0xFFFF:
return self.zram[address - 0xFF80]
# ... (Extended handling for I/O registers, Interrupts, Echo RAM)
return 0xFF
def write_byte(self, address, value):
# VRAM Write (Block during rendering modes if necessary)
if 0x8000 <= address < 0xA000:
self.vram[address - 0x8000] = value
# DMA Transfer Trigger
elif address == 0xFF46:
self.dma_transfer(value)
# ... (Complex logic for banking, timer controls, audio registers)
def dma_transfer(self, source_high):
# Direct Memory Access implementation simulating 160ms cycle
source_addr = source_high << 8
for i in range(0xA0):
byte = self.read_byte(source_addr + i)
self.write_byte(0xFE00 + i, byte) # Write to OAM
In einer typischen Interaktion würde ein Nutzer einfach folgenden Prompt geben: „Erstelle einen voll funktionsfähigen Game Boy-Emulator in Python, der BIOS-Laden, Speicher-Mapping und grundlegende CPU-Opcodes handhabt.“ Anschließend generiert Gemini 3.5 die oben stehende Klasse sowie die CPU-Klasse, die PPU (Pixel Processing Unit) und die Haupt-Ausführungsschleife und wahrt dabei die Kohärenz über Tausende Zeilen hinweg.
Wann wird es veröffentlicht?
Obwohl Google kein offizielles Veröffentlichungsdatum bestätigt hat, deutet die Konvergenz der Leaks darauf hin, dass eine Ankündigung unmittelbar bevorsteht.
- Zeitplan: Interne Testvariablen und der „Snow Bunny“-Checkpoint scheinen sich in der Endphase der Validierung zu befinden. Spekulationen deuten auf einen möglichen „Shadow Drop“ oder eine große Enthüllung im Februar 2026 hin, möglicherweise um Wettbewerberveröffentlichungen zuvorzukommen.
- Aktueller Status: Das Modell befindet sich derzeit in einer privaten Beta, zugänglich nur für ausgewählte, vertrauenswürdige Tester und Enterprise-Partner über Vertex AI.
Wie sehen Preise und Kosten aus?
Die Preisgestaltung bleibt einer der aggressivsten Aspekte der Gemini-Strategie. Gerüchte deuten darauf hin, dass Google den Markt deutlich unterbieten will und dabei von seiner vertikalen Integration von Hardware (TPUs) und Software profitiert.
- Gemini 3.5 Flash: Geleakte Preise deuten auf ungefähr $0.50 pro 1 Million Eingabe-Token hin. Das ist ungefähr 70 % günstiger als vergleichbare „smarte“ Modelle von Wettbewerbern.
- Gemini 3.5 Pro/Ultra: Die Preise werden voraussichtlich wettbewerbsfähig sein und könnten ein gestuftes Abomodell für „Deep Think“-Fähigkeiten einführen.
- Deep Think Surcharge: Es wird spekuliert, dass der „System 2“-Reasoning-Modus pro Token teurer sein könnte, da das Modell vor der Antwort zusätzliche Rechenzeit zum „Nachdenken“ benötigt.
Fazit
Wenn sich die „Snow Bunny“-Leaks bewahrheiten, ist Google Gemini 3.5 nicht nur ein inkrementelles Update; es ist eine kraftvolle Machtdemonstration. Durch die Lösung des „Lazy Coding“-Problems und die Ermöglichung massiver, kohärenter Codegenerierung könnte Google kurz davor stehen, Entwickler von Code-Schreibern zu Systemarchitekten zu transformieren. Während wir auf die offizielle Keynote warten, ist eines klar: Das KI-Wettrüsten hat gerade auf Hyperschallgeschwindigkeit beschleunigt.
Entwickler können auf Gemini 3 Flash und Gemini 3 Pro CometAPI zugreifen, die neuesten Modelle sind mit Stand zum Veröffentlichungsdatum des Artikels gelistet. Für den Einstieg erkunden Sie die Fähigkeiten des Modells im Playground und konsultieren Sie den API-Leitfaden für detaillierte Anweisungen. Bevor Sie zugreifen, stellen Sie bitte sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen Preis, der deutlich unter dem offiziellen liegt, um Ihnen die Integration zu erleichtern.
Bereit?→ Registrieren Sie sich noch heute für Gemini 3 !
Wenn Sie mehr Tipps, Leitfäden und Nachrichten zu KI erfahren möchten, folgen Sie uns auf VK, X und Discord!